统计学习方法----决策树
2016-07-12 21:55
232 查看
决策树模型:树形结构,选择较优的特征,对实例进行分类的过程。
(可以与Adaboost算法结合使用,由弱分类器转化为强分类器)
包含3个步骤:特征选择,决策树生成,决策树修剪。
(决策树的生成对应模型的局部选择,决策树的修剪对应模型的全局选择)
1)特征选择:
准则:信息增益(ID3算法)---matlab自带为treefit;
信息增益比(ID4.5算法)
基尼指数(CART算法)---MATLAB自带的classregtree函数
a)信息增益:
熵:表示随机变量不确定性的度量;



条件熵H(Y|X):表示已经随机变量X的条件下,随机变量Y的不确定性;
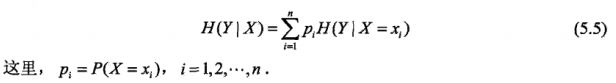
信息增益:表示已知特征X的信息而使得类Y的信息不确定性减少的程度;

某个特征的信息增益越大,说明这个特征越可取。


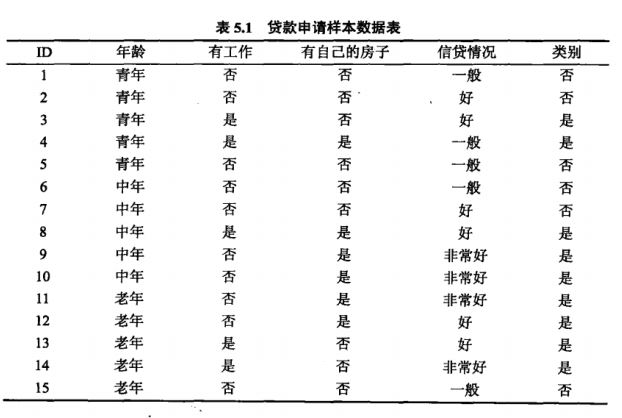


b)信息增益比:

(可以与Adaboost算法结合使用,由弱分类器转化为强分类器)
包含3个步骤:特征选择,决策树生成,决策树修剪。
(决策树的生成对应模型的局部选择,决策树的修剪对应模型的全局选择)
1)特征选择:
准则:信息增益(ID3算法)---matlab自带为treefit;
信息增益比(ID4.5算法)
基尼指数(CART算法)---MATLAB自带的classregtree函数
a)信息增益:
熵:表示随机变量不确定性的度量;
条件熵H(Y|X):表示已经随机变量X的条件下,随机变量Y的不确定性;
信息增益:表示已知特征X的信息而使得类Y的信息不确定性减少的程度;
某个特征的信息增益越大,说明这个特征越可取。
b)信息增益比:

相关文章推荐
- 为什么统计学家应该关注数据挖掘
- 自己做的一个肤色检测模型
- 关于机器学习的学习笔记(二):决策树算法
- 数据挖掘--分类--决策树--算法
- 数据挖掘--分类--决策树--特征
- 机器学习之决策树整理
- 最小二乘法
- 统计学习(一)--统计学习的定义及常识
- 统计学原理----走出平均数理解上的误区
- SAS软件的使用和统计学分析的初步介绍
- 基于个人选择的一点想法
- 美国纽约留学的日子
- 一步一步详解ID3和C4.5的C++实现
- 读 统计学习方法 摘要
- mysql统计用户七日留存存储过程
- 初学MCMC(Markov Chain Monte Carlo)
- 初学MCMC(Markov Chain Monte Carlo)
- 生物&统计学词汇解释
- 统计学习-4
- 统计学习-3