机器学习中几种常见优化方法总结
2016-07-12 17:22
337 查看
1、梯度下降法
假设f(x)是具有一阶连续偏导数的函数。要求解的无约束最优化问题是:
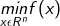
梯度下降法是一种迭代算法,选取适当的初值x(0),不断迭代更新x的值,进行目标函数的极小化,直到收敛。由于负梯度方向是使得函数值下降最快的方向,所以在迭代的每一步,以负梯度方向更新x的值,从而达到减少函数值的目的。f(x)具有一阶连续偏导数,若第k次迭代值为x(k),则可将f(x)在x(k)附近进行一阶泰勒展开:

gk是f(x)在x(k)附近的梯度。
2、牛顿法
牛顿法和拟牛顿法也是求解无约束最优化问题的常用方法。
牛顿法的基本思想是用迭代点xk处的一阶导数(梯度gk)和二阶倒数(海森矩阵Gk)对目标函数进行二次函数近似,然后把二次模型的极小点作为新的迭代点。牛顿法是迭代算法,每一步需要求解目标函数的海森矩阵的逆矩阵,计算比较复杂。拟牛顿法通过正定矩阵近似海森矩阵的逆矩阵或海森矩阵,简化了这一计算过程。
假设f(x)是具有二阶连续偏导数的函数。要求解的无约束最优化问题是:
假设f(x)具有二阶连续偏导数,若第k次迭代值为x(k),则可将f(x)在x(k)附近进行二阶泰勒展开:

g(k)是f(x)在x(k)附近的梯度,
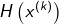
是海森矩阵

在点x(k)的值。函数f(x)有极值的必要条件是极值点处一阶导数为0,即梯度向量为0.特别是H矩阵为正定矩阵时,函数f(x)的极值为极小值。
牛顿法利用极小点的必要条件

每次迭代从x(k)开始,求目标函数的极小点,作为第k+1次 迭代值x(k+1)。假设x(k+1)满足:

代入f(x)公式,得出

其中

从而x(k+1)满足:

从而推出

但是这里需要求海森矩阵的逆矩阵,计算比较复杂,因此还有一些改进的基本想法。
3、拟牛顿法-BFGS算法
拟牛顿法的思想是考虑用一个n阶矩阵来代替海森矩阵,这就是拟牛顿法的基本思想。
拟牛顿法中最流行的是BFGS(Broyden-Fletcher-Goldfarb-Shanno)算法:
牛顿法的优点是具有二阶收敛速度,缺点是:
但当海森矩阵G(xk)=∇2f(x) 不正定时,不能保证所产生的方向是目标函数在xk处的下降方向。
特别地,当G(xk)奇异时,算法就无法继续进行下去。尽管修正牛顿法可以克服这一缺陷,但修正参数的取值很难把握,过大或过小都会影响到收敛速度。
牛顿法的每一步迭代都需要目标函数的海森矩阵G(xk),对于大规模问题其计算量是惊人的。
拟牛顿法的基本思想是用海森矩阵Gk的某个近似矩阵Bk取代Gk. Bk通常具有下面三个特点:
在某种意义下有Bk≈Gk ,使得相应的算法产生的方向近似于牛顿方向,确保算法具有较快的收敛速度。
对所有的k,Bk是正定的,从而使得算法所产生的方向是函数f在xk处下降方向。
矩阵Bk更新规则比较简单
输入:目标函数f(x),精度要求e

输出:f(x)的极小点x*.
(1)、选定初始点x(0),取B(0)为正定矩阵,置k=0;
(2)、计算gk = g(x(k)),如果小于e(阈值),则得到近似解x(k),否则继续转(3);
(3)、由B(k)*p(k) = -g(k)求出p(k);
(4)、一维搜索:求得λk使得:

(5)、计算x(k+1)

(6)、计算

若g(k+1)小于阈值,则停止计算,得到近似值,否则继续计算B(k+1)的值
(7)、置k = k+1,转(3)
参考文献
统计学习方法 李航
梯度-牛顿-拟牛顿优化算法和实现
假设f(x)是具有一阶连续偏导数的函数。要求解的无约束最优化问题是:
梯度下降法是一种迭代算法,选取适当的初值x(0),不断迭代更新x的值,进行目标函数的极小化,直到收敛。由于负梯度方向是使得函数值下降最快的方向,所以在迭代的每一步,以负梯度方向更新x的值,从而达到减少函数值的目的。f(x)具有一阶连续偏导数,若第k次迭代值为x(k),则可将f(x)在x(k)附近进行一阶泰勒展开:
gk是f(x)在x(k)附近的梯度。
2、牛顿法
牛顿法和拟牛顿法也是求解无约束最优化问题的常用方法。
牛顿法的基本思想是用迭代点xk处的一阶导数(梯度gk)和二阶倒数(海森矩阵Gk)对目标函数进行二次函数近似,然后把二次模型的极小点作为新的迭代点。牛顿法是迭代算法,每一步需要求解目标函数的海森矩阵的逆矩阵,计算比较复杂。拟牛顿法通过正定矩阵近似海森矩阵的逆矩阵或海森矩阵,简化了这一计算过程。
假设f(x)是具有二阶连续偏导数的函数。要求解的无约束最优化问题是:
假设f(x)具有二阶连续偏导数,若第k次迭代值为x(k),则可将f(x)在x(k)附近进行二阶泰勒展开:
g(k)是f(x)在x(k)附近的梯度,
是海森矩阵
在点x(k)的值。函数f(x)有极值的必要条件是极值点处一阶导数为0,即梯度向量为0.特别是H矩阵为正定矩阵时,函数f(x)的极值为极小值。
牛顿法利用极小点的必要条件
每次迭代从x(k)开始,求目标函数的极小点,作为第k+1次 迭代值x(k+1)。假设x(k+1)满足:
代入f(x)公式,得出
其中
从而x(k+1)满足:
从而推出
但是这里需要求海森矩阵的逆矩阵,计算比较复杂,因此还有一些改进的基本想法。
3、拟牛顿法-BFGS算法
拟牛顿法的思想是考虑用一个n阶矩阵来代替海森矩阵,这就是拟牛顿法的基本思想。
拟牛顿法中最流行的是BFGS(Broyden-Fletcher-Goldfarb-Shanno)算法:
牛顿法的优点是具有二阶收敛速度,缺点是:
但当海森矩阵G(xk)=∇2f(x) 不正定时,不能保证所产生的方向是目标函数在xk处的下降方向。
特别地,当G(xk)奇异时,算法就无法继续进行下去。尽管修正牛顿法可以克服这一缺陷,但修正参数的取值很难把握,过大或过小都会影响到收敛速度。
牛顿法的每一步迭代都需要目标函数的海森矩阵G(xk),对于大规模问题其计算量是惊人的。
拟牛顿法的基本思想是用海森矩阵Gk的某个近似矩阵Bk取代Gk. Bk通常具有下面三个特点:
在某种意义下有Bk≈Gk ,使得相应的算法产生的方向近似于牛顿方向,确保算法具有较快的收敛速度。
对所有的k,Bk是正定的,从而使得算法所产生的方向是函数f在xk处下降方向。
矩阵Bk更新规则比较简单
输入:目标函数f(x),精度要求e
输出:f(x)的极小点x*.
(1)、选定初始点x(0),取B(0)为正定矩阵,置k=0;
(2)、计算gk = g(x(k)),如果小于e(阈值),则得到近似解x(k),否则继续转(3);
(3)、由B(k)*p(k) = -g(k)求出p(k);
(4)、一维搜索:求得λk使得:
(5)、计算x(k+1)
(6)、计算
若g(k+1)小于阈值,则停止计算,得到近似值,否则继续计算B(k+1)的值
(7)、置k = k+1,转(3)
参考文献
统计学习方法 李航
梯度-牛顿-拟牛顿优化算法和实现

相关文章推荐
- easyui操作
- unity3D中协程和线程混合
- 根据wsdl生成一个webservice 的.cs文件
- 练习----基于FQDN的虚拟主机设置
- Java写入Excel
- viewpagerindicator+UnderlinePageIndicator+ viewpage切换
- java连接远程服务器之manyged-ssh2 (windows和linux)
- redis分布式锁
- Android冷启动白屏解析,带你一步步分析和解决问题
- 导入Excel后绑定GridView实例
- ubuntu修复系统
- 商品关联分析
- Nginx WEB服务器 win10启动不了
- [转]通过命令查看apache的位置
- Java写入Excel
- 275. H-Index II
- 设计模式C++实现(3)——适配器模式
- 【Java线程】锁机制:synchronized、Lock、Condition
- JVM学习笔记
- HDU 2589 正方形划分