拉勾网爬取的招聘数据解读--大数据分析师要掌握的工具与语言
2016-07-13 17:14
435 查看
拉勾网爬虫招聘数据解读–大数据分析师要掌握的工具与语言
标签(空格分隔): 爬虫随着大数据的发展,大数据分析师越来越成为企业青睐的对象。在数据大潮里,拥有数据,利用数据,商业化数据渐渐成了企业关注的焦点。
本人是一名伪数据分析师,伪算法工程师,还有,伪文艺工作者。一直在想,如何才能成为一名真正的,能上天入地的大数据分析师和诗词歌赋,琴棋书画信手拈来的文艺青年呢。在这个看脸的世界里,对于后者我放弃,那么对于前者我总结出以下几点:
(1)首先要会这些语言:
R或python———数据分析师必备语言
java————大数据分布式框架hadoop要用到的语言
scala————目前最火的内存计算框架spark所需要用到的语言
sql————非常非常基本的关系型数据库的语言,几乎每家企业都要用到
nosql———— 非关系型数据库的语言,比如列式存储的hbase,大数据框架里的重要成员
(2)然后,要熟悉大数据的主要框架:
有些公司在用HADOOP,所以你要会hadoop,hive,hue,ozzie,hbase,flume,sqoop,等等等
有些公司直接用spark了,所以你熟练使用spark的mllib,streaming,sql…
有些公司,两个都在用。。。。。。
(3)还然后,要具备以下数学技能:
概率论,统计学,线性代数,微积分….(大学的高数统统给我用起来)
掌握机器学习的各类算法和模型,分类,聚类,推荐,回归,关联,自然语言处理,图像处理等等等,不但会用代码实现,还要对原理分分钟熟透,否则在调参和优化的时候就不知所云了
(4)再然后,要有阅读能力:
中文文献阅读能力
英文文献阅读能力(这个是关键)
(5)接着然后,要有明锐的商业思维,能结合企业的需求洞察数据的商业价值….云云云云….大家懂的
那个,大家不要灰心,我前面说了,这是成为“上天入地”的大数据分析师的要求,而且是我自己意淫的,可做参考,但不是标案。
其实呢,每个企业的业务不一样,所以对数据分析师的要求也不一样,为了佐证我yy的要求是不是靠谱呢,昨晚半夜回到家,我用爬虫将拉勾网上的所有大数据分析师相关的招聘信息全部爬了下来,包括招聘岗位,招聘单位,薪资,地点,工作诱惑,职位要求,岗位描述等等等。
正题
1.数据获取与存储
拉勾网上的 “大数据分析师岗位” 总共有272条,爬取数据去重后总共是262条。因为数据量不大,我将它各存了一份excel,和txt。看,以下是数据的一部分,感觉美美哒。
但是!!我定睛一看,发现已经坑爹地爬错了!我居然漏了一个“大”字!真是粗心的毛病自小改不了。。。我应该爬”大数据分析师”,“机器学习”,“算法工程师”,“数据挖掘”这些类别的,单纯地“数据分析师”面就有点太广了。
算了,那么我们就来分析一下“数据分析师要掌握的工具与语言”吧。。。。。。
2.企业中数据分析的工具的应用情况
分析工具其实是至关重要的,那么多数据分析工具,企业到底需要会什么的人呢,那就去看看企业招聘的时候在工作描述中都提到了哪些工具。我简单地做了个统计,下图中可以看到,有174家企业在岗位需求中说道了SAS,是使用最多的一种工具(现在企业都那么有钱啊,记得读书的时候用的是SAS,跑一个算法,跑了一节课,而且装起来超级大的,期末复习和写论文的时候还要每天做公车去学校机房里面练习,所以我个人对它有些情绪。。。SAS的小伙伴不要打我)
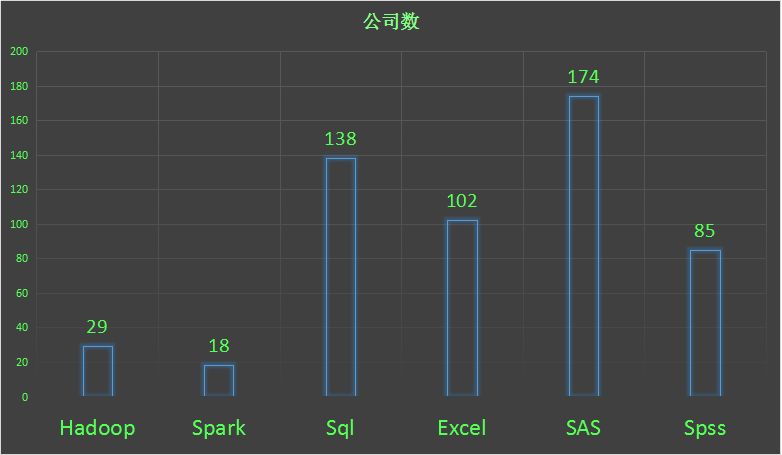
其次是SQL,SQL其实包括了mysql,sql server,等等之类的关系型数据库,非常好用,是企业存取数据的青睐工具。许多企业都会要求数据分析师用sql来制作报表,统计数据,另外,如果企业搭建了大数据平台,关系型数据库也是不可或缺的一员。
然而sql只是处理描述性统计,如果要做数据挖掘,数据建模都是不行的。这里我要强烈推荐spark sql,spark是一种内存计算框架,它提供了sql的功能和机器学习的包,可以直接写sql然后调用机器学习的包来做数据挖掘,是不是棒棒哒。
第三名是Excel,这个就不说了,非常通用,功能也很强大,很佩服把excel玩得很溜的人,但是对于大只的数据量,excel就完全无法满足了。而对于适当的数据量,有许多功能处理起来比写代码要方便,上面的条形图就是excel画的。
第四名是SPSS,特别喜欢他输出结果的格式,清楚,规范,整洁。而且使用起来也上手和方便,但是也不适用于大数据,如果它可以运行在大数据框架上,相信会很受非代码族的喜爱。
嗯,接下来是我喜爱的两个东东了,hadoop,和spark,虽然排名难看了些,但是已经非常体现趋势了。别忘了我只是爬了“数据分析师”的职位,如果爬的是“大数据分析”,“算法”,“数据挖掘”,“机器学习”这些岗位,相信至少90%会至少有hadoop,spark其中之一的。这两个框架都是分布式的大数据框架,要搞大数据的企业估计应该离不开他们,特别是spark,我相信,星星之火可以燎原。
(小伙伴们如果对spark和Hadoop,以及大数据感兴趣,欢迎关注我的微信公众号bigdataML,我会定期分享的学习笔记,或者文档资料给大家。)
3.企业中数据分析语言的应用情况
很佩服把代码写得很帅的人。当分析慢慢变成挖掘的时候,能写一手随心所欲的程序便是尤为骄傲的。那么企业对语言的需求又是如何的呢?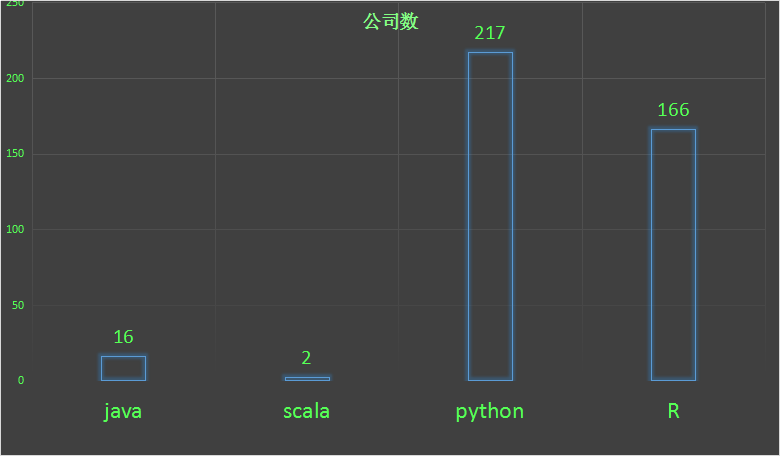
python 217,R 166。
数据代表一切,我说的没错,这两种语言是数据分析师必备的。它们不但轻巧简便,而且已经有非常多的封装好的包可以直接被调用,所以简单易学。上个月我在英国读人力资源的表妹来求救我说老师要求她论文用R来做数据模型,把她吓的,后来硬着头皮还是靠自己把代码和论文都美美地写出来了,这个故事告诉我们,对于未知,不要惧怕,试着去了解,去学习,也许忽然,就柳暗花明又一村了。
java其实在数据分析中并不占优势,它的优势应该在于架构,比如企业要搭建hadoop大数据平台,那么离不开java工程师,最重要的是hadoop是用java写的,hadoop主要成员之一的分布式计算框架—MapReduce需要java来编写程序。所以,java工程师非常容易转行做大数据开发工程师。当然,如果企业的数据分析立足于hadoop的mapreduce的话,java自然成了分析师的必备语言了。
scala感觉是一个很冷门的语言,如果大放光彩的Spark不是用scala语言来写的话,估计它是闺阁寂寞锁清秋,轩窗独倚诉孤愁。scala和java应该说是同胞的兄弟,有血缘关系,非常相似。但是不知原因的,我偏爱于scala,甚至可以说情不知所起,一往而情深,不过现在也属于倒追阶段,还尚未得手。scala是个非常干净,朴素的白衬衫男子,做事高效快速不拖沓,力求用最少的力做最完美的事。一句话能说完的事,它绝不滔滔不绝添油加醋地多说一个字,一个眼神能领会的意思它绝不挤眉弄眼大张旗鼓地故弄玄虚。额,说回人话,举一个例子,使用hadoop中的mapreduce来用java写一个wordcount程序要几十行甚至近百行,scala只用一行一句话搞定。但是呢,就是因为它从前的隐居山林,所以被人们使用地非常少,这也是企业招聘时很少会涉及scala的原因,但是无论如何,我也相信,它终会拥有,诗与远方。
结束语
看到这里的小伙伴,我真的好感动,麻烦给我点个赞让我知道你们是谁。笔者见识短浅,蛙于井底,若有错误疏漏与有失严谨,请多指正,一起进步。最后,感叹一下,其实人生真的很奇妙,居然有一天我在打起了代码,做起来了很奇怪的事。也许很多年以后,我又会做起更奇怪的事,好像是被生活牵着走,又好像是故意跟着走的,无论如何,蠢笨如我也需要给自己一笔尝试的勇气,因为就算不能时常坚持每件事,但终于会找到最坚持的事。

相关文章推荐
- 对Binder的浅显分析及AIDL的使用
- what is the trick that PtOSContainer
- rancid install file
- Mondrian 4 测试的简单demo(Saiku简单测试Schema文件)
- http://jingyan.baidu.com/article/fcb5aff78e6a48edab4a7146.html
- RAID技术介绍和总结
- 大数据时使用索引实例
- Tensorflow 杂记
- http://blog.csdn.net/guolin_blog/article/details/17612763
- AVC编码中的规格 :High、Baseline、Main什么意思?还有High@L3.0、High@L4.0、High@L5.1等
- 什么是CDN-Akamai
- cc2541从机向主机传大数据
- LeetCode 70. Climbing Stairs
- WCF 内存入口检查失败 Memory gates checking failed
- Excel大数据字段导入SQLserver时报截断错误
- Passed-in Resource [resource loaded through InputStream] contains an open stream:cannot determine
- RAID详解
- [LeetCode算法笔记]Find K Pairs with Smallest Sums与优先队列
- int main(int argc, char* argv[])用法解析
- CodeForces 474C Captain Marmot (数学,旋转,暴力)