MySQL中删除表中重复数据,只保留一条
2016-07-12 17:15
471 查看
以为通过命令直接删除就可以了,总是报错:
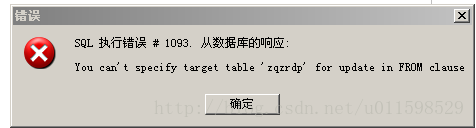
delete from test
where name in(select name from test as t having count(name)>1)
发现在这只能建立临时表格,方法1设计可行:
1. 首先先创建一个临时表,然后将author表中无重复的数据拎出来,放进临时表中。
create temporary table 表名
select distinct id,name,password
from author
然后将author表中的记录全部删除。
delete from author
最后将临时表中的记录插入author表中
insert into author (id,name,password)
select id,name,password
from 临时表
2.方法2直接使用语句:
delete from test
where name in(select t.name from (select name from test) as t having count(t.name)>1)
and name not in(select min(id) from(select id,name from test group by name)as tt having count(tt.name)>1)
发现总是删错数据,还未得到验证这种查询是否可行
delete from test
where name in(select name from test as t having count(name)>1)
发现在这只能建立临时表格,方法1设计可行:
1. 首先先创建一个临时表,然后将author表中无重复的数据拎出来,放进临时表中。
create temporary table 表名
select distinct id,name,password
from author
然后将author表中的记录全部删除。
delete from author
最后将临时表中的记录插入author表中
insert into author (id,name,password)
select id,name,password
from 临时表
2.方法2直接使用语句:
delete from test
where name in(select t.name from (select name from test) as t having count(t.name)>1)
and name not in(select min(id) from(select id,name from test group by name)as tt having count(tt.name)>1)
发现总是删错数据,还未得到验证这种查询是否可行

相关文章推荐
- MySQL中的integer 数据类型
- MySQL存储过程
- Android之获取手机上的图片和视频缩略图thumbnails
- mysql中int、bigint、smallint 和 tinyint的区别与长度
- mysql load data 导出、导入 csv
- source命令执行SQL脚本文件
- MySQL创建用户及权限控制
- MySQL管理数据表
- linux下mysql添加用户
- mysql procedure
- mysql触发器
- 数据库链接字符串查询网站
- MySQL 备份和恢复策略
- mac下安装mysql(转载)
- mysql 修改编码 Linux/Mac/Unix/通用(杜绝修改后无法启动的情况!)
- MySQL数据的导出、导入(mysql内部命令:mysqldump、mysql)
- mysql数据行转列
- Linux下修改MySQL编码的方法