大数据分布式计算--hadoop
2016-07-07 23:10
363 查看
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop 核心项目提供了在低端硬件上构建云计算环境的基础服务,它也提供了运行在这个云中的软件所必须的 API 接口。
Hadoop 内核的两个基本部分是 MapReduce 框架,也就是云计算环境,和 HDFS分布式文件系统 。在 Hadoop 核心框架中,MapReduce 常被称为 mapred,HDFS 经常被称为 dfs。。HDFS为海量的数据提供了存储,MapReduce为海量的数据提供了计算。
MapReduce 的核心概念是把输入的数据分成不同的逻辑块, Map 任务首先并行的对每一块进行单独的处理。这些逻辑块的处理结果会被重新组合成不同的排序的集合,这些集合最后由 Reduce 任务进行处理。
HDFS分布式文件系统有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
参考:hadoop.appache.org
实验环境rhel6.5
主机server7,从机server8.server9 注:各机都必须域名相互解析。
安装及基本配置
各机创建uid为900 的hadoop用户,密码为redhat
Server7上,hadoop用户在/home/下。
#tar zxf hadoop-1.2.1.tar.gz -C hadoop
#cd hadoop
#ln -s hadoop-1.2.1/ hadoop
#sh jdk-6u32-linux-x64.bin //安装java
#ln -s jdk-1.6.32 java
#vim .bash_profile //配置path
export JAVA_HOME=/home/hadoop/java
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$HOME/bin:$JAVA_HOME/bin
#source .bash_profile
#echo $JAVA_HOME
显示/home/hadoop/java
#cd hadoop/conf
#vim hadoop-env.sh
修改exprot JAVA_HOME=/home/hadoop/java
#mkdir ../input
#cp *.xml ../input //创建分布式文件系统
#cd ..
#bin/hadoop jar hadoop-examples-1.2.1.jar

列出了hadoop-example-1.2.1jar对input操作的相关参数,如grep查找,sort排序,wordcount计数等。
#bin/hadoop jar hadoop-examples-1.2.1.jar grep input output 'dfs[a-z.]+' //查找inout中文件名开头为dfs后面为小写英文的文件,将结果存入自动生成的output文件夹中
#cd output/
#ls
#cat *
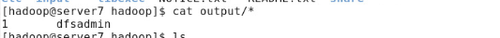
再介绍下hadoop的三种工作模式
单机模式(standalone)
单机模式是Hadoop的默认模式,当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选择了最小配置。在这种默认模式下所有3个XML文件均为空。当配置文件为空时,Hadoop会完全运行在本地。因为不需要与其他节点交互,单机模式就不使用HDFS,也不加载任何Hadoop的守护进程。该模式主要用于开发调试MapReduce程序的应用逻辑。
伪分布模式(Pseudo-Distributed Mode)
伪分布模式在“单节点集群”上运行Hadoop,其中所有的守护进程都运行在同一台机器上。该模式在单机模式之上增加了代码调试功能,允许你检查内存使用情况,HDFS输入输出,以及其他的守护进程交互。
完全分布式模式
Hadoop守护进程运行在一个集群上。
上面的操作为单机模式。
Hadoop分布式部署
结构:
主节点包括名称节点(namenode)、从属名称节点(secondarynamenode)和 jobtracker 守护进程(即所谓的主守护进程)以及管理集群所用的实用程序和浏览器。
从节点包括 tasktracker 和数据节点(从属守护进程)。两种设置的不同之处在于,主节点包括提供 Hadoop 集群管理和协调的守护进程,而从节点包括实现Hadoop 文件系统(HDFS )存储功能和 MapReduce 功能(数据处理功能)的守护进程。
每个守护进程在 Hadoop 框架中的作用:
namenode 是 Hadoop 中的主服务器,它管理文件系统名称空间和对集群中存储的文件的访问。
secondary namenode ,它不是namenode 的冗余守护进程,而是提供周期检查点和清理任务。
在每个 Hadoop 集群中可以找到一个 namenode 和一个 secondary namenode。
datanode 管理连接到节点的存储(一个集群中可以有多个节点)。每个存储数据的节点运行一个 datanode 守护进程。
每个集群有一个 jobtracker ,它负责调度 datanode 上的工作。
每个 datanode 有一个tasktracker,它们执行实际工作。
jobtracker 和 tasktracker 采用主-从形式,jobtracker 调度datanode 分发工作,而 tasktracker 执行任务。jobtracker 还检查请求的工作,如果一个datanode 由于某种原因失败,jobtracker 会重新调度以前的任务。
下面实现伪分布式
为了方便,进行ssh免密码设置。
Server7上hadoop用户。
#ssh-keygen
#ssh-copy-id localhost
#ssh localhost //免密码登陆本机
修改配置文件:
#cd hadoop/conf
#vim core-site.xml
在<configuration>下面添加
<property>
<name>fs.default.name</name>
<value>hdfs://172.25.0.7:9000</value>
</property> //指定namenode
#vim mapred-site.xml
在<configuration>下面添加
<property>
<name>mapred.job.tracker</name>
<value>172.25.0.7:9001</value>
</property> //指定 jobtracker
#vim hdfs-site.xml
在<configuration>下面添加
<property>
<name>dfs.replication</name>
<value>1</value>
</property> //指定文件保存的副本数,由于是伪分布式所以副本就是本机1个。
#cd ..
#bin/hadoop namenode -format //格式化namenode
#bin/start-dfs.sh //启动hdfs
#jps //查看进程

可看到secondarynamenode,namenode,datanode都以启动。Namenode与datanode在同一台机器上,所以是伪分布式。
#bin/start-mapred.sh.sh //启动mapreduce
#bin/hadoop fs -put input test //上传input到hdfs并在hdfs中更名为test
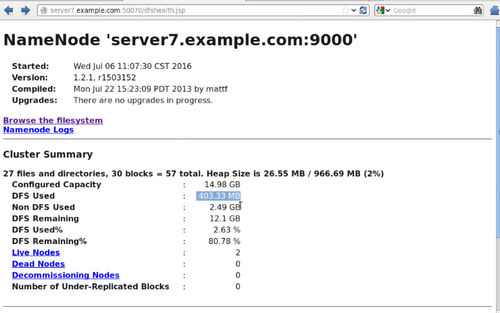
浏览 NameNode 和 JobTracker 的网络接口,它们的地址默认为:
NameNode – http://172.25.0.7:50070/ JobTracker – http://172.25.0.7:50030/ 查看namenode
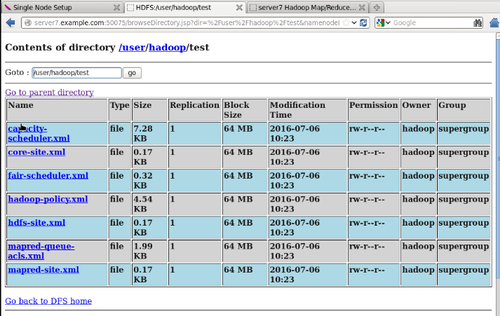
#bin/hadoop fs -ls test //列出hdfs中test目录下的文件

Web上查看test下的文件
下面实现完全分布式模式
主从机上都安装nfs-utils并启动rpcbind服务(主要是在nfs共享时候负责通知客户端,服务器的nfs端口号的。简单理解rpc就是一个中介服务),从机通过nfs直接使用hadoop免去安装配置。
在server7上,启动nfs服务
#vim /etc/exports
/home/hadoop *(rw,all_squash,anonuid=900,anongid=900
//共享hadoop,对登陆用户指定id,用户以uid为900的用户登陆
server8,9上
#mount 172.25.0.7:/home/hadoop /hooem/hadoop/ //挂载共享目录
server7上,hadoop用户,更改hadoop/conf下的hdfs-site,将副本数由1改为2。
#cd hadoop/conf
#vim slave 添加从机
172.25.0.8
172.25.0.9
#vim master 设置主机
172.25.0.7
启动完全分布式模式前要格式化伪分布式文件系统
#cd ..
#bin/stop-all.sh //停止jobtracker,namenode,secondarynamenode
#bin/hadoop-daemon.sh stop tasktracker
#bin/hadoop-daemon.sh stop datanode //停止tasktracker,datanode,
#bin/hadoop namenode -format
#bin/start-dfs.sh 显示server8,server9连接。

#bin/start-mapred.sh
新增了jobtracker进程
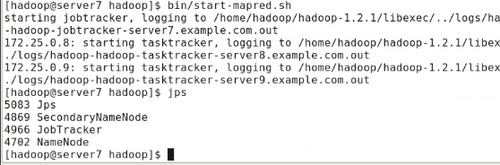
server8上,jps可看到三个进程jps,datanode,tasktracker

从机可以上传,查询等
#bin/hadoop fs -put input test
#bin/hadoop jar hadoop-example-1.2.1.jar grep test out ‘dfs[a-z]+’
server7上,
#bin/hadoop dfsadmin -report //显示hdfs信息
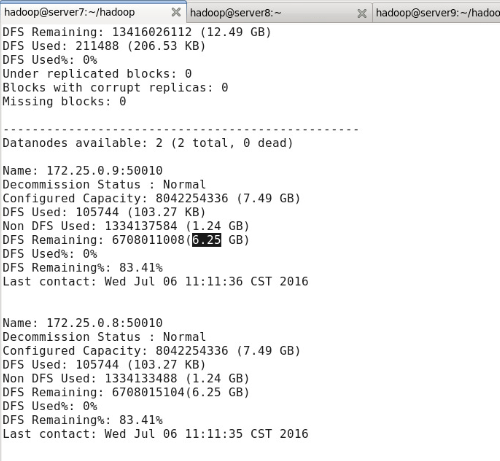
由于hadoop下未增加文件,所以dfs used%均为0%
#dd if=/dev/zero of=bigfile bs=1M count=200
#bin/hadoop fs -put bigfile test
在web上看到dfs used为403.33MB(两从机,每个为200MB)

注:有时候操作错误导致hadoop进入安全模式,无法进行上传等操作

只需运行下行指令即可
#bin/hadoop dfsadmin -safemode leave

hadoop支持实时扩展,可在线添加从机。
新增从机server10。安装nfs-utils,启动rpcbind服务。添加uid900的hadoop用户,挂载server7的hadoop并在hadoop/conf下的slaves添加172.25.0.10。
注:必须在添加server10之前在主从机上添加server10的hostname解析。
server10上,hadoop用户
#bin/hadoop-daemon.sh start datanode
#bin/hadoop-daemon.sh start tasktracker
server7上,
#bin/hadoop dfsadmin -report
可看到server10的信息
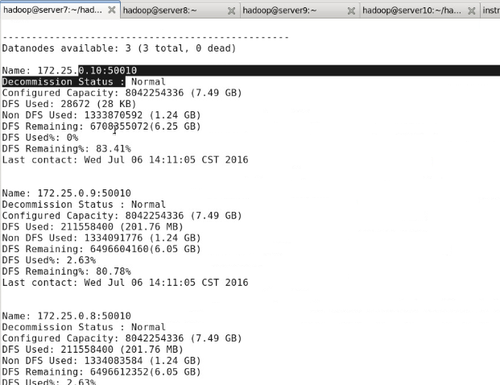
可看到server10 dfs used为0,可以将server9的数据移到server10中。
数据迁移:
数据迁移是将很少使用或不用的文件移到辅助存储系统的过程。
hadoop 在线删除 server9 datanode 节点可实现数据迁移:
#bin/hadoop-daemon.sh stop tasktracker //在做数据迁移时,此节点不要参与 tasktracker,否则会出现异常
在 master 上修改 conf/mapred-site.xml
在</property>下面添加
<property>
<name>dfs.hosts.exclude</name>
<value>/home/hadoop/hadoop-1.0.4/conf/datanode-excludes</value>
</property>
在conf下创建datanode-excludes,添加需要删除的主机,一行一个
#vim datanode-excludes
172.25.0.9 //删除节点server9
#cd ..
#bin/hadoop dfsadmin -refreshNodes //在线刷新节点
#bin/hadoop dfsadmin -report
可看到server9 状态:Decommission in progress,

若要在线删除tasktracker节点
在server7上修改 conf/mapred-site.xml
<property>
<name>mapred.hosts.exclude</name>
<value>/home/hadoop/hadoop-1.0.4/conf/tasktracker-excludes</value></property>
创建 tasktracker-excludes 文件,并添加需要删除的主机名,一行一个
server9.example.com
#bin/hadoop mradmin -refreshNodes
等此节点的状态显示为 Decommissioned,数据迁移完成,可以安全关闭了。
hadoop1.2.1版本过低,jobtracker的调度能力不强,当slvers过多时容易成为瓶颈。使用新版本2.6.4是个不错的选择。
停掉进程,删除文件:
server7上
#bin/stop-all.sh
#cd /home/hadoop
#rm -fr hadoop java hadoop-1.2.1 java1.6.32
#rm -fr /tmp/*
从机上
#bin/hadoop-daemon.sh stop datanode
#bin/hadoop-daemon.sh stop tasktracker
#rm -fr /tmp/*
下面操作与上面基本相同
server7上,/home/hadoop/下hadoop用户
#tar zxf jdk-7u79-linux-x64.tar.gz -C /home/hadoop/
#ln -s jdk1.7.0.79 java
#tar zxf hadoop-2.6.4.tar.gz
#ln -s hadoop-2.6.4 hadoop
#cd hadoop/etc/hadoop
#vim hadoop-env.sh
export JAVA_HOME=/home/hadoop/java
export HADOOP_PREFIX=/home/hadoop/hadoop
#cd /home/hadoop/hadoop
#mkdir input
#cp etc/hadoop/*.xml input
#bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar grep input output ‘dfs[a-z.]+’
#cat output/*
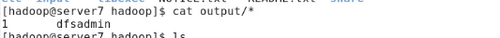
grep编译时会有warning,当集群大时可能会出现问题。需要添加hadoop-native。
#tar -xf hadoop-native-64.2.6.0.tar -C hadoop/lib/native/
#bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar grep input output ‘dfs[a-z.]+’
再编译没有warning
#cd etc/hadoop
#vim slaves
172.25.0.8
172.25.0.9
#vim etc/hadoop/core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://172.25.0.7:9000</value>
</property>
#vim hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
#bin/hdfs namenode -format
#sbin/start-dfs.sh
#jps
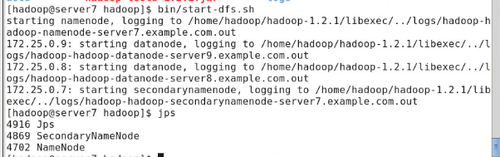
#ps -ax 可看到namenode与secondarynamenode进程
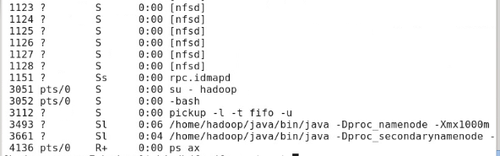
#bin/hdfs dfs -mkdir /user/hadoop
#bin/hdfs dfs -put input/ test
web上可看到input以上传。
MapReduce 的 JobTracker/TaskTracker 机制需要大规模的调整来修复它在可扩展性,内存消耗,线程模型,可靠性和性能上的缺陷
为从根本上解决旧 MapReduce 框架的性能瓶颈,促进 Hadoop 框架的更长远发展,从 0.23.0 版本开始,Hadoop 的 MapReduce 框架完全重构,发生了根本的变化。新的 Hadoop MapReduce 框架命名为 MapReduceV2 或者叫 Yarn
#vim etc/hadoop/yarn-site.xml
< property>
<name>yarn.resourcemanager.hostname</name>
<value>server7.example.com</value>
</property>
#sbin/start-yarn.sh
#jps
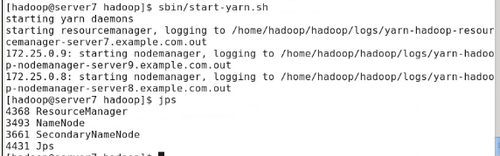
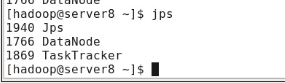
server8可看到进程已启动
Hadoop 核心项目提供了在低端硬件上构建云计算环境的基础服务,它也提供了运行在这个云中的软件所必须的 API 接口。
Hadoop 内核的两个基本部分是 MapReduce 框架,也就是云计算环境,和 HDFS分布式文件系统 。在 Hadoop 核心框架中,MapReduce 常被称为 mapred,HDFS 经常被称为 dfs。。HDFS为海量的数据提供了存储,MapReduce为海量的数据提供了计算。
MapReduce 的核心概念是把输入的数据分成不同的逻辑块, Map 任务首先并行的对每一块进行单独的处理。这些逻辑块的处理结果会被重新组合成不同的排序的集合,这些集合最后由 Reduce 任务进行处理。
HDFS分布式文件系统有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
参考:hadoop.appache.org
实验环境rhel6.5
主机server7,从机server8.server9 注:各机都必须域名相互解析。
安装及基本配置
各机创建uid为900 的hadoop用户,密码为redhat
Server7上,hadoop用户在/home/下。
#tar zxf hadoop-1.2.1.tar.gz -C hadoop
#cd hadoop
#ln -s hadoop-1.2.1/ hadoop
#sh jdk-6u32-linux-x64.bin //安装java
#ln -s jdk-1.6.32 java
#vim .bash_profile //配置path
export JAVA_HOME=/home/hadoop/java
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$HOME/bin:$JAVA_HOME/bin
#source .bash_profile
#echo $JAVA_HOME
显示/home/hadoop/java
#cd hadoop/conf
#vim hadoop-env.sh
修改exprot JAVA_HOME=/home/hadoop/java
#mkdir ../input
#cp *.xml ../input //创建分布式文件系统
#cd ..
#bin/hadoop jar hadoop-examples-1.2.1.jar
列出了hadoop-example-1.2.1jar对input操作的相关参数,如grep查找,sort排序,wordcount计数等。
#bin/hadoop jar hadoop-examples-1.2.1.jar grep input output 'dfs[a-z.]+' //查找inout中文件名开头为dfs后面为小写英文的文件,将结果存入自动生成的output文件夹中
#cd output/
#ls
#cat *
再介绍下hadoop的三种工作模式
单机模式(standalone)
单机模式是Hadoop的默认模式,当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选择了最小配置。在这种默认模式下所有3个XML文件均为空。当配置文件为空时,Hadoop会完全运行在本地。因为不需要与其他节点交互,单机模式就不使用HDFS,也不加载任何Hadoop的守护进程。该模式主要用于开发调试MapReduce程序的应用逻辑。
伪分布模式(Pseudo-Distributed Mode)
伪分布模式在“单节点集群”上运行Hadoop,其中所有的守护进程都运行在同一台机器上。该模式在单机模式之上增加了代码调试功能,允许你检查内存使用情况,HDFS输入输出,以及其他的守护进程交互。
完全分布式模式
Hadoop守护进程运行在一个集群上。
上面的操作为单机模式。
Hadoop分布式部署
结构:
主节点包括名称节点(namenode)、从属名称节点(secondarynamenode)和 jobtracker 守护进程(即所谓的主守护进程)以及管理集群所用的实用程序和浏览器。
从节点包括 tasktracker 和数据节点(从属守护进程)。两种设置的不同之处在于,主节点包括提供 Hadoop 集群管理和协调的守护进程,而从节点包括实现Hadoop 文件系统(HDFS )存储功能和 MapReduce 功能(数据处理功能)的守护进程。
每个守护进程在 Hadoop 框架中的作用:
namenode 是 Hadoop 中的主服务器,它管理文件系统名称空间和对集群中存储的文件的访问。
secondary namenode ,它不是namenode 的冗余守护进程,而是提供周期检查点和清理任务。
在每个 Hadoop 集群中可以找到一个 namenode 和一个 secondary namenode。
datanode 管理连接到节点的存储(一个集群中可以有多个节点)。每个存储数据的节点运行一个 datanode 守护进程。
每个集群有一个 jobtracker ,它负责调度 datanode 上的工作。
每个 datanode 有一个tasktracker,它们执行实际工作。
jobtracker 和 tasktracker 采用主-从形式,jobtracker 调度datanode 分发工作,而 tasktracker 执行任务。jobtracker 还检查请求的工作,如果一个datanode 由于某种原因失败,jobtracker 会重新调度以前的任务。
下面实现伪分布式
为了方便,进行ssh免密码设置。
Server7上hadoop用户。
#ssh-keygen
#ssh-copy-id localhost
#ssh localhost //免密码登陆本机
修改配置文件:
#cd hadoop/conf
#vim core-site.xml
在<configuration>下面添加
<property>
<name>fs.default.name</name>
<value>hdfs://172.25.0.7:9000</value>
</property> //指定namenode
#vim mapred-site.xml
在<configuration>下面添加
<property>
<name>mapred.job.tracker</name>
<value>172.25.0.7:9001</value>
</property> //指定 jobtracker
#vim hdfs-site.xml
在<configuration>下面添加
<property>
<name>dfs.replication</name>
<value>1</value>
</property> //指定文件保存的副本数,由于是伪分布式所以副本就是本机1个。
#cd ..
#bin/hadoop namenode -format //格式化namenode
#bin/start-dfs.sh //启动hdfs
#jps //查看进程
可看到secondarynamenode,namenode,datanode都以启动。Namenode与datanode在同一台机器上,所以是伪分布式。
#bin/start-mapred.sh.sh //启动mapreduce
#bin/hadoop fs -put input test //上传input到hdfs并在hdfs中更名为test
浏览 NameNode 和 JobTracker 的网络接口,它们的地址默认为:
NameNode – http://172.25.0.7:50070/ JobTracker – http://172.25.0.7:50030/ 查看namenode
#bin/hadoop fs -ls test //列出hdfs中test目录下的文件
Web上查看test下的文件
下面实现完全分布式模式
主从机上都安装nfs-utils并启动rpcbind服务(主要是在nfs共享时候负责通知客户端,服务器的nfs端口号的。简单理解rpc就是一个中介服务),从机通过nfs直接使用hadoop免去安装配置。
在server7上,启动nfs服务
#vim /etc/exports
/home/hadoop *(rw,all_squash,anonuid=900,anongid=900
//共享hadoop,对登陆用户指定id,用户以uid为900的用户登陆
server8,9上
#mount 172.25.0.7:/home/hadoop /hooem/hadoop/ //挂载共享目录
server7上,hadoop用户,更改hadoop/conf下的hdfs-site,将副本数由1改为2。
#cd hadoop/conf
#vim slave 添加从机
172.25.0.8
172.25.0.9
#vim master 设置主机
172.25.0.7
启动完全分布式模式前要格式化伪分布式文件系统
#cd ..
#bin/stop-all.sh //停止jobtracker,namenode,secondarynamenode
#bin/hadoop-daemon.sh stop tasktracker
#bin/hadoop-daemon.sh stop datanode //停止tasktracker,datanode,
#bin/hadoop namenode -format
#bin/start-dfs.sh 显示server8,server9连接。
#bin/start-mapred.sh
新增了jobtracker进程
server8上,jps可看到三个进程jps,datanode,tasktracker
从机可以上传,查询等
#bin/hadoop fs -put input test
#bin/hadoop jar hadoop-example-1.2.1.jar grep test out ‘dfs[a-z]+’
server7上,
#bin/hadoop dfsadmin -report //显示hdfs信息
由于hadoop下未增加文件,所以dfs used%均为0%
#dd if=/dev/zero of=bigfile bs=1M count=200
#bin/hadoop fs -put bigfile test
在web上看到dfs used为403.33MB(两从机,每个为200MB)
注:有时候操作错误导致hadoop进入安全模式,无法进行上传等操作
只需运行下行指令即可
#bin/hadoop dfsadmin -safemode leave
hadoop支持实时扩展,可在线添加从机。
新增从机server10。安装nfs-utils,启动rpcbind服务。添加uid900的hadoop用户,挂载server7的hadoop并在hadoop/conf下的slaves添加172.25.0.10。
注:必须在添加server10之前在主从机上添加server10的hostname解析。
server10上,hadoop用户
#bin/hadoop-daemon.sh start datanode
#bin/hadoop-daemon.sh start tasktracker
server7上,
#bin/hadoop dfsadmin -report
可看到server10的信息
可看到server10 dfs used为0,可以将server9的数据移到server10中。
数据迁移:
数据迁移是将很少使用或不用的文件移到辅助存储系统的过程。
hadoop 在线删除 server9 datanode 节点可实现数据迁移:
#bin/hadoop-daemon.sh stop tasktracker //在做数据迁移时,此节点不要参与 tasktracker,否则会出现异常
在 master 上修改 conf/mapred-site.xml
在</property>下面添加
<property>
<name>dfs.hosts.exclude</name>
<value>/home/hadoop/hadoop-1.0.4/conf/datanode-excludes</value>
</property>
在conf下创建datanode-excludes,添加需要删除的主机,一行一个
#vim datanode-excludes
172.25.0.9 //删除节点server9
#cd ..
#bin/hadoop dfsadmin -refreshNodes //在线刷新节点
#bin/hadoop dfsadmin -report
可看到server9 状态:Decommission in progress,
若要在线删除tasktracker节点
在server7上修改 conf/mapred-site.xml
<property>
<name>mapred.hosts.exclude</name>
<value>/home/hadoop/hadoop-1.0.4/conf/tasktracker-excludes</value></property>
创建 tasktracker-excludes 文件,并添加需要删除的主机名,一行一个
server9.example.com
#bin/hadoop mradmin -refreshNodes
等此节点的状态显示为 Decommissioned,数据迁移完成,可以安全关闭了。
hadoop1.2.1版本过低,jobtracker的调度能力不强,当slvers过多时容易成为瓶颈。使用新版本2.6.4是个不错的选择。
停掉进程,删除文件:
server7上
#bin/stop-all.sh
#cd /home/hadoop
#rm -fr hadoop java hadoop-1.2.1 java1.6.32
#rm -fr /tmp/*
从机上
#bin/hadoop-daemon.sh stop datanode
#bin/hadoop-daemon.sh stop tasktracker
#rm -fr /tmp/*
下面操作与上面基本相同
server7上,/home/hadoop/下hadoop用户
#tar zxf jdk-7u79-linux-x64.tar.gz -C /home/hadoop/
#ln -s jdk1.7.0.79 java
#tar zxf hadoop-2.6.4.tar.gz
#ln -s hadoop-2.6.4 hadoop
#cd hadoop/etc/hadoop
#vim hadoop-env.sh
export JAVA_HOME=/home/hadoop/java
export HADOOP_PREFIX=/home/hadoop/hadoop
#cd /home/hadoop/hadoop
#mkdir input
#cp etc/hadoop/*.xml input
#bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar grep input output ‘dfs[a-z.]+’
#cat output/*
grep编译时会有warning,当集群大时可能会出现问题。需要添加hadoop-native。
#tar -xf hadoop-native-64.2.6.0.tar -C hadoop/lib/native/
#bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar grep input output ‘dfs[a-z.]+’
再编译没有warning
#cd etc/hadoop
#vim slaves
172.25.0.8
172.25.0.9
#vim etc/hadoop/core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://172.25.0.7:9000</value>
</property>
#vim hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
#bin/hdfs namenode -format
#sbin/start-dfs.sh
#jps
#ps -ax 可看到namenode与secondarynamenode进程
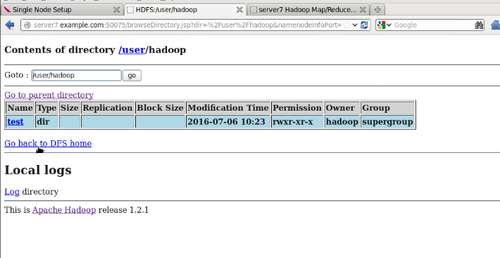
#bin/hdfs dfs -mkdir /user/hadoop
#bin/hdfs dfs -put input/ test
web上可看到input以上传。
MapReduce 的 JobTracker/TaskTracker 机制需要大规模的调整来修复它在可扩展性,内存消耗,线程模型,可靠性和性能上的缺陷
为从根本上解决旧 MapReduce 框架的性能瓶颈,促进 Hadoop 框架的更长远发展,从 0.23.0 版本开始,Hadoop 的 MapReduce 框架完全重构,发生了根本的变化。新的 Hadoop MapReduce 框架命名为 MapReduceV2 或者叫 Yarn
#vim etc/hadoop/yarn-site.xml
< property>
<name>yarn.resourcemanager.hostname</name>
<value>server7.example.com</value>
</property>
#sbin/start-yarn.sh
#jps
server8可看到进程已启动

相关文章推荐
- 详解HDFS Short Circuit Local Reads
- Hadoop_2.1.0 MapReduce序列图
- 使用Hadoop搭建现代电信企业架构
- 单机版搭建Hadoop环境图文教程详解
- hadoop常见错误以及处理方法详解
- hadoop 单机安装配置教程
- hadoop的hdfs文件操作实现上传文件到hdfs
- hadoop实现grep示例分享
- Apache Hadoop版本详解
- linux下搭建hadoop环境步骤分享
- java连接hdfs ha和调用mapreduce jar示例
- java实现将ftp和http的文件直接传送到hdfs
- hadoop client与datanode的通信协议分析
- hadoop中一些常用的命令介绍
- Hadoop单机版和全分布式(集群)安装
- 用PHP和Shell写Hadoop的MapReduce程序
- hadoop map-reduce中的文件并发操作
- Hadoop1.2中配置伪分布式的实例
- hadoop上传文件功能实例代码