决策树算法(二)——构建数据集
2016-07-14 09:46
232 查看
目录索引
目录索引写在前面的话
决策树构建的一般流程
数据的构建
参考链接
写在后面的话
写在前面的话
如果您有任何地方看不懂的,那一定是我写的不好,请您告诉我,我会争取写的更加简单易懂!如果您有任何地方看着不爽,请您尽情的喷,使劲的喷,不要命的喷,您的槽点就是帮助我要进步的地方!
1.决策树构建的一般流程
收集数据:任何你能收集数据的方法准备数据: 决策树的算法只适用于标称型数据(可理解为离散型的,不连续的),因此数值型的数据(连续的数据)必须离散化。
分析数据: 可以使用任何方法,构造树完成之后,我们要检查图形是否符合预期。
训练算法:构造决策树的数据结构。
测试算法: 使用经验树计算错误率。
使用算法: 此步骤可以适用于任何监督学习算法,而使用决策数可以更好的理解数据的内在含义 (why? 对比于其他算法,比如说k均值算法,就是把给定的数据按照相似度分为一类,每一类表示什么你可能就不知道了。就像我们上一章讲的那个例子,可以用决策树做邮件的分类系统,我们可以根据分类标签知道这个邮件是垃圾邮件还是需要立刻处理的邮件)
2. 数据的构建
我们使用的例子还是《机器学习与实战》那本书上的例子。我把写作的思路和流程改了一下,还有这本书里好多错误,我好想帮作者重写这本书,或许不是作者的错误,是翻译和排版的错误。首先我们第一步还是收集数据:

在这张表中我们可以发现这里有5个数据,这里有两个特征(要不要浮出水面生存,和是否有脚蹼)来划分这5个生物是鱼类还是非鱼类。
现在我们要做的就是是要根据第一个特征还是第二个特征来划分数据,进行分类。
我们使用python来构建我们的代码。
我们创建一个名为trees.py的python文件,然后在下面输入以下的代码
#!/usr/bin/env python # coding=utf-8 # author: chicho # running: python trees.py # filename : trees.py def createDataSet(): dataSet = [[1,1,'yes'], [1,1,'yes'], [1,0,'no'], [0,1,'no'], [0,1,'no']] # 我们定义了一个list来表示我们的数据集,这里的数据对应的是上表中的数据 labels = ['no surfacing','flippers'] return dataSet, labels
其中第一列的1表示的是不需要浮出水面就可以生存的,0则表示相反。 第二列同样是1表示有脚蹼,0表示的是没有。
这个时候我们来测试以下我们的数据集。
我用的是linux系统,我们打开一个终端来测试以下我们的数据。
我们创建完这个文件之后,进入到这个文件的目录下。我把这个文件保存在~/code 这个路径下。

我们输入python,进入shell命令,如下图所示

代码如下:
>>> import trees >>> reload(trees) <module 'trees' from 'trees.pyc'> >>> myDat,labels=trees.createDataSet() >>> myDat [[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']] >>> labels ['no surfacing', 'flippers'] >>>
我们来说说这段代码:
import的作用:
导入/引入一个python标准模块,其中包括.py文件、带有init.py文件的目录。
例如:
import module_name[,module1,...] from module_name import *|child[,child1,...]
注意:
多次重复使用import语句时,不会重新加载被指定的模块,只是把对该模块的内存地址给引用到本地变量环境。
也就是说使用import的时候引用的module只会被加载一次,只会被加载一次,系统会把这个模块的地址给引用它的代码或者是这个python文件。
我们来测试以下
构建两个文件 a.py 和 b.py
其中a.py的代码如下:
#!/usr/bin/env python # coding=utf-8 import os print 'in a.py file' print 'The address of os is:', id(os) print '***end***'
我们在b.py中写如下代码:
#!/usr/bin/env python # coding=utf-8 #filename: b.py import a import os print "*****************" print 'in b file' print 'The adress of b file is:',id(os) import a print 'The adress of a module is:',id(a)
这个时候,我们来测试以下结果:
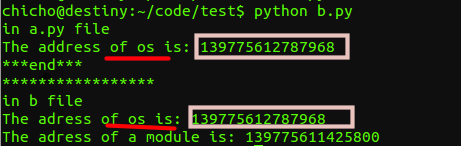
我们在a,b两个文件中都引入了os 模块但是我们发现它的地址都没有改变。
reload
reload 的目的是为了开发期的 “edit and debug”/即编即调
reload 的作用:
对已经加载的模块进行重新加载,一般用于原模块有变化等特殊情况,reload前该模块必须已经import过。
e.g:
import os reload(os)
说明:
reload会重新加载已加载的模块,但原来已经使用的实例还是会使用旧的模块,而新生产的实例会使用新的模块;reload后还是用原来的内存地址;不能支持from。。import。。格式的模块进行重新加载。
我们在举一个例子:
创建两个文件c.py, 以及文件 d.py
#!/usr/bin/env python # coding=utf-8 # filename : c.py import os print 'in c.py file' print 'The address of os is:', id(os) print '***end***'
这个时候我们用d.py这个文件去引用c这个模块
#!/usr/bin/env python # coding=utf-8 #filename: d.py import c import os print "*****************" print 'in d file' print 'The adress of os is:',id(os) print 'The address of c file is:',id(c) print '*****reload******' reload(c) print '****reload*****' print 'The adress of c module is:',id(c)
接下来我们来测试一下结果:

可以发现reload和import的区别就是一个只能加载模块多次,一个可以加载一次
总之,我们的数据集就这么愉快的创建好了。
3.参考链接
http://blog.csdn.net/turkeyzhou/article/details/8846527写在后面的话
我又打不动字了,本来还想写的更好一些,有时间再来补得更好一点吧。要么就不做,要做就做最好,这是我的忍道!
所以这篇blog也是我好好写的,有啥需要改进的请您及时告诉我。^^

相关文章推荐
- oracle数据库中的函数依赖
- extjs学习
- UVA-644 Immediate Decodability
- nginx php-fpm安装配置
- TeeChart中 Line的Clear方法
- hdu 5266(线段树+LCA)
- 关于Linux系统清理/tmp/文件夹 清理时间问题
- 【English】Search for your meaning
- React Native 中文版(含新增 Android 章节)
- matlab对文件目录路径的操作
- 使用ssh-keygen和ssh-copy-id三步实现SSH无密码登录
- mybaits使用经验(1)
- 面试题32:整数中1出现的次数(从1到n整数中1出现的次数)
- 折半排序法(二分插入排序法)
- oracle关系数据库模型
- 小孩报数问题
- 极大似然估计
- (error/warning)java Unsafe等改变安全性的类怎样去掉eclipse错误提示
- android 判断应用程序是否已安装
- 160707、Tomcat 使用 c3p0连接池