操作系统之存储器管理
2016-07-17 13:16
323 查看
存储器的层次结构
存储器的层次如下图: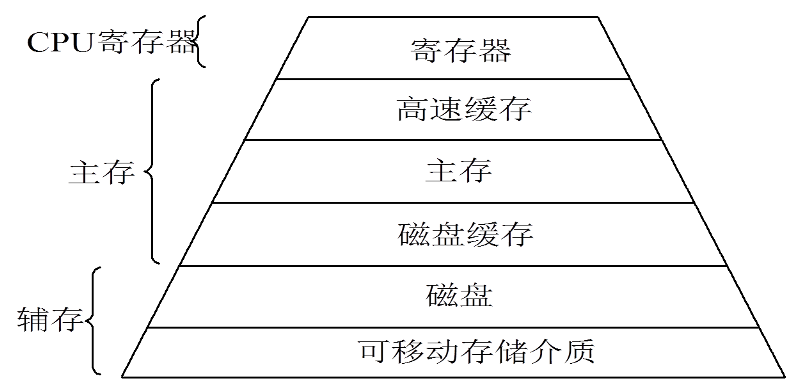
上图中,寄存器和主存储器称为可执行存储器。高速缓存的作用是缓和CPU与内存之间的速度差异,主要由硬件实现。磁盘缓存的出现是由于内存容量不够,需要引入磁盘,然而磁盘的I/O速度远低于主存的访问速度,为了缓和两者之间在速度上的差异,设置了磁盘缓存。磁盘缓存与高速缓存不同,它本身并不是实际存在的存储器,是利用主存中的部分空间暂时存放从磁盘中读出写入的信息。
程序的装入与链接
用户程序需要运行,必须先将它装入内存,然后再将其转变为一个可以执行的程序,通常要经历一下几个步骤:编译:由编译程序对用户源程序进行编译,形成若干个目标模块。
链接:有链接程序将编译后形成的一组目标模块以及他们所需要的库函数链接在一起,形成一个完整的装入模块。
装入:由装入程序将装入模块装入内存。具体过程如下图:
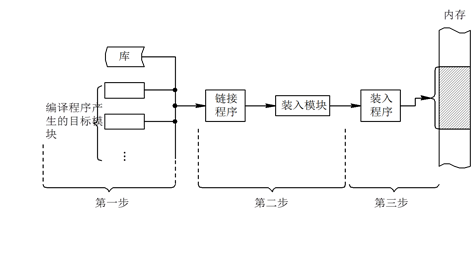
1. 程序的装入
[b]1) 地址空间[/b]程序编译时还没有装入主存,还不能确定它在主存中的实际位置,所以都是从0开始。
相对于0位置开始的地址称为逻辑地址,也称为相对地址。地址空间是指逻辑地址的集合。
[b]2) 存储空间[/b]
一个程序在主存中的实际位置称为物理地址。物理地址的集合就是存储空间。
程序的装入有三种方式:
[b]1) 绝对装入方式[/b]
在编译时,如果知道程序将驻留在内存的什么位置,那么,编译程序将产生绝对地址的目标代码。绝对装入程序按照装入模块中的地址,将程序和数据装入内存。
装入模块被装入内存后,由于程序中的逻辑地址与实际内存中的地址完全相同,故不需对程序和数据的地址进行修改。
[b]2) 可重定位装入方式[/b]
地址变换是在装入时一次完成的,以后不再改变(静态重定位)。
[b]3) 动态运行时的装入方式[/b]
把装入模块装入内存后,并不立即把装入模块中的相对地址转换为绝对地址,而是把这种地址转换推迟到程序真正要执行时才进行。
因此, 装入内存后的所有地址都仍是相对地址。
连续分配存储管理方式
1) 单一连续分配
把内存分为系统区和用户区两部分,系统区提供给OS使用,通常放在低地址部分,而在用户区,仅装有一道用户程序,即整个内存的用户空间由该程序独占 。只能用于单用户、单任务的操作系统中。
2) 固定分区分配
把内存的用户空间划分为若干个固定大小的区域,在每个分区中只装入一道作业。最简单的运行多道程序的存储管理方式。
3) 动态分区分配
事先不划定分区的大小,根据进程的大小动态为整个进程分配一个连续的内存空间。[b](1) 基于顺序搜索的动态分区算法[/b]
首次适应算法(FF):
空闲分区按地址递增的次序链接。
从链首找第一个满足大小的分区。
划出需要的内存,剩下的仍留在空闲链中。
优点:保留了高址部分的大空闲区。
缺点:低址部分会留下许多碎片。
循环首次适应算法(NF):
从上次找到的空闲分区的下一个分区开始找,直至找到第一个满足大小的分区。
划出需要的内存,剩下的仍留在空闲链中。
优点:使空闲分区分布得较均匀。
缺点:缺乏大的空闲分区。
最佳适应算法(BF):
把空闲分区按容量从小到大排序。
把满足要求且最小的空闲分区分配为作业。
优点:可以避免“大材小用”。
缺点:会留下许多碎片。
最坏适应算法(WF)
把空闲分区按容量从大到小排序。
查找时只要看第一个分区能否满足作业要求。
优点:剩下的空闲区不至于太小。
缺点:会使存储器中缺乏大的空闲分区。
[b](2) 基于索引搜索的动态分区算法[/b]
快速适应算法:
又称为分类搜索法,将空闲分区根据容量大小进行分类,对于每一类具有相同容量的所有空闲分区,单独设立一个空闲分区链表。
在内存中设立一张管理索引表,每一个表项对应了一种空闲分区类型,并记录了空闲分区链表表头的指针。
空闲分区的分类是根据进程常用的空间大小进行划分,如2 KB、4 KB、8 KB等,对于其它大小的分区,如7 KB这样的空闲区,既可以放在8 KB的链表中,也可以放在一个特殊的空闲区链表中。
优点:查找效率高,不会产生碎片。
缺点:分区归还主存算法复杂,系统开销大。
伙伴系统:
Linux对内存空闲空间的管理采用伙伴(Buddy)算法。
Buddy算法是把内存中的所有页帧按照2n划分,其中n=0~9。对内存空间按1个页帧、2个页帧、4个页帧、8个页帧、16个页帧、32个页帧、 …、512个页帧进行划分。 划分后形成了大小不等的存储块,称为页帧块,简称页块。包含1个页帧的页块称为1页块,包含2个页帧的称为2页块,依此类推。Linux把物理内存划分成了1、2、4、8、…、512六种页块。
假设要求分配的块其大小为128个页面(由多个页面组成的块我们就叫做页面块)。该算法先在块大小为128个页面的链表中查找,看是否有这样一个空闲块。如果有,就直接分配;如果没有,该算法会查找下一个更大的块,具体地说,就是在块大小为256个页面的链表中查找一个空闲块。如果存在这样的空闲块,内核就把这256个页面分为两等份,一份分配出去,另一份插入到块大小为128个页面的链表中。如果在块大小为256个页面的链表中也没有找到空闲页块,就继续找更大的块,即512个页面的块。如果存在这样的块,内核就从512个页面的块中分出128个页面满足请求,然后从384个页面中取出256个页面插入到块大小为256个页面的链表中。然后把剩余的128个页面插入到块大小为128个页面的链表中。如果512个页面的链表中还没有空闲块,该算法就放弃分配,并发出出错信号。
满足以下条件的两个块称为伙伴:
两个块的大小相同
两个块的物理地址连续
哈希算法:
哈希算法构造一张以空闲分区大小为关键字的哈希表,该表的每一个表项记录了一个对应的空闲分区链表表头指针。
当进行空闲分区分配时,根据所需空闲分区大小,通过哈希函数计算,即得到在哈希表中的位置,从中得到相应的空闲分区链表,实现最佳分配策略。
4) 动态可重定位分区分配
重定位:就是将逻辑地址转换为物理地址。静态重定位:在程序被加载到内存之前已经知道了它将要加载到内存的开始地址,这样就可以事先进行地址转换,把相对地址转换成绝对地址。
动态重定位:作业装入内存后所有的地址仍然是相对地址,将相对地址转换成绝对地址的过程被推迟到程序指令要真正执行时进行。
[b](1) 紧凑[/b]
“紧凑”而使程序移动时,只需用新的起始地址置换原来的起始地址。
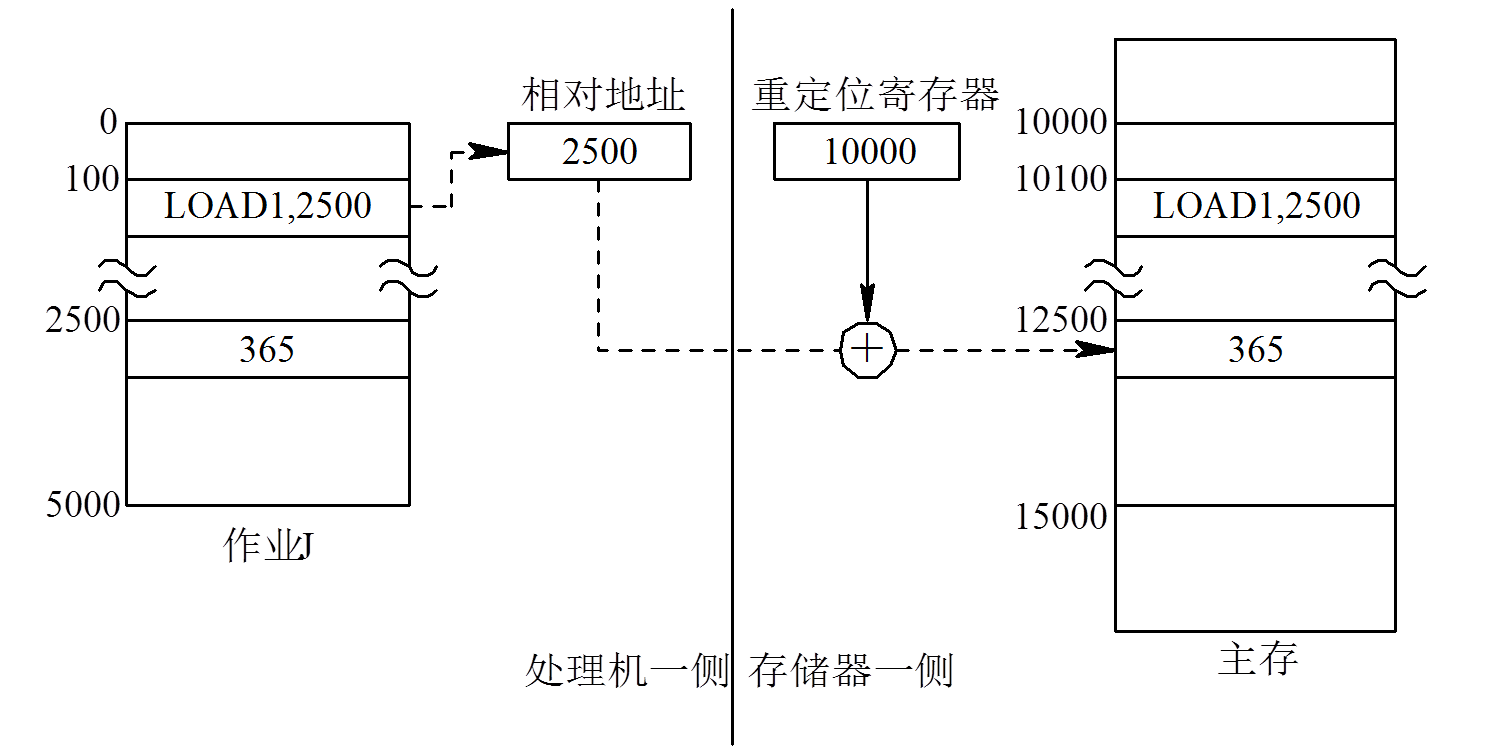
[b](2) 动态重定位[/b]
重定位寄存器,用它来存放程序数据在内存中的起始地址。
系统对内存进行了紧凑之后,不需要对程序做任何的修改,只需要用该程序在内存中的新起始地址去置换原来的起始地址即可。
动态重定位如下:
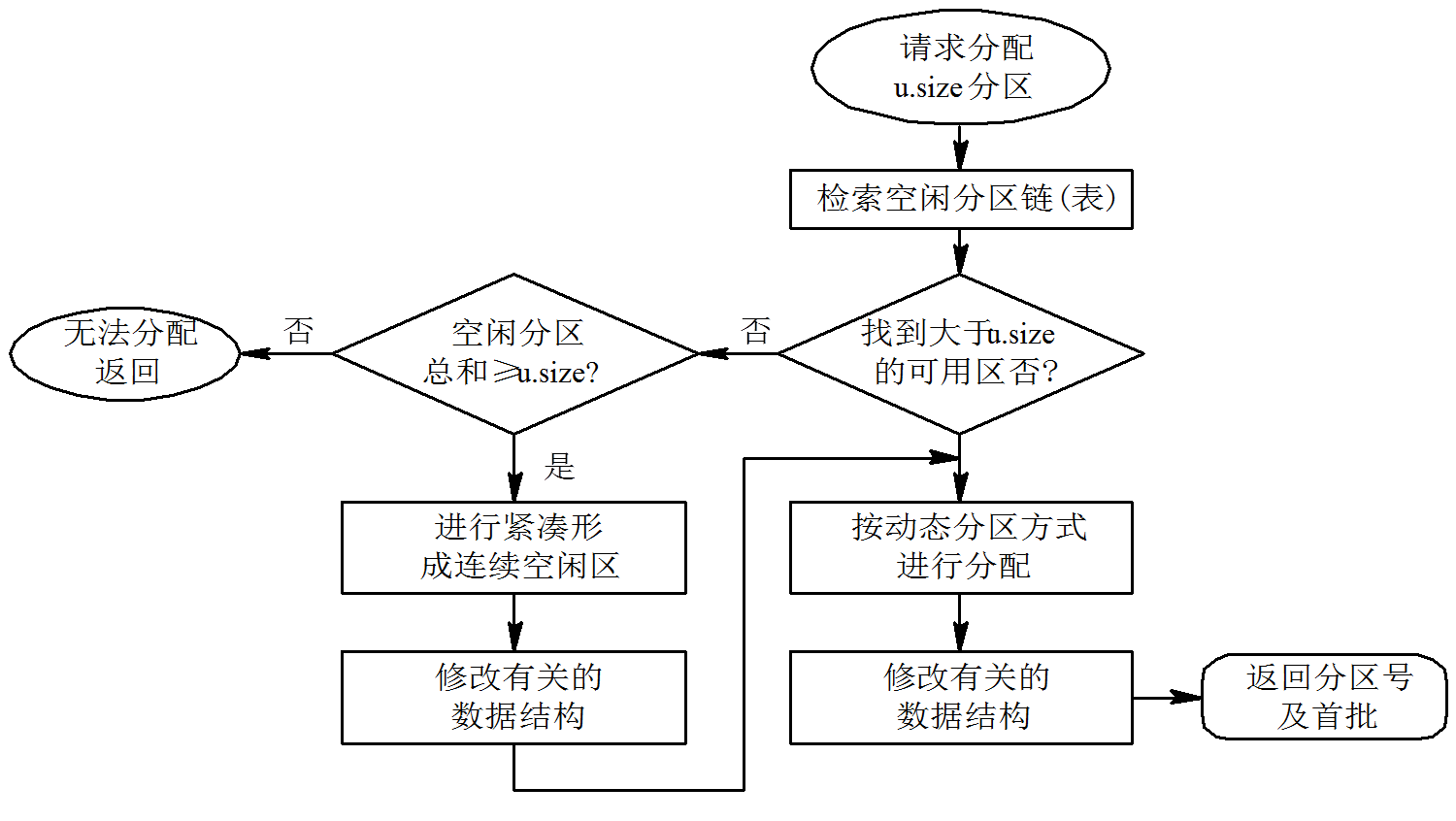
[b](2) 动态重定位分区的算法[/b]
在动态分区分配算法的基础上增加了“紧凑”的功能,流程图如下:
离散分配内存管理方式
连续分配方式会形成许多“碎片”,虽然通过紧凑可以将许多碎片连接成可用的大块空间,但是紧凑的代价太大。将一个进程直接分散的装入到许多不相邻的分区中,便可充分利用内存空间。1) 分页存储管理方式
将用户程序的地址空间分成若干个固定大小的区域,称为页或页面。具体的页的大小有系统规定,相应的,也将内存空间分为若干个物理块或页框,页和块的大小相同。这样可将用户程序的任一页放入任一物理块中,实现离散分配。页面。在为进程分配内存时,以块为单位将进程中的若干个页分别装入到多个可以不相邻接的物理块中。由于进程的最后一页经常装不满一块而形成了不可利用的碎片,称之为“页内碎片”。
逻辑地址结构如下图:
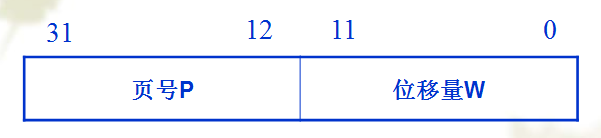
页表。通常存放在内存中,页表的作用是实现页号到物理块号的地址映射。
[b](1) 基本的地址变换机构[/b]
在系统中设置一个页表寄存器,其中存放页表在内存的起始地址和页表的长度。进程为执行时,页表的起始地址和页表的长度存放于进程的PCB中。当调度程序调度到某进程时,才将这两个数据装入页表寄存器中。
需要访问两次内存,一次获取物理块号得到物理地址,第二次根据物理地址获得所需数据。
地址变换机构如下:
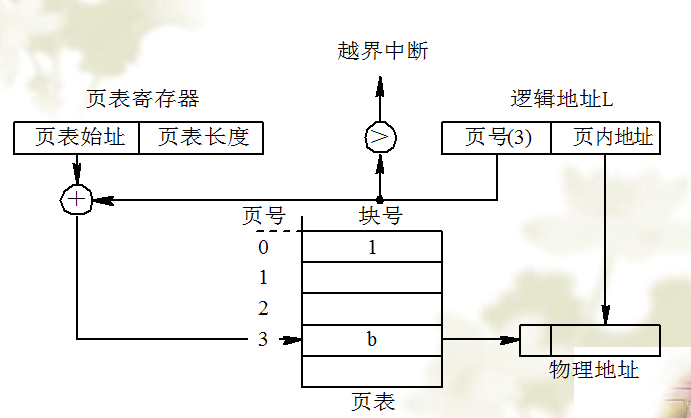
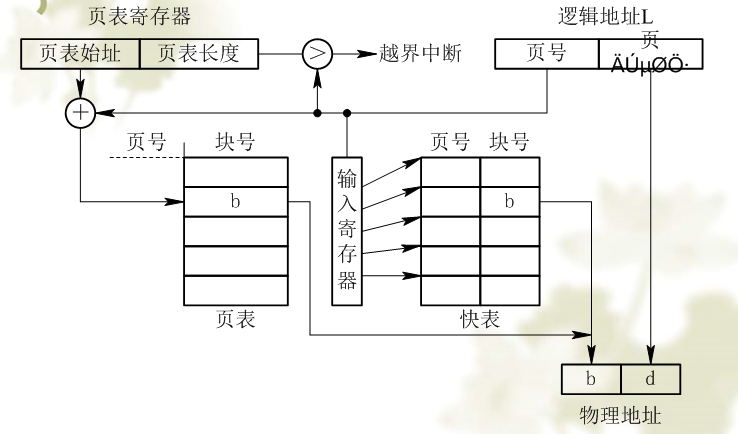
[b](2) 具有快表的地址变换机构[/b]
每次都要访问两次内存速度太慢,为提高地址变换速度,增添一个高速缓冲寄存器,又称快表。
CPU给出有效地址后,有地址变换机构自动的将页号P送入高速缓冲寄存器,并将此页号与快表中的所有页号进行比较。
变换机构如下:
2) 分段存储管理方式
分页存储是为了提高内存利用率。分段存储则是为了满足用户在编程和使用上多方面的要求。方便编程,信息共享,信息保护,动态增长,动态链接。
分段:每个段定义了一组逻辑信息。
分段地址具有以下的逻辑结构:

[b](1) 地址转换机构[/b]
地址变换机构:
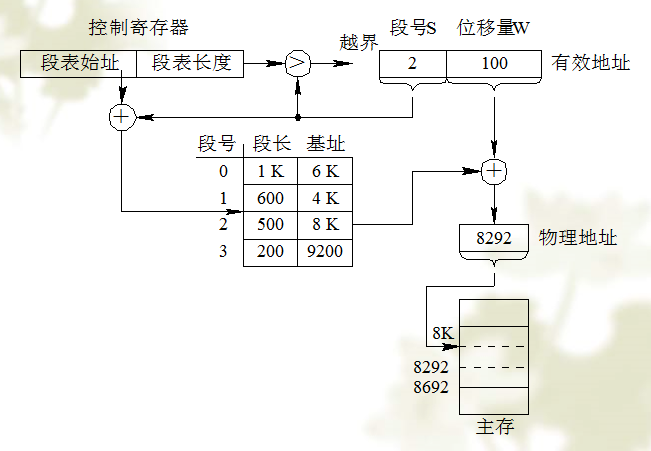
要访问两次内存。
[b](2) 分页和分段的主要区别[/b]
页是信息的物理单位,段则是信息的逻辑单位。分页是为消减内存的外零头,提高内存的利用率,是系统管理的需要。分段的目的是为了能更好地满足用户的需要。
页的大小固定且由系统决定,而段的长度却不固定,决定于用户所编写的程序。
分页的作业地址空间是一维的,而分段的作业地址空间则是二维的(段号+段基址)。
3) 段页存储管理方式
是分段和分页的结合:先将用户程序分成若干个段,再把段分成若干个页。作业逻辑地址结构如下:

地址变换过程:
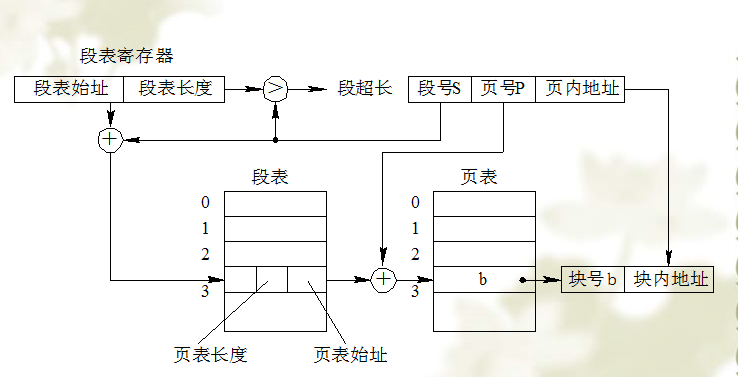
需要访问三次内存。

相关文章推荐
- CANoe CAPL语言Step2
- 软件总体测试计划
- 滨州学院CSDN高校俱乐部第二届线下编程比赛
- 部署exchange2010三合一:之五:创建发送连接器
- Codeforces Round #238 (Div. 2) D. Toy Sum 暴搜
- Servlet生命周期与工作原理
- 导入三方库是出现NotFount
- FatMouse' Trade
- 进程间通信---管道
- discuzx2后台自带备份功能问题
- Github 创建新分支
- 使用Gradle管理你的Android Studio工程
- 利用VSPD、串口调试助手、Keil做串口调试
- SHGetDesktopFolder编程应用
- Hibernate 简单使用(五)多对多关联映射
- PyCharm汉化版+去掉代码下波浪线
- CSS3选择器详解实例说明
- 部署exchange2010三合一:之五:功能测试
- 大数据学习资源汇总
- JS简单实现括号匹配问题