相似度算法之皮尔逊相关系数
2016-07-16 15:45
330 查看
皮尔逊相关系数是比欧几里德距离更加复杂的可以判断人们兴趣的相似度的一种方法。该相关系数是判断两组数据与某一直线拟合程序的一种试题。它在数据不是很规范的时候,会倾向于给出更好的结果。
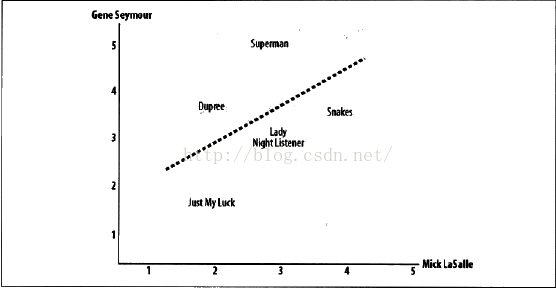
如图,Mick Lasalle为<<Superman>>评了3分,而GeneSeyour则评了5分,所以该影片被定位中图中的(3,5)处。在图中还可以看到一条直线。其绘制原则是尽可能地靠近图上的所有坐标点,被称为最佳拟合线。如果两位评论者对所有影片的评分情况都相同,那么这条直线将成为对角线,并且会与图上所有的坐标点都相交,从而得到一个结果为1的理想相关度评价。
假设有两个变量X(x1,x2,x3,……)、Y(y1,y2,y3,……),那么两变量间的皮尔逊相关系数可通过以下公式计算:
公式一:

皮尔逊相关系数计算公式
公式二:

皮尔逊相关系数计算公式
公式三:

皮尔逊相关系数计算公式
公式四:

皮尔逊相关系数计算公式
以上列出的四个公式等价,其中E是数学期望,cov表示协方差,N表示变量取值的个数。
皮尔逊相关度评价算法首先会找出两位评论者都曾评论过的物品,然后计算两者的评分总和与平方和,并求得评分的乘积之各。利用上面的公式四计算出皮尔逊相关系数。
在实践统计中,一般只输出两个系数,一个是相关系数,也就是计算出来的相关系数大小,在-1到1之间;另一个是独立样本检验系数,用来检验样本一致性.
根据皮尔逊相关系数的值参考以下标准,可以大概评估出两者的相似程度:
0.8-1.0 极强相关
0.6-0.8 强相关
0.4-0.6 中等程度相关
0.2-0.4 弱相关
0.0-0.2 极弱相关或无相关
当然,在使用过程中该算法也不使用所有的场景,需要变量X,Y满足以下几个约束条件:
1 两个变量间有线性关系
2 变量是连续变量
3 变量均符合正态分布,且二元分布也符合正态分布
4 两变量独立
算法实现如下:
注:本文很大一部分内容转自:http://lobert.iteye.com/blog/2024999,因为这位仁兄总结的确实很好。本文后续部分略作补充,谨作抛砖引玉之用。
如图,Mick Lasalle为<<Superman>>评了3分,而GeneSeyour则评了5分,所以该影片被定位中图中的(3,5)处。在图中还可以看到一条直线。其绘制原则是尽可能地靠近图上的所有坐标点,被称为最佳拟合线。如果两位评论者对所有影片的评分情况都相同,那么这条直线将成为对角线,并且会与图上所有的坐标点都相交,从而得到一个结果为1的理想相关度评价。
假设有两个变量X(x1,x2,x3,……)、Y(y1,y2,y3,……),那么两变量间的皮尔逊相关系数可通过以下公式计算:
公式一:
皮尔逊相关系数计算公式
公式二:
皮尔逊相关系数计算公式
公式三:
皮尔逊相关系数计算公式
公式四:
皮尔逊相关系数计算公式
以上列出的四个公式等价,其中E是数学期望,cov表示协方差,N表示变量取值的个数。
皮尔逊相关度评价算法首先会找出两位评论者都曾评论过的物品,然后计算两者的评分总和与平方和,并求得评分的乘积之各。利用上面的公式四计算出皮尔逊相关系数。
在实践统计中,一般只输出两个系数,一个是相关系数,也就是计算出来的相关系数大小,在-1到1之间;另一个是独立样本检验系数,用来检验样本一致性.
根据皮尔逊相关系数的值参考以下标准,可以大概评估出两者的相似程度:
0.8-1.0 极强相关
0.6-0.8 强相关
0.4-0.6 中等程度相关
0.2-0.4 弱相关
0.0-0.2 极弱相关或无相关
当然,在使用过程中该算法也不使用所有的场景,需要变量X,Y满足以下几个约束条件:
1 两个变量间有线性关系
2 变量是连续变量
3 变量均符合正态分布,且二元分布也符合正态分布
4 两变量独立
算法实现如下:
#皮尔逊相似度算法 def PearsonSimilarity(UL,p1,p2): si = GetSameItem(UL,p1,p2) n = len(si) if n == 0: return 0 sum1 = sum([UL[p1][item] for item in si]) sum2 = sum([UL[p2][item] for item in si]) sqSum1 = sum([pow(UL[p1][item],2) for item in si]) sqSum2 = sum([pow(UL[p2][item],2) for item in si]) pSum = sum([UL[p1][item]*UL[p2][item] for item in si]) num = pSum - (sum1*sum2/n) den = math.sqrt(sqSum1-pow(sum1,2)/n)*math.sqrt(sqSum2-pow(sum2,2)/n) if den ==0: return 0 r = num/den return r
注:本文很大一部分内容转自:http://lobert.iteye.com/blog/2024999,因为这位仁兄总结的确实很好。本文后续部分略作补充,谨作抛砖引玉之用。

相关文章推荐
- mahout基于用户推荐的简单例子(2)
- mahout+eclipse推荐系统开发学习之helloworld
- 数据推荐系统系列 8种方法之一 CosSim余弦相识性方式
- 数据推荐系统系列 8种方法之一 User-CF 方式
- 不到100行代码实现一个简单的推荐系统
- 基于内容的推荐Content-based Recommendation
- 相似性度量--Pearson相关系数
- 推荐引擎算法 - 猜你喜欢的东西
- 长期招聘:个性化推荐
- 《推荐系统实践》 阅读笔记
- 推荐系统学习笔记(一)
- 推荐系统学习笔记(三)
- 计算字符串相似度算法 Levenshtein
- mahout之推荐系统源码笔记(2) ---相似度计算之RowSimilarityJob
- mahout之推荐系统源码笔记(3) ---执行推荐之RecommenderJob
- guide2datamining阅读笔记(1)
- 基于语义依存关系的相似度算法简述
- 美团推荐算法实践:机器学习重排序模型成亮点
- 数据挖掘之曼哈顿距离、欧几里距离、明氏距离、皮尔逊相关系数、余弦相似度Python实现代码
- 推荐系统——基本概念