决策树算法(三)——计算香农熵
2016-07-15 18:20
323 查看
写在前面的话
如果您有任何地方看不懂的,那一定是我写的不好,请您告诉我,我会争取写的更加简单易懂!如果您有任何地方看着不爽,请您尽情的喷,使劲的喷,不要命的喷,您的槽点就是帮助我要进步的地方!
计算给定数据的信息熵
在决策树算法中最重要的目的我们已经在前几章说过了,就是根据信息论的方法找到最合适的特征来划分数据集。在这里,我们首先要计算所有类别的所有可能值的香农熵,根据香农熵来我们按照取最大信息增益(information gain)的方法划分我们的数据集。我们的数据集如下表所示:

根据这张表,我们使用python来构建我们的数据集。
#!/usr/bin/env python # coding=utf-8 # author: chicho # running: python trees.py # filename : trees.py def createDataSet(): dataSet = [[1,1,'yes'], [1,1,'yes'], [1,0,'no'], [0,1,'no'], [0,1,'no']] # 我们定义了一个list来表示我们的数据集,这里的数据对应的是上表中的数据 labels = ['no surfacing','flippers'] return dataSet, labels
其中第一列的1表示的是不需要浮出水面就可以生存的,0则表示相反。 第二列同样是1表示有脚蹼,0表示的是没有。
在构建完数据集之后我们需要计算数据集的香农熵。
根据香农熵的定义可以知道:
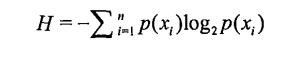
根据这个公式我们来编写相应的代码。(注意:我们是计算每个类别的香农熵,也就是鱼类还是非鱼类的香农熵。在这我们的数据集当中我们用’yes’表示是鱼类,用‘no’表示非鱼类)
# 代码功能:计算香农熵
from math import log #我们要用到对数函数,所以我们需要引入math模块中定义好的log函数(对数函数)
def calcShannonEnt(dataSet):#传入数据集
# 在这里dataSet是一个链表形式的的数据集
countDataSet = len(dataSet) # 我们计算出这个数据集中的数据个数,在这里我们的值是5个数据集
labelCounts={} # 构建字典,用键值对的关系我们表示出 我们数据集中的类别还有对应的关系
for featVec in dataSet: 通过for循环,我们每次取出一个数据集,如featVec=[1,1,'yes']
currentLabel=featVec[-1] # 取出最后一列 也就是类别的那一类,比如说‘yes’或者是‘no’
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
print labelCounts # 最后得到的结果是 {'yes': 2, 'no': 3}
shannonEnt = 0.0 # 计算香农熵, 根据公式
for key in labelCounts:
prob = float(labelCounts[key])/countDataSet
shannonEnt -= prob * log(prob,2)
return shannonEnt在python中我们使用 a=[]来定义一格list,我们使用a={}来定义一个字典。
例如:
website = {1:”google”,”second”:”baidu”,3:”facebook”,”twitter”:4}
>>>#用d.keys()的方法得到dict的所有键,结果是list >>> website.keys() [1, 'second', 3, 'twitter']
注意是d.keys()
>>>#用d.values()的方法得到dict的所有值,如果里面没有嵌套别的dict,结果是list
>>> website.values()
['google', 'baidu', 'facebook', 4]
>>>#用items()的方法得到了一组一组的键值对,
>>>#结果是list,只不过list里面的元素是元组
>>> website.items()
[(1, 'google'), ('second', 'baidu'), (3, 'facebook'), ('twitter', 4)]接下来我们来测试一下,通过 reload来测试
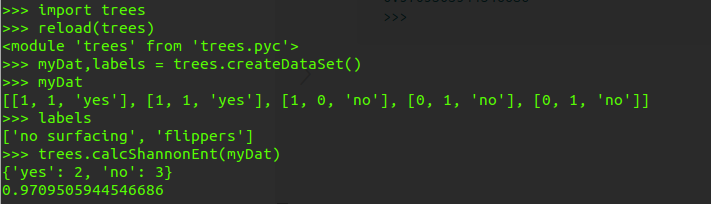
>>> import trees
>>> reload(trees)
<module 'trees' from 'trees.pyc'>
>>> myDat,labels = trees.createDataSet()
>>> myDat
[[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]
>>> labels
['no surfacing', 'flippers']
>>> trees.calcShannonEnt(myDat)
{'yes': 2, 'no': 3}
0.9709505944546686
>>>
我们贴出实验的完整代码:
#!/usr/bin/env python
# coding=utf-8
# author: chicho
# running: python trees.py
# filename : trees.py
from math import log
def createDataSet():
dataSet = [[1,1,'yes'],
[1,1,'yes'],
[1,0,'no'],
[0,1,'no'],
[0,1,'no']]
labels = ['no surfacing','flippers']
return dataSet, labels
def calcShannonEnt(dataSet):
countDataSet = len(dataSet)
labelCounts={}
for featVec in dataSet:
currentLabel=featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
print labelCounts
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/countDataSet
shannonEnt -= prob * log(prob,2)
return shannonEnt我们再把计算的过程总结一下,方便大家理解:
1.计算数据集中实例的总是,也就是样本的总数。我们把这个值保存成一格单独的变量以便之后方便使用,提高代码的效率
2.创建字典,用于保存类别信息。在整个数据集当中有多少个类别,每个类别的个数是多少
3. 在我们创建的数据字典中,它的键是我们数据集中最后一列的值。如果当前键不存在则把这个键加入到字典当中,依次统计出现类别的次数
4. 最后使用所有类标签对应的次数来计算它们的概论
5.计算香农熵
香农熵越高,则说明混合的数据越多,我们可以在数据集当中添加更多的分类,来观察一下熵是怎么变化的。
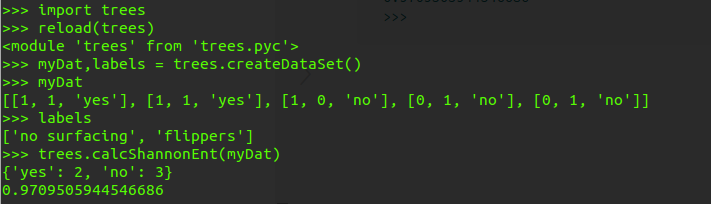
>>> myDat[0][-1]='maybe'
>>> myDat
[[1, 1, 'maybe'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]
>>> trees.calcShannonEnt(myDat)
{'maybe': 1, 'yes': 1, 'no': 3}
1.3709505944546687
>>>对比一下可以发现熵增加了:

得到熵之后我们就可以按照获取最大信息增益的方法划分数据集。
写在后面的话
要么就不做,要做就做最好安利一个微信公众号,希望大家多多关注呢~


相关文章推荐
- java 单例
- 哈理工OJ 1430 神秘植物(矩阵快速幂+矩阵构造)
- UITableView的优化技巧
- IOS 中视频和音乐合成
- IOS 中视频和音乐合成
- KVC解析
- Python 类的一些BIF
- Linux系统管理命令之accton的使用
- ARM架构下编译ekho的记录
- [Leetcode]28. Implement strStr()
- 测试小卒子--接口测试
- WEB前端初级开发面试题归纳
- 使用FFMPEG制作gif图片
- stdarg(3) variable argument lists 可变参数列表
- 深入MySQL源码 学习方法 何登成专家
- string to byte[]
- 图像处理之图像特征:几何不变矩--Hu矩
- Java代理模式(静态模式&amp;动态模式简介)
- Linux下格式化U盘及分区
- 【转】Android Studio系列教程六--Gradle多渠道打包