MapReduce原理
2016-07-09 22:27
260 查看
MapReduce是一个分布式计算模型, google提出,主要用于搜索领域,解决海量数据的计算问题
MR由两个阶段组成:Map和Reduce,用户只需实现map()和reduce()两个函数,即可实现分布式计算,非常简单
这两个函数的形参是key、value对,表示函数的输入信息
hadoop1.x里面分jobtracker和tasktracker,2.x分resourcemanager和nodemanager
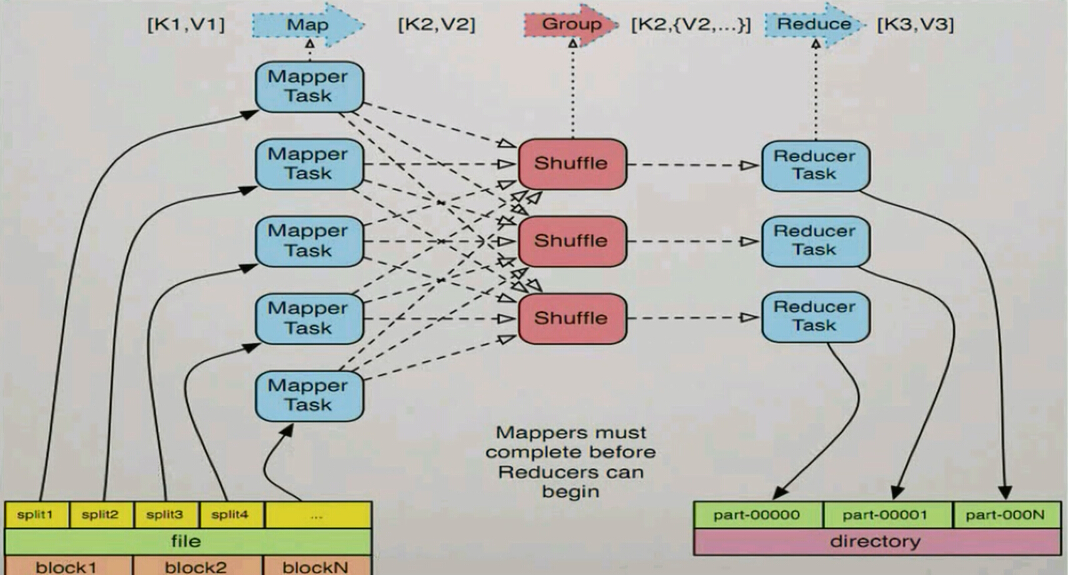
执行步骤:
1.map任务处理
读取输入文件内容,解析成key、value对,对输入文件的每一行,解析成key、value对。每一个键值对调用一次map函数
写自己的逻辑,对输入的key、value处理,转换成新的key、value输出
对输出的key、value分区
对不同分区的数据,按照key进行排序分组。相同key的value放到一个集合中
分组后的数据进行规约
2.reduce任务处理
对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点
对多个map任务的输出进行合并、排序。写reduce函数自己的逻辑,对输入的key、value进行处理,准换成新的key、value输出
把reduce的输出保存到文件中
MR由两个阶段组成:Map和Reduce,用户只需实现map()和reduce()两个函数,即可实现分布式计算,非常简单
这两个函数的形参是key、value对,表示函数的输入信息
hadoop1.x里面分jobtracker和tasktracker,2.x分resourcemanager和nodemanager
执行步骤:
1.map任务处理
读取输入文件内容,解析成key、value对,对输入文件的每一行,解析成key、value对。每一个键值对调用一次map函数
写自己的逻辑,对输入的key、value处理,转换成新的key、value输出
对输出的key、value分区
对不同分区的数据,按照key进行排序分组。相同key的value放到一个集合中
分组后的数据进行规约
2.reduce任务处理
对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点
对多个map任务的输出进行合并、排序。写reduce函数自己的逻辑,对输入的key、value进行处理,准换成新的key、value输出
把reduce的输出保存到文件中

相关文章推荐
- viewpager引导页
- sqlite3学习笔记——sqlite3中日期时间的自动增量
- 配置Struts2(以登录为例)
- 290. Word Pattern
- 技术布道者宣言
- zabbix_server
- nyoj35 表达式求值
- windows 下配置 Nginx 常见问题
- Bzoj2440 完全平方数
- hdu 5062(水题)
- 289. Game of Life
- 数据结构实验之链表七:单链表中重复元素的删除
- 51nod 1138 连续整数的和(数学公式)
- IBM xSeries 226 8648 系统参数
- 安装cocoapods遇到error: RPC failed; curl 56 SSLRead() return error -36问题
- Node起一个web服务器
- 河南省第九届ACM C题
- vim:修改光标的显示
- 2016sdau课程练习专题三 1012
- Centos6 rpm 安装mysql5.5