二项分布算法(递归)
2016-07-15 23:38
162 查看
关于用递归实现的二项分布算法
最近在看Sedgewick的《算法》的时候有一题习题是关于改进用递归实现的二项分布算法。这里我令服从二项分布为$X\sim b(N,k,p)$,书本上习题给出的算法是:
public static double binomial(int N, int k, double p)
{
if( N == 0 && k == 0 )
return 1.0;
if( N < 0 || k < 0 )
return 0.0;
return (1-p)*binomial(N-1,k,p)+p*binomial(N-1,k-1,p);
}我们可能刚开始看这个递归算法的时候会不太明白(当时我都看懵逼了),那我们就从小一点的值来分析一下,假如N=2, k=1, p=0.5,即b(2, 1, 0.5)。那么我们按照这个算法来分析一下接下来的递归过程:
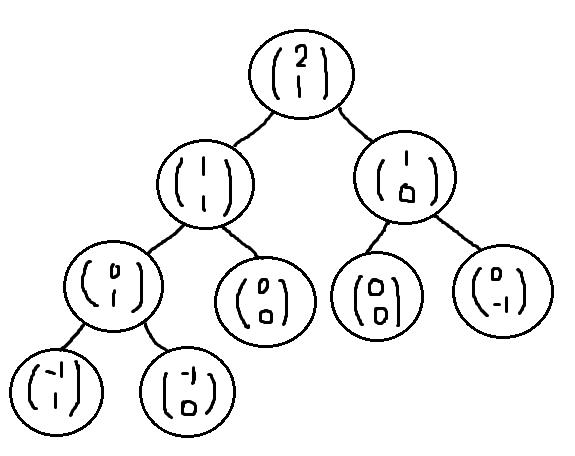
我们可以看到每一次都可以分开两部分然后再继续递归,直到出现N=0 ,k=0,可能刚会不太明白为什么这个算法可以算出二项分布,如果我们看一下我们的概率统计相关的书就可以知道有这样一条递归公式:
(Nk)pk(1−p)N−k=(1−p)(N−1k)pk(1−p)N−1−k+p(N−1k−1)pk−1(1−p)N
你就会懂为什么有这个递推算法了,而且上面的公式本质上其实是组合递推公式:
(Nk)=(N−1k)+(N−1k−1)
那么我们搞懂了这个算法之后,我们会发现这个算法在N很大的时候会发生递归层数很深,从我们上面这幅图也可以看出来,每一个递归又会产生两个递归,所以假设b(100, 50, 0.25)的情况下函数将被递归调用大约在2.252∗1015∼1.267∗1030数量相当的庞大,反正我用这个算法运行的时候压根就等不到运算结果。
所以后来就改了一下算法,改用大量循环,不用递归实现。
//计算组合数
public static double zuhe(double N, double k)
{
//模拟人类计算的约分过程从而减少阶乘数量
double m = N-k;
double min = k;
double max = m;
double t = 0;
double NN=1;
double kk=1;
if(min>max)
{
t=min;
min = max;
max=t;
}
//把大的阶乘约分去掉
while(N>max)
{
NN=NN*N;
N--;
}
//计算小的阶乘
while(min>0)
{
kk=kk*min;
min--;
}
//算出组合数
return NN/kk;
}
//计算二项分布值
public static double binomial(int N,int k,double p)
{
double y=1;
double s=1;
//计算组合数
double a =binomial(N,k);
//计算(1-p)的(N-k)次方
while((N-k)>0)
{
s=s*(1-p);
N--;
}
//计算p的k次方
while(k>0)
{
y=y*p;
k--;
}
//最后三个值相乘得出二项分布值
return a*y*s;
}
}经过去掉递归后的算法就能很快的算出N值比较大的情况下的二项分布值。
如果你们还有更好的算法,可以告诉我,大家交流一下学习一下。

相关文章推荐
- 肯特·贝克:改变人生的代码整理魔法
- 你应该学习哪种编程语言?
- [转]我们需要一种其他人能使用的编程语言
- 书评:《算法之美( Algorithms to Live By )》
- DB2编程序技巧(1)
- DB2编程序技巧 (四)
- 女人VS编程_国庆快乐
- DB2编程序技巧 (六)
- DB2编程序技巧 (三)
- DB2编程序技巧 (九)
- DB2编程序技巧 (七)
- DB2编程序小小技巧
- DB2编程序技巧 (五)
- 动易2006序列号破解算法公布
- DB2编程序技巧 (一)
- DB2编程序技巧 (八)
- DB2编程序技巧 (十)
- VBS基础编程教程 (第1篇)
- VBS基础编程教程 (第3篇)
- C#递归算法之分而治之策略