Spark学习笔记#1-快速入门
2016-07-13 16:45
357 查看
Spark学习笔记#1-快速入门
之前我已经安装配置好了PySpark,这里就按照Spark官网上的Quick Start来快速入门。这篇文章就当是Spark官网Doc的一个翻译和测试记录。目录
-使用Spark Shell进行交互式分析–基本
–更多基于RDD的操作
–缓存
-独立的程序
-快速入门完之后的去向
这个教程提供了一个使用Spark的快速教程。我们将会首先通过Spark的交互式Shell介绍API(可以是Python,也可以是Scala),然后就展示一下怎么在Java、Scala和Python中写(独立的)应用程序。
更多详情可以进入编程指导。
想要学习这个指南,首先需要从Spark官网下载一个Spark的发行包。由于我们并不会用到HDFS,你可以下载一个适合任何版本的Hadoop的发行包。
注意:因为我没研究过Scala所以在这里提供的只有Python的代码,如有Scala代码的需要可以上原文查看。
使用Spark Shell进行交互式分析
基础
一个简单的学习API的方式就是使用Spark的shell,同时这个交互式shell也是一个强力的数据分析工具。它不仅能运行在Scala,还可以在Python上。从在Spark安装目录开始我们的第一步吧!./bin/pyspark
注意:如果忘记了之前安装配置了的spark目录可以通过命令
$which pyspark来找到该目录
Spark主要的概念就是一个叫RDD (Resilient Distributed Dataset)的分布式数据集。RDD可以通过Hadoop的InputFormats(比如说HDFS文件)或者通过从其他RDD变形来创建。我们来从任意一个文本文件做一个新的RDD吧!我这里选择的是我桌面上的一个文本文件
fifo.c。
>>>textFile = sc.textFile("./Desktop/fifo.c")注意:引号里面是文件的路径,可以根据自己的需要进行修改。
RDD本身是可以进行操作的,这些操作往往会返回一些值或者一些新的RDD变形。我们就从以下操作开始吧!
>>> textFile.count() # 这个RDD中所有item的数目————即行数 166 >>> textFile.first() # 在这个RDD中的首个item————即首行 u'#include <linux/init.h>'
注意:在我的配置环境下,pySpark是会打印形如
16/07/11 11:10:29 INFO Executor: Running task 1.0 in stage 0.0 (TID 1)的log信息的,关闭这些调试信息的方法可以参考How to turn off INFO logging in PySpark?。
现在,我们来使用一种返回RDD变换————我们将使用筛选器(filter)的来返回一个新的经过变换RDD,这个RDD是上述文件的一个子集(subset)。
>>> linesWithSpark = textFile.filter(lambda line: "linux" in line) # 找到这个RDD中所有含有字符串“linux”的行并把经过筛选的结果返回到linesWithSpark中
注意:这里是一个函数式编程的范例,有关于lambda的知识我了解不多,可以参考Python anonymous functions (lambdas)。
我们也可以把变换和操作整合到一起:
>>> textFile.filter(lambda line: "linux" in line).count() # RDD中有多少行包含了字符串“linux”? 6
更多基于RDD的操作
RDD操作和变形可以被用到更为复杂的计算当中。比如说假如我们要找到包含最多单词的一行:>>> textFile.map(lambda line: len(line.split())).reduce(lambda a, b: a if (a > b) else b) 14
这个表达一开始把行对应成一个整数值,并创建新的RDD。
reduce在这个表达中被调用来在RDD中找到最大计数值的行。
map和
reduce的参数是Python的匿名函数,但是我们也可以传递任何一个我们想要使用的更高级的Python函数调用。比如说,我们可以定义一个
max函数,来让上面这段代码更易懂一些:
>>> def max(a, b): ... if a > b: ... return a ... else: ... return b ... >>> textFile.map(lambda line: len(line.split())).reduce(max) 14
Spark也可以很容易的添加像
Hadoop一样出名的
MapReduce这样常见的数据流模式:
>>> wordCounts = textFile.flatMap(lambda line: line.split()).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a+b)
上述表达中,我们混合了flatmap、map和reduceByKey的RDD变换来生成RDD对,计算文件中每个词出现的次数。为了得到这些单词计数值的合计,我们要使用到collect操作:
>>> wordCounts.collect() [(u'MAX_SIZE)', 2), (u'file_operations', 1), (u'-', 5), (u'dynamic', 1), (u'scull_fops', 1), (u'MAX_SIZE;', 1), (u'count+end-MAX_SIZE))', 1), (u'scull_release(struct', 1), ...]
缓存到内存
Spark也支持把数据集放进和集群一样大小的内存空间中去。这对于大量重复访问的数据来说是很有用的,比如说访问一个非常小的“热门”数据集,又或者在执行一种类似于PageRank的迭代算法。我们把我们刚刚使用的linesWithSpark作为一个简单的例子:>>> linesWithSpark.cache() >>> linesWithSpark.count() 6 >>> linesWithSpark.count() 6
可能使用Spark来缓存100行左右的文本文件看起来很蠢,但又去的是这样的功能也可以用来处理非常大的数据集,甚至当这些数据集在上百个节点中交错纵横。你也可以连接
bin/spark和一个数据集交互性地完成上述工作,可以参考编程指导。
独立的程序
当我们想要写一个使用了Spark API的独立程序该怎么做呢?我们就通过一个简单的Python程序来看看吧!现在我们演示一下怎么使用Python API(PySpark)写一个应用程序,作为一示例程序,我们可以新建一个Python文件命名为
SimpleApp.py:
"""SimpleApp.py"""
from pyspark import SparkContext
logFile = "./Desktop/fifo.c" # 你系统中的一个文件
sc = SparkContext("local", "Simple App")
logData = sc.textFile(logFile).cache()
numAs = logData.filter(lambda s: 'a' in s).count()
numBs = logData.filter(lambda s: 'b' in s).count()
print("Lines with a: %i, lines with b: %i" % (numAs, numBs))注意:在编写独立的Python应用中,遇到找不到pyspark包的错误是环境变量配置的问题。可以参考我上一篇文章:如何将PySpark导入Python
这个程序仅仅数出了某个文本文件(这里是我之前用来测试的fifo.c)包含字母‘a’的行数和包含字母‘b’的行数。运行结果如下:
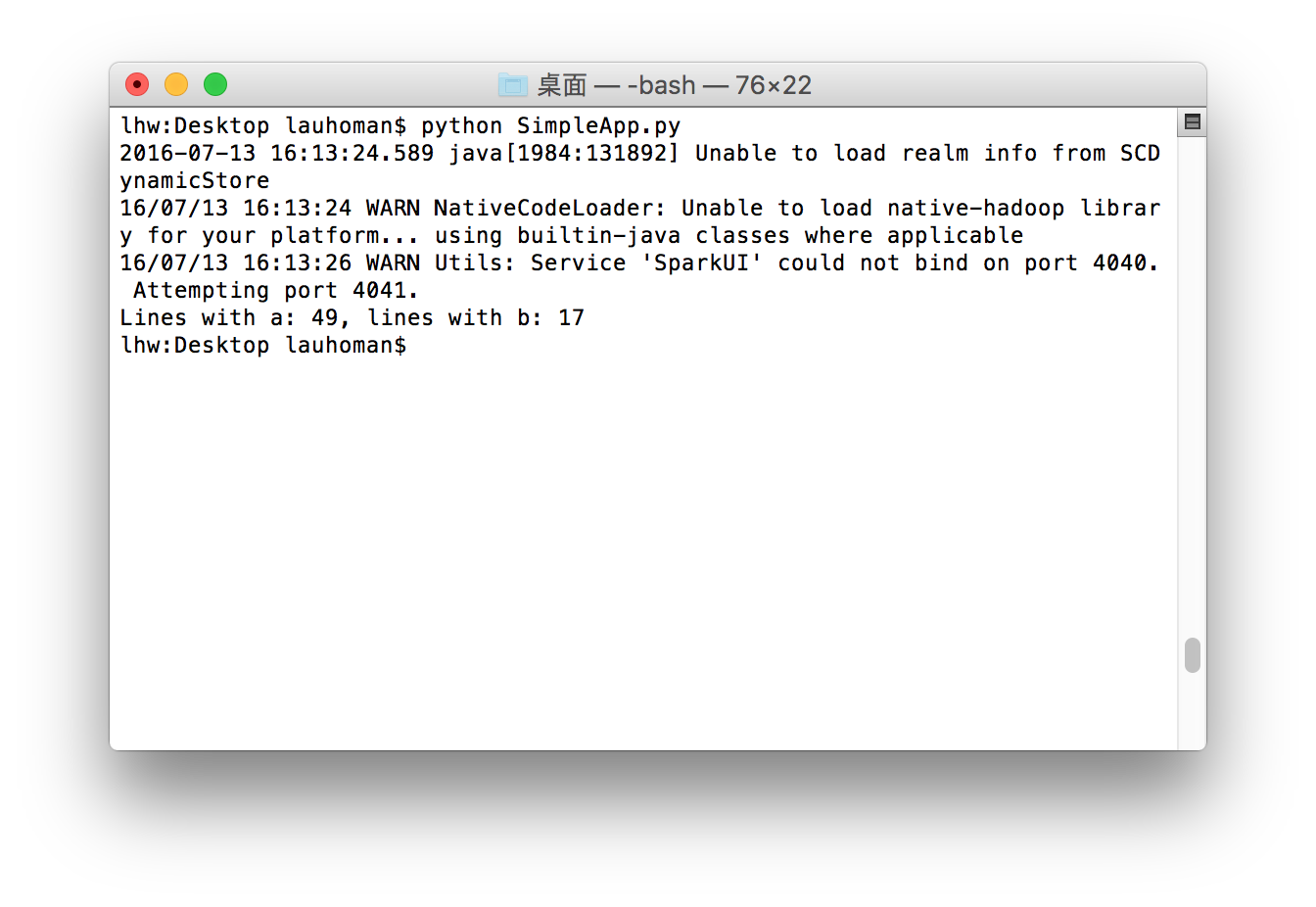
请注意你需要将你的Spark目录设置为YOUR_SPARK_HOME环境变量(可以参考我上一篇文章:如何将PySpark导入Python)。在Scala和Java的例子中,我们使用了SparkContext来创建RDD。我们也可以把Python函数传递给Spark,其中被引用的变量会自动序列化地传递(不太理解这段话什么意思)。对于需要使用到自定义类或者第三方库的应用,我们也可以把源码依赖打包成.zip文件,通过–py–files的参数传递给spark-submit来添加代码(具体请参考spark-submit –help)。
SimpleApp简单的不需要任何特定的代码依赖,(所以)我们可以使用bin/spark-submit脚本来运行这个程序。
# Use spark-submit to run your application $ YOUR_SPARK_HOME/bin/spark-submit \ --master local[4] \ ./Desktop/SimpleApp.py ... Lines with a: 49, Lines with b: 17
快速入门完之后的去向
恭喜!你已经运行了你的第一个Spark应用程序了!对于想要深入了解API的用户,请从Spark编程指南开始,或者从指南菜单中查阅其他部分内容。
对于想要把程序放在集群上运行的用户,前往部署概述
最后,Spark在
examples文件夹中自带了一系列示例(Scala、Java、Python、R)。你可以用以下方式运行之:
# For Scala and Java, use run-example: ./bin/run-example SparkPi # For Python examples, use spark-submit directly: ./bin/spark-submit examples/src/main/python/pi.py # For R examples, use spark-submit directly: ./bin/spark-submit examples/src/main/r/dataframe.R
参考:
Spark安装配置Spark官网:Quick Start
Spark官网:下载页
Spark官网:programming guide
Spark官网:cluster overview
Spark官网:Python anonymous functions (lambdas)
Stackoverflow.com:How to turn off INFO logging in PySpark?

相关文章推荐
- Python动态类型的学习---引用的理解
- Python3写爬虫(四)多线程实现数据爬取
- 垃圾邮件过滤器 python简单实现
- 下载并遍历 names.txt 文件,输出长度最长的回文人名。
- Spark RDD API详解(一) Map和Reduce
- 使用spark和spark mllib进行股票预测
- install and upgrade scrapy
- Scrapy的架构介绍
- Centos6 编译安装Python
- 使用Python生成Excel格式的图片
- 让Python文件也可以当bat文件运行
- [Python]推算数独
- Python中zip()函数用法举例
- Python中map()函数浅析
- Python将excel导入到mysql中
- Spark随谈——开发指南(译)
- Python在CAM软件Genesis2000中的应用
- 使用Shiboken为C++和Qt库创建Python绑定