浅谈LCA的离线算法
2016-07-20 14:55
211 查看
在线算法与离线算法的定义
在计算机科学中,一个在线算法是指它可以以序列化的方式一个个的处理输入,也就是说在开始时并不需要已经知道所有的输入。相对的,对于一个离线算法,在开始时就需要知道问题的所有输入数据,而且在解决一个问题后就要立即输出结果。例如,选择排序在排序前就需要知道所有待排序元素,然而插入排序就不必。因为在线算法并不知道整个的输入,所以它被迫做出的选择最后可能会被证明不是最优的,对在线算法的研究主要集中在当前环境下怎么做出选择。对相同问题的在线算法和离线算法的对比分析形成了以上观点。如果想从其他角度了解在线算法可以看一下
流算法(关注精确呈现过去的输入所使用的内存的量),动态算法(关注维护一个在线输入的结果所需要的时间复杂度)和在线机器学习。
那么LCA的离线tarjan算法是什么呢,众所周知,tarjan算法基本就是一个dfs,那么这个也是用一个dfs来完成的,那思想是什么呢?
首先先用把要求的值存下来,就是所谓的离线一下, 然后dfs什么呢,就是先判断有没有再query里的,如果在query里并且那个已经被处理过了,并且他们的公共祖先没有被标记掉,那么就可以求这两个点之间的距离了。
接下来就是各种把他的未标记节点dfs一遍
然后就求出答案了
步骤:
tarjan算法的步骤是(当dfs到节点u时):
1 在并查集中建立仅有u的集合,设置该集合的祖先为u
1 对u的每个孩子v:
1.1 tarjan之
1.2 合并v到父节点u的集合,确保集合的祖先是u
2 设置u为已遍历
3 处理关于u的查询,若查询(u,v)中的v已遍历过,则LCA(u,v)=v所在的集合的祖先
贴图解释一下
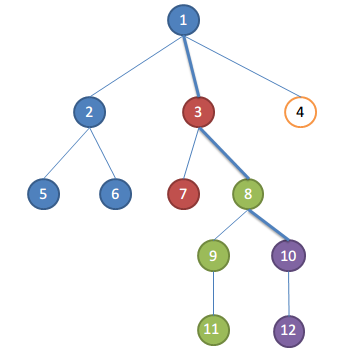
如图:前面处理的时候能把每一个每一个颜色的处理为一个集合,并且用并查集随着先后顺序也会发现lca再不断的变化,并且不会错,这是为什么呢,这就是奇妙的dfs
因为他的查询和处理是同步的,所以他是不会错的
比如查询5 6
那么可以知道,现在5,6的祖先是2,并且findset(6)为2,
查询 2 8
那么2 ,8的lca就是1
因为是先处理的2,所以再8的地方2已经被处理过了,所以现在findset(2)=1;
代码如下:
void dfs (int u)
{
// printf("%d\n",u);
for (int i = 0; i < query[u].size(); i++)
{
int v = query[u][i].to;
if (vis[v] && ans[query[u][i].w] == -1 && !mark[findset (v)]) //表示的是这个点是集合的祖先,如果他们的不属于一个集合,那么肯定不能更新,如果是一个集合的话,就不用标记了</span>
{
ans[query[u][i].w] = dis[u] + dis[v] - 2 * dis[findset (v)];
//printf("lca(%d->%d):%d\n",u,v,findset(v));
}
}
for (int i = 0; i < mp[u].size(); i++)
{
int v = mp[u][i].to;
if (!vis[v])
{
vis[v] = 1;
dis[v] = dis[u] + mp[u][i].w;
dfs (v);
par[v] = u;
}
}
}下面贴hdu 2874的代码,助理解
#include <cstdio>
#include <cstring>
#include <algorithm>
#include <vector>
using namespace std;
#define N 10010
#define M 1000010
struct node
{
int to, w;
node (int a = 0, int b = 0)
{
to = a, w = b;
}
};
int ans[M];
int par
, vis
, mark
, dis
;
int n, m, k;
vector<node>mp
;
vector<node>query
;
void init()
{
for (int i = 0; i <= n; i++)
{
mp[i].clear();
query[i].clear();
vis[i] = mark[i] = 0;
par[i] = i;
}
memset (ans, -1, sizeof (ans) );
}
int findset (int x)
{
if (x != par[x]) par[x] = findset (par[x]);
return par[x];
}
void dfs (int u)
{
// printf("%d\n",u);
for (int i = 0; i < query[u].size(); i++)
{
int v = query[u][i].to;
if (vis[v] && ans[query[u][i].w] == -1 && !mark[findset (v)])
{
ans[query[u][i].w] = dis[u] + dis[v] - 2 * dis[findset (v)];
//printf("lca(%d->%d):%d\n",u,v,findset(v));
}
}
for (int i = 0; i < mp[u].size(); i++)
{
int v = mp[u][i].to;
if (!vis[v])
{
vis[v] = 1;
dis[v] = dis[u] + mp[u][i].w;
dfs (v);
par[v] = u;
}
}
}
int main()
{
while (~scanf ("%d%d%d", &n, &m, &k) )
{
init();
int x, y, z;
for (int i = 0; i < m; i++)
{
scanf ("%d%d%d", &x, &y, &z);
mp[x].push_back (node (y, z) );
mp[y].push_back (node (x, z) );
}
for (int i = 1; i <= k; i++)
{
scanf ("%d%d", &x, &y);
query[x].push_back (node (y, i) );
query[y].push_back (node (x, i) );
}
for (int i = 1; i <= n; i++)
{
if (!vis[i])
{
vis[i] = 1;
dis[i] = 0;
dfs (i);
mark[i] = 1;
}
}
for (int i = 1; i <= k; i++)
{
if (ans[i] != -1) printf ("%d\n", ans[i]);
else printf ("Not connected\n");
}
}
return 0;
}版权声明:都是兄弟,请随意转载,请注明兄弟是谁(http://blog.csdn.net/u013076044)转自:http://blog.csdn.net/u013076044/article/details/41875009

相关文章推荐
- 书评:《算法之美( Algorithms to Live By )》
- 动易2006序列号破解算法公布
- C#递归算法之分而治之策略
- Ruby实现的矩阵连乘算法
- C#插入法排序算法实例分析
- C#算法之大牛生小牛的问题高效解决方法
- C#算法函数:获取一个字符串中的最大长度的数字
- 超大数据量存储常用数据库分表分库算法总结
- C#数据结构与算法揭秘二
- C#冒泡法排序算法实例分析
- 算法练习之从String.indexOf的模拟实现开始
- C#算法之关于大牛生小牛的问题
- C#实现的算24点游戏算法实例分析
- 经典排序算法之冒泡排序(Bubble sort)代码
- c语言实现的带通配符匹配算法
- 浅析STL中的常用算法
- 算法之排列算法与组合算法详解
- C++实现一维向量旋转算法
- Ruby实现的合并排序算法
- C#折半插入排序算法实现方法