HBase单机模式和伪分布式模式安装和配置
2016-07-14 21:24
573 查看
##前期准备
可以从 官方下载地址 下载 HBase 最新 stable 版本 hbase-1.2.2-bin.tar.gz.注意, 需要确保下载的 HBase 版本与 Hadoop 版本兼容(Hadoop兼容列表).
####安装
关于 JDK、Hadoop 以及 ZooKeeper 的安装, 可以参考博客的相关文章, 下面简单说明一下 HBase 的安装.将下载的 hbase-1.2.2-bin.tar.gz 文件解压安装到 /opt 目录下:
####环境变量
编辑 /etc/profile
在文件末尾增加以下环境变量配置
使环境变量生效
验证是否安装成功
从上面输出的信息可以看出 HBase 已经安装成功, 接下来将分别进行 HBase 单机模式和集群模式的配置.
##单机模式
###conf/hbase-env.sh
编辑 hbase-env.sh 配置文件:
###conf/hbase-site.xml
编辑 HBase 核心配置文件 hbase-site.xml, 指定本地文件系统上存储 HBase 和 ZooKeeper 数据的目录. 默认 HBase 数据会存储在 /tmp/hbase-${user.name} 目录下. 很多服务器在重启之后会删除 /tmp 目录, 所以应该将数据存储在其它目录下. 配置如下:
hbase.rootdir 用于指定 HBase 数据存储目录, hbase.zookeeper.property.dataDir 用于指定 ZooKeeper 数据存储目录. 需要注意的是, HBase 数据存储目录不需要我们自己创建, HBase 会自动创建。如果你创建了这个目录, HBase 将会尝试做数据迁移.
###启动HBase
bin/start-hbase.sh 可以很方便的启动 HBase.

可以看到 HBase 已经成功启动, 使用 jps 命令可以看到启动了一个称为 HMaster 的进程. 在单机模式中, HBase 在这单个 JVM 中运行所有的守护进程, 比如 HMaster, 单个 HRegionServer, 以及 ZooKeeper 守护进程.
###HBase简单操作
####连接HBase
使用 "hbase shell" 命令可以连接到正在运行的 HBase 实例.
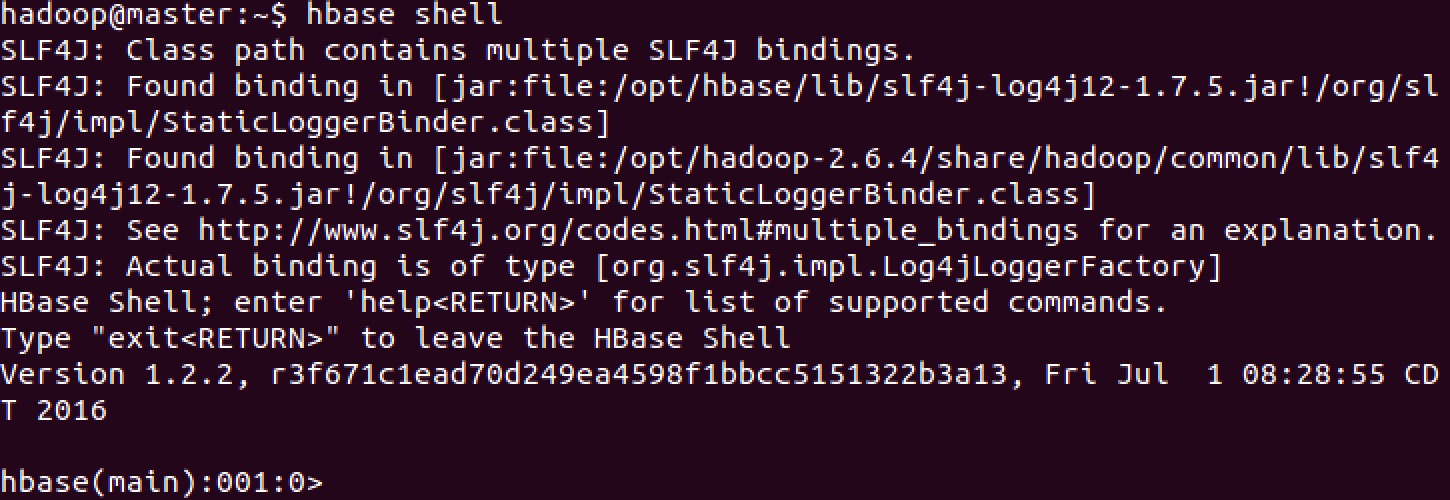
####查看HBase Shell中的帮助文档
在 HBase Shell 中输入 help 并按下回车键, 将会显示一些基本的使用信息以及命令示例. 需要注意的是: 表名, 行, 列都必须使用引号括起来.
####创建表
使用 create 命令可以创建一个新表, 必须要指定表明和列族名.
####列出表的信息
可以使用 list 命令列出 test 表的信息
####往表中插入数据
可以使用 put 命令往表中插入数据.
我们插入了三行数据, 第一行的row key 是 row1, 列是 cf:a, 其值是 value1.HBase 中的列是由列族前缀, 冒号以及列名后缀组成.
####一次扫描表中所有数据
可以使用 scan 命令一次扫描 HBase 表中的所有数据.
####获取单行数据
可以使用 get 命令一次获取一行数据.
####禁用表
在某些情况下如果你想要删除表或是改变其设置, 需要先禁用表.可以使用 disable 命令禁用表, 稍后可以使用 enable 命令重新启用表.
####删除表
在测试了 enable 命令之后再次禁用表, 接着使用 drop 命令删除表:
可以再次使用 list 命令查看表是否已经被删除.
####退出HBase Shell
使用 quit 命令 HBase Shell, 但是 HBase 实例仍然在后台运行.
###停止HBase
bin/start-hbase.sh 脚本可以很方便的启动所有 HBase 守护进程, 同样的, bin/stop-hbase.sh 脚本可以很方便的停止所有 HBase 守护进程.
使用 jps 命令来确保 HMaster 和 HRegionServer 进程都已经关闭.
##伪分布式模式
###conf/hbase-site.xml
编辑 hbase-site.xml 配置文件.首先, 增加以下配置:
将 hbase.cluster.distributed 属性值设置为 true, 指定 HBase 运行于分布式模式, 即一个 JVM 运行一个守护进程.
接着, 将 hbase.rootdir 属性值由本地文件系统路径改成 HDFS 实例的地址, 使用 http://my.oschina.net/jackieyeah/blog/hdfs:/ 这种 URI 语法。在本例中, HDFS运行于本机的 9000 端口.
注意: 不需要在 HDFS 中创建这个目录。HBase 会自动帮我们创建.如果你创建了这个目录, HBase 将会尝试做数据迁移.
###启动HBase
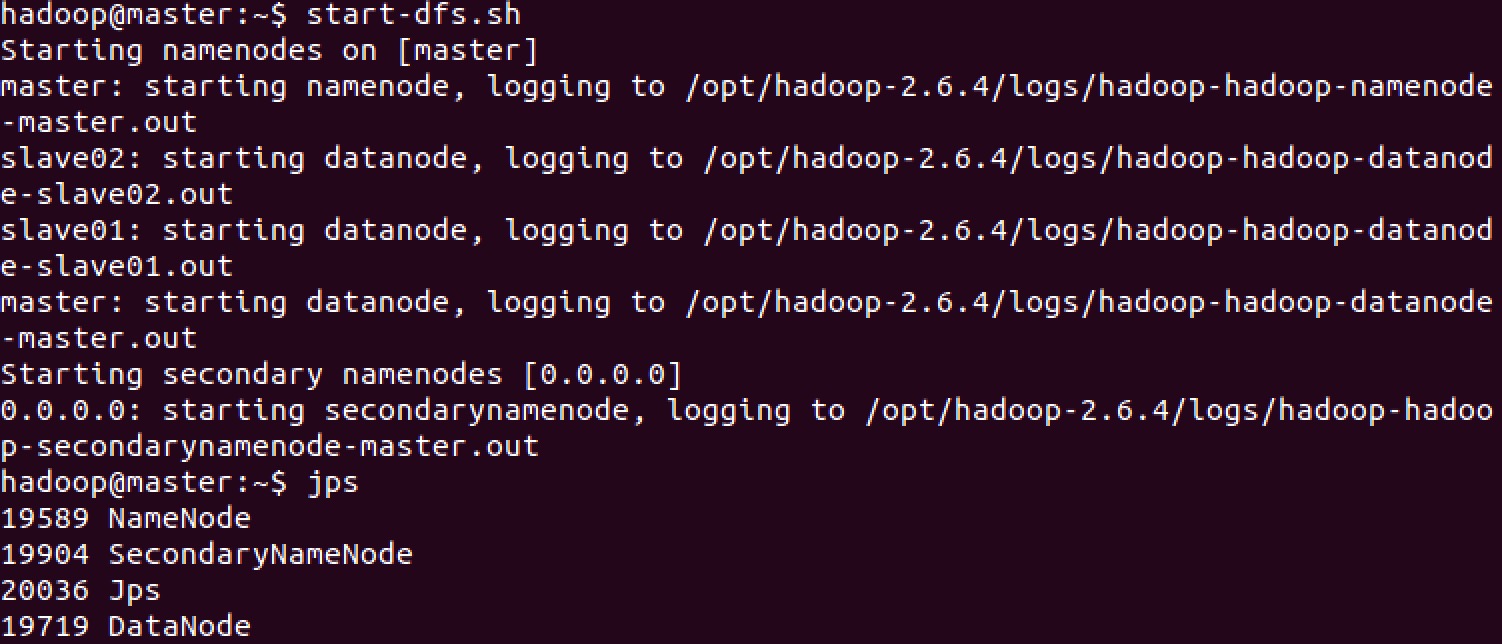
####启动HDFS
在启动 HBase 之前, 先使用 start-dfs.sh 启动 HDFS.
####启动HBase
使用 start-hbase.sh 启动 HBase.
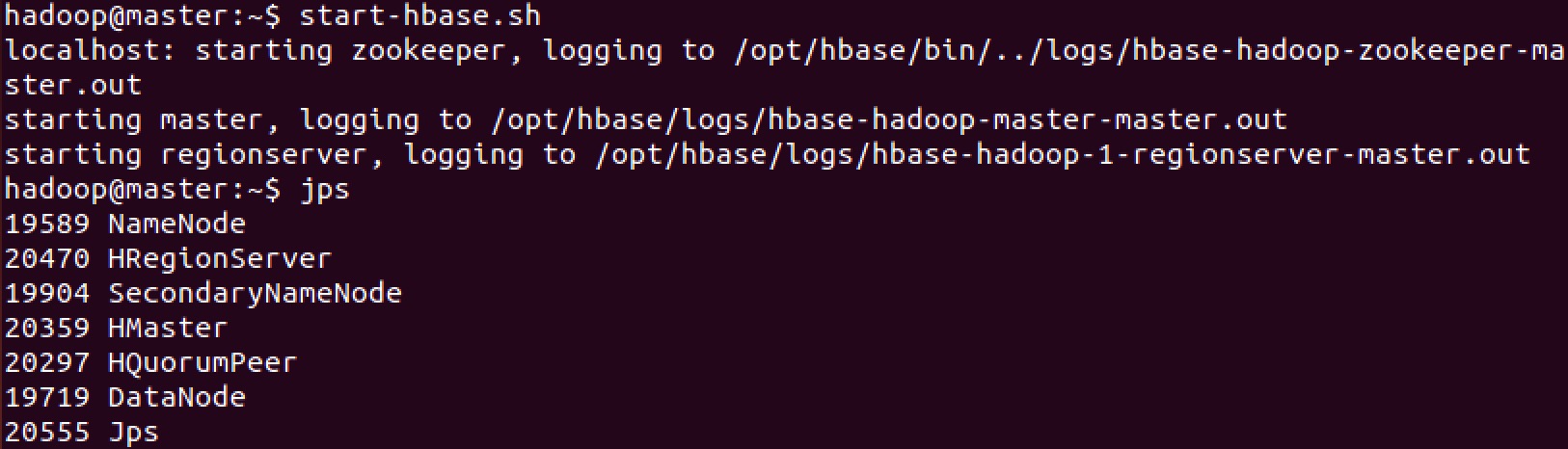
使用 jps 命令可以看到 HMaster, HRegionServer 以及 HQuorumPeer 进程正在运行.
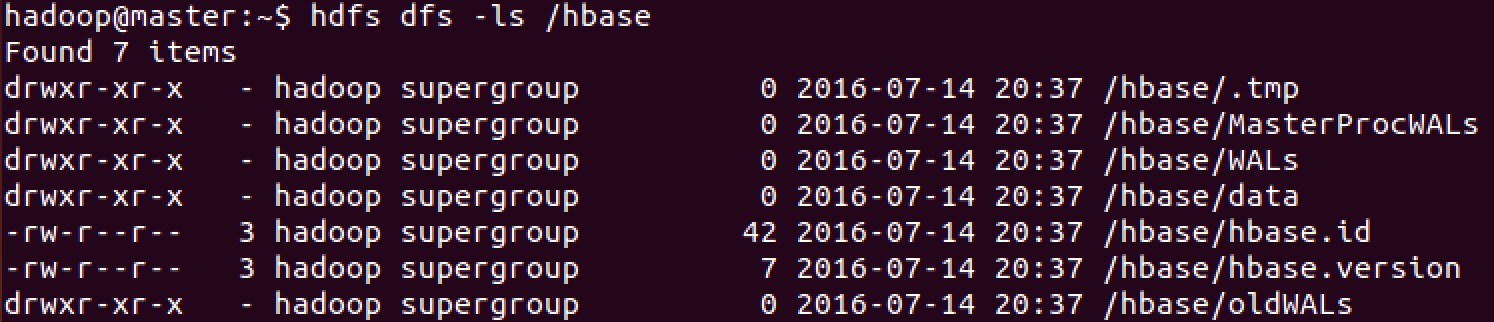
###在HDFS中检查HBase目录
如果一切正常, HBase 将在 HDFS 中创建配置文件中指定的目录 /hbase/. 可以使用 hdfs dfs 命令列出这个目录.
###HBase Shell
####创建表
####查看HDFS路径
/hbase/data/default/test 文件夹即为 test 表在 HDFS 上的存储路径.
##参考资料
http://hbase.apache.org/book.html#quickstart
操作系统
Ubuntu 14.04.1 LTS (GNU/Linux 4.2.0-41-generic x86_64)软件列表
| 软件 | 版本 |
|---|---|
| JDK | 1.7.0_80 |
| Hadoop | 2.6.4 |
| ZooKeeper | 3.4.8 |
| HBase | 1.2.2 |
下载安装
####下载可以从 官方下载地址 下载 HBase 最新 stable 版本 hbase-1.2.2-bin.tar.gz.注意, 需要确保下载的 HBase 版本与 Hadoop 版本兼容(Hadoop兼容列表).
####安装
关于 JDK、Hadoop 以及 ZooKeeper 的安装, 可以参考博客的相关文章, 下面简单说明一下 HBase 的安装.将下载的 hbase-1.2.2-bin.tar.gz 文件解压安装到 /opt 目录下:
sudo tar -zxvf hbase-1.2.2-bin.tar.gz #解压缩 sudo mv hbase-1.2.2 hbase #文件夹重命名 sudo chown -R hadoop:hadoop hbase #修改 hbase 目录所属的用户和用户组
####环境变量
编辑 /etc/profile
sudo vim /etc/profile
在文件末尾增加以下环境变量配置
# HBase Env export HBASE_HOME=/opt/hbase export PATH=$PATH:$HBASE_HOME/bin
使环境变量生效
source /etc/profile
验证是否安装成功
hadoop[@master](http://my.oschina.net/u/48054):~$ hbase version HBase 1.2.2 Source code repository git://asf-dev/home/busbey/projects/hbase revision=3f671c1ead70d249ea4598f1bbcc5151322b3a13 Compiled by busbey on Fri Jul 1 08:28:55 CDT 2016 From source with checksum 7ac43c3d2f62f134b2a6aa1a05ad66ac
从上面输出的信息可以看出 HBase 已经安装成功, 接下来将分别进行 HBase 单机模式和集群模式的配置.
##单机模式
###conf/hbase-env.sh
编辑 hbase-env.sh 配置文件:
export JAVA_HOME=/opt/java/jdk1.7.0_80/ #JDK安装目录 export HBASE_MANAGES_ZK=true #配置hbase自己管理zookeeper
###conf/hbase-site.xml
编辑 HBase 核心配置文件 hbase-site.xml, 指定本地文件系统上存储 HBase 和 ZooKeeper 数据的目录. 默认 HBase 数据会存储在 /tmp/hbase-${user.name} 目录下. 很多服务器在重启之后会删除 /tmp 目录, 所以应该将数据存储在其它目录下. 配置如下:
<configuration> <property> <name>hbase.rootdir</name> <value>file:///opt/hbase/data</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/opt/hbase/data/zookeeper</value> </property> </configuration>
hbase.rootdir 用于指定 HBase 数据存储目录, hbase.zookeeper.property.dataDir 用于指定 ZooKeeper 数据存储目录. 需要注意的是, HBase 数据存储目录不需要我们自己创建, HBase 会自动创建。如果你创建了这个目录, HBase 将会尝试做数据迁移.
###启动HBase
bin/start-hbase.sh 可以很方便的启动 HBase.
可以看到 HBase 已经成功启动, 使用 jps 命令可以看到启动了一个称为 HMaster 的进程. 在单机模式中, HBase 在这单个 JVM 中运行所有的守护进程, 比如 HMaster, 单个 HRegionServer, 以及 ZooKeeper 守护进程.
###HBase简单操作
####连接HBase
使用 "hbase shell" 命令可以连接到正在运行的 HBase 实例.
####查看HBase Shell中的帮助文档
在 HBase Shell 中输入 help 并按下回车键, 将会显示一些基本的使用信息以及命令示例. 需要注意的是: 表名, 行, 列都必须使用引号括起来.
hbase(main):008:0> help
HBase Shell, version 1.2.2, r3f671c1ead70d249ea4598f1bbcc5151322b3a13, Fri Jul 1 08:28:55 CDT 2016
Type 'help "COMMAND"', (e.g. 'help "get"' -- the quotes are necessary) for help on a specific command.
Commands are grouped. Type 'help "COMMAND_GROUP"', (e.g. 'help "general"') for help on a command group.
COMMAND GROUPS:
Group name: general
Commands: status, table_help, version, whoami
Group name: ddl
Commands: alter, alter_async, alter_status, create, describe, disable, disable_all, drop, drop_all, enable, enable_all, exists, get_table, is_disabled, is_enabled, list, locate_region, show_filters
Group name: namespace
Commands: alter_namespace, create_namespace, describe_namespace, drop_namespace, list_namespace, list_namespace_tables
Group name: dml
Commands: append, count, delete, deleteall, get, get_counter, get_splits, incr, put, scan, truncate, truncate_preserve
Group name: tools
Commands: assign, balance_switch, balancer, balancer_enabled, catalogjanitor_enabled, catalogjanitor_run, catalogjanitor_switch, close_region, compact, compact_rs, flush, major_compact, merge_region, move, normalize, normalizer_enabled, normalizer_switch, split, trace, unassign, wal_roll, zk_dump
Group name: replication
Commands: add_peer, append_peer_tableCFs, disable_peer, disable_table_replication, enable_peer, enable_table_replication, list_peers, list_replicated_tables, remove_peer, remove_peer_tableCFs, set_peer_tableCFs, show_peer_tableCFs
Group name: snapshots
Commands: clone_snapshot, delete_all_snapshot, delete_snapshot, list_snapshots, restore_snapshot, snapshot
Group name: configuration
Commands: update_all_config, update_config
Group name: quotas
Commands: list_quotas, set_quota
Group name: security
Commands: grant, list_security_capabilities, revoke, user_permission
Group name: procedures
Commands: abort_procedure, list_procedures
Group name: visibility labels
Commands: add_labels, clear_auths, get_auths, list_labels, set_auths, set_visibility
SHELL USAGE:
Quote all names in HBase Shell such as table and column names. Commas delimit
command parameters. Type <RETURN> after entering a command to run it.
Dictionaries of configuration used in the creation and alteration of tables are
Ruby Hashes. They look like this:
{'key1' => 'value1', 'key2' => 'value2', ...}
and are opened and closed with curley-braces. Key/values are delimited by the
'=>' character combination. Usually keys are predefined constants such as
NAME, VERSIONS, COMPRESSION, etc. Constants do not need to be quoted. Type
'Object.constants' to see a (messy) list of all constants in the environment.
If you are using binary keys or values and need to enter them in the shell, use
double-quote'd hexadecimal representation. For example:
hbase> get 't1', "key\x03\x3f\xcd"
hbase> get 't1', "key\003\023\011"
hbase> put 't1', "test\xef\xff", 'f1:', "\x01\x33\x40"
The HBase shell is the (J)Ruby IRB with the above HBase-specific commands added.
For more on the HBase Shell, see http://hbase.apache.org/book.html####创建表
使用 create 命令可以创建一个新表, 必须要指定表明和列族名.
hbase(main):001:0> create 'test', 'cf' 0 row(s) in 1.7990 seconds => Hbase::Table - test
####列出表的信息
可以使用 list 命令列出 test 表的信息
hbase(main):002:0> list 'test' TABLE test 1 row(s) in 0.0530 seconds => ["test"]
####往表中插入数据
可以使用 put 命令往表中插入数据.
hbase(main):003:0> put 'test', 'row1', 'cf:a', 'value1' 0 row(s) in 0.9960 seconds hbase(main):004:0> put 'test', 'row2', 'cf:b', 'value2' 0 row(s) in 0.0160 seconds hbase(main):005:0> put 'test', 'row3', 'cf:c', 'value3' 0 row(s) in 0.0170 seconds
我们插入了三行数据, 第一行的row key 是 row1, 列是 cf:a, 其值是 value1.HBase 中的列是由列族前缀, 冒号以及列名后缀组成.
####一次扫描表中所有数据
可以使用 scan 命令一次扫描 HBase 表中的所有数据.
hbase(main):006:0> scan 'test' ROW COLUMN+CELL row1 column=cf:a, timestamp=1468473020394, value=value1 row2 column=cf:b, timestamp=1468473053641, value=value2 row3 column=cf:c, timestamp=1468473079601, value=value3 3 row(s) in 0.0770 seconds
####获取单行数据
可以使用 get 命令一次获取一行数据.
hbase(main):007:0> get 'test', 'row1' COLUMN CELL cf:a timestamp=1468473020394, value=value1 1 row(s) in 0.0770 seconds
####禁用表
在某些情况下如果你想要删除表或是改变其设置, 需要先禁用表.可以使用 disable 命令禁用表, 稍后可以使用 enable 命令重新启用表.
hbase(main):008:0> disable 'test' 0 row(s) in 2.3740 seconds hbase(main):009:0> enable 'test' 0 row(s) in 1.3380 seconds
####删除表
在测试了 enable 命令之后再次禁用表, 接着使用 drop 命令删除表:
hbase(main):010:0> disable 'test' 0 row(s) in 2.3220 seconds hbase(main):011:0> drop 'test' 0 row(s) in 1.3210 seconds
可以再次使用 list 命令查看表是否已经被删除.
hbase(main):012:0> list TABLE 0 row(s) in 0.0310 seconds => []
####退出HBase Shell
使用 quit 命令 HBase Shell, 但是 HBase 实例仍然在后台运行.
###停止HBase
bin/start-hbase.sh 脚本可以很方便的启动所有 HBase 守护进程, 同样的, bin/stop-hbase.sh 脚本可以很方便的停止所有 HBase 守护进程.
$ stop-hbase.sh stopping hbase....................
使用 jps 命令来确保 HMaster 和 HRegionServer 进程都已经关闭.
hadoop[[[[[@master](http://my.oschina.net/u/48054)](http://my.oschina.net/u/48054)](http://my.oschina.net/u/48054)](http://my.oschina.net/u/48054)](http://my.oschina.net/u/48054):~$ jps 15730 Jps
##伪分布式模式
###conf/hbase-site.xml
编辑 hbase-site.xml 配置文件.首先, 增加以下配置:
<property> <name>hbase.cluster.distributed</name> <value>true</value> </property>
将 hbase.cluster.distributed 属性值设置为 true, 指定 HBase 运行于分布式模式, 即一个 JVM 运行一个守护进程.
接着, 将 hbase.rootdir 属性值由本地文件系统路径改成 HDFS 实例的地址, 使用 http://my.oschina.net/jackieyeah/blog/hdfs:/ 这种 URI 语法。在本例中, HDFS运行于本机的 9000 端口.
<property> <name>hbase.rootdir</name> <value>hdfs://master:9000/hbase</value> </property>
注意: 不需要在 HDFS 中创建这个目录。HBase 会自动帮我们创建.如果你创建了这个目录, HBase 将会尝试做数据迁移.
###启动HBase
####启动HDFS
在启动 HBase 之前, 先使用 start-dfs.sh 启动 HDFS.
####启动HBase
使用 start-hbase.sh 启动 HBase.
使用 jps 命令可以看到 HMaster, HRegionServer 以及 HQuorumPeer 进程正在运行.
###在HDFS中检查HBase目录
如果一切正常, HBase 将在 HDFS 中创建配置文件中指定的目录 /hbase/. 可以使用 hdfs dfs 命令列出这个目录.
###HBase Shell
####创建表
hbase(main):006:0> create 'test', 'cf' 0 row(s) in 1.4440 seconds => Hbase::Table - test hbase(main):007:0> list TABLE test 1 row(s) in 0.0170 seconds => ["test"]
####查看HDFS路径
hadoop[[[[[@master](http://my.oschina.net/u/48054)](http://my.oschina.net/u/48054)](http://my.oschina.net/u/48054)](http://my.oschina.net/u/48054)](http://my.oschina.net/u/48054):~$ hdfs dfs -ls /hbase/data/default Found 1 items drwxr-xr-x - hadoop supergroup 0 2016-07-14 21:00 /hbase/data/default/test
/hbase/data/default/test 文件夹即为 test 表在 HDFS 上的存储路径.
##参考资料
http://hbase.apache.org/book.html#quickstart

相关文章推荐
- Facebook's New Real-time Messaging System: HBase to Store 135+ Billion Messages a Month
- Hadoop生态上几个技术的关系与区别:hive、pig、hbase 关系与区别
- 基于HBase Thrift接口的一些使用问题及相关注意事项的详解
- 如何解决struts2日期类型转换
- java 保留两位小数的几种方法
- Java IO流 文件传输基础
- Eclipse中查看android工程代码出现"android.jar has no source attachment"的解决方案
- 基于Java实现杨辉三角 LeetCode Pascal's Triangle
- hbase shell基础和常用命令详解
- 手把手教你配置Hbase完全分布式环境
- 实战:在Java Web 项目中使用HBase
- HBase RowKey设计的那些事
- Spark中将对象序列化存储到hdfs
- HBase基本原理
- HBase中的基本概念
- 【原创】基于分布式存储的开源系统在实时数据库海量历史数据存储项目上的预研
- HBase0.96.x开发使用(一)--安装
- 基于外部ZooKeeper的GlusterFS作为分布式文件系统的完全分布式HBase集群安装指南
- 基于solr实现hbase的二级索引