编译原理-LR(0)分析法
2016-07-07 23:08
330 查看
一、课程设计内容
1.1 功能需求
根据标准规范族构造LR(0)分析表;设计数据结构(领接矩阵)存储NFA,DFA。并能够对输入串进行判别是否正确。
1.2 开发环境
Visual Studio 2015,控制台应用程序
1.3 前置条件
熟悉LR(0)分析法的过程 熟悉构造NFA 熟悉将NFA转换成为DFA 熟悉通过DFA构造LR分析表
二、数据结构设计
2.1 结构体
2.1.1 NFA结点数据结构typedef struct wenfanode
{
int num; //文法的NFA编号
char data[MAXSIZE]; //文法内容
bool state; //判断文法是否已经被加入DFA
};2.1.2 栈操作
typedef struct Stack
{
int data[MAXSIZE]; //存放具体内容
int top; //栈顶指针
};三、程序总体设计
3.1 输入文件
3.1.1 文法输入文件wenfa.txt文件内容如下: S->E E->aA A->cA A->d E->bB B->cB B->d
3.1.2 输入串输入文件input.txt
输入串内容如下: acd#
四、重点函数设计
4.1 参数说明
对程序中使用到的函数参数意义在此进行说明:函数:void AddChar2Str(const char str[], char str_after[], int i, int k); 功能:在字符串的某位置加一个字符'.' 参数:str为原字符串,str_after为修改后的字符串,i要插入的位置,k为str的长度 函数:int find_node(char ch, int a[]); 功能:查找以ch开头,右部首为点的文法,将文法的编号存入数组a中,返回个数 参数:ch为要查询的文法的开头字符,a[]保存满足条件的文法编号 返回值:找到满足要求文法的个数 函数:void add_state(int to, int from); 功能:将经from连接的结点添加到to可以连接的节点中去 参数:from源节点编号,to目标结点编号 函数:char* need_protocol(int point); 功能:判断结点中的点有没有规约项 参数:point要判断的结点的编号 返回值:返回需要规约的文法产生式
4.2 部分函数说明
4.2.1 给文法加点
void AddDot()
{
for (int now_wenfa = 0; now_wenfa < g_num_wenfa; now_wenfa++) //对每一个文法
{
int k = 0; //记录最后一个字符的位置
for (int j = MAXSIZE - 1; j > 2; j--) //文法从最后向前搜索最后一个字符
{
if (WenFa[now_wenfa][j] != 0) //该文法当前字符为空
{
k = j;
break;
}
}
//加点
for (int j = 3; j <= k + 1; j++) //加点的位置
{
AddChar2Str(WenFa[now_wenfa], str_after, j, k);
wenfanode* temp = (wenfanode*)malloc(sizeof(wenfanode));
strcpy(temp->data, str_after);
temp->num = g_wenfa_dot;
temp->state = false;
LRWenFa[g_wenfa_dot++] = temp;
}
}
g_wenfa_dot--; //因为多加了一个
}说明:函数对每一个文法产生式首先寻找该产生式最后一个字符的位置,并用临时变量K来记录。对于这个产生式来说,推出符号后的每一位上都应该加点,所以循环从3开始,3是推出符号右部的第一个位置。对每一加点的位置加点,得到加点的产生式,使用一个结构体存储这些产生式。为了后续可以随机查找,这里使用一个结构体数组,数组的每一个元素都是一个NFA结点,它的data就是加点后的产生式,并未这个产生式分配一个编号,供以后使用。这个在结构体中添加了state域,为了标志这个结点是不是已经被包含在一个DFA结点中了,这么做是为了以后构造表更加方便。
4.2.2 构造NFA,使用邻接矩阵存储
void make_NFA()
{
int a[MAXSIZE]; //记录ε弧要连接的结点编号
init_NFA(); //初始化NFA
for (int i = 1; i <= g_wenfa_dot; i++) //对每一个加点的文法链
{
int pos_point = find_pos_point(LRWenFa[i]->data); //找点的位置
NFA[i][i + 1] = LRWenFa[i]->data[pos_point + 1]; //将该节点和下一个节点连接
//构造ε弧
if (isVN(LRWenFa[i]->data[pos_point + 1])) //点之后紧跟着非终结符
{
int j = find_node(LRWenFa[i]->data[pos_point + 1], a);
for (int k = 0; k < j; k++)
{
NFA[i][a[k]] = '*';
}
}
}
}说明:构造NFA分为两个大的部分,第一个部分就是如果两个加点的产生式所加点的位置只差一个字符,就在这两个产生式对应的两个NFA结点之间添加一条该字符的弧线,表示前一个节点通过该字符就可以连接到后一个结点。第二大部分就是将这些孤立的链连接起来,如果一个产生式点之后紧跟着一个非终结符,就将该非终结符,就将改产生式与该非终结符能够推出的产生式之间连接一条ε弧。
4.2.3 构造DFA
void make_DFA()
{
int k = 0;
init_DFA();
for (int i = 1; i <= g_wenfa_dot; i++)
{
if (LRWenFa[i]->state == false) //对每一个未被选入DFA的NFA结点
{
//将自己加入DFA结点
k = 0;
wenfanode *temp = (wenfanode*)malloc(sizeof(wenfanode));
strcpy(temp->data, LRWenFa[i]->data);
DFA_node[i][k++] = temp;
LRWenFa[i]->state = true;
for (int j = 1; j <= g_wenfa_dot; j++)
{
if (NFA[i][j] == '*') //有ε弧
{
wenfanode *temp = (wenfanode*)malloc(sizeof(wenfanode));
strcpy(temp->data, LRWenFa[j]->data);
temp->num = j;
DFA_node[i][k++] = temp;
LRWenFa[j]->state = true;
//修改DFA
add_state(i, j);
}
}
}
}
}说明:对每一个NFA源结点,首先将自己加入到DFA结点中,再去寻找该NFA结点有ε弧连接的目标结点,将这些目标结点和源NFA结点一起保存在数据结构中,一起组成一个新的DFA结点,并将目标结点能够连接到的点添加到DFA表中。这些包含在其中的结点state域都为true,再后续的NFA合并中不参加运算。
4.2.4 填充LR分析表
void fill_LRtable()
{
char *temp_ch = (char*)malloc(2 * sizeof(char)); //用来存放数据
init_LR_Table();
int i, j;
//访问DFA
for (i = 1; i <= g_wenfa_dot; i++)
{
char *str;
if (str = need_protocol(i))
{
int num = find_wenfa(str);
sprintf(temp_ch, "%d", num);
string temp = "r";
temp += temp_ch;
for (j = 0; j < NUM_VT; j++)
{
ACTION[i][j] = temp;
}
}
else
{
for (j = 1; j <= g_wenfa_dot; j++)
{
char ch = DFA[i][j];
if (ch != ' ') //有内容
{
if (isVN(ch) == true) //是非终结符
{
GOTO[i][VN2int(ch)] = j;
}
else //是终结符
{
sprintf(temp_ch, "%d", j);
string temp = "s";
temp += temp_ch;
ACTION[i][VT2int(ch)]= temp;
}
}
}
}
}
}说明:对DFA中的每一个节点判断它是否需要规约,如果需要规约就查找规约产生式的编号,并创建一个string类型的变量写入r在加上产生式编号。最后将这个编号写到这个要规约产生式所对应ACTION表的一行中。如果不需要规约,就查看DFA表,如果DFA中对应非终结符,就修改GOTO表;若是终结符,就创建string类型临时变量,写入s加上产生式编号,写到ACTION表中去。
五、实验结果
5.1 文法处理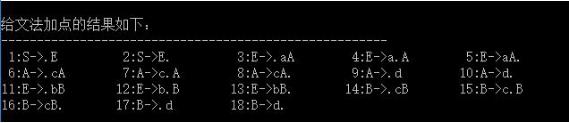
上图是文法产生式加点之后的输出,将文法加点后形成NFA的结点,并对结点进行编号。
5.2 NFA
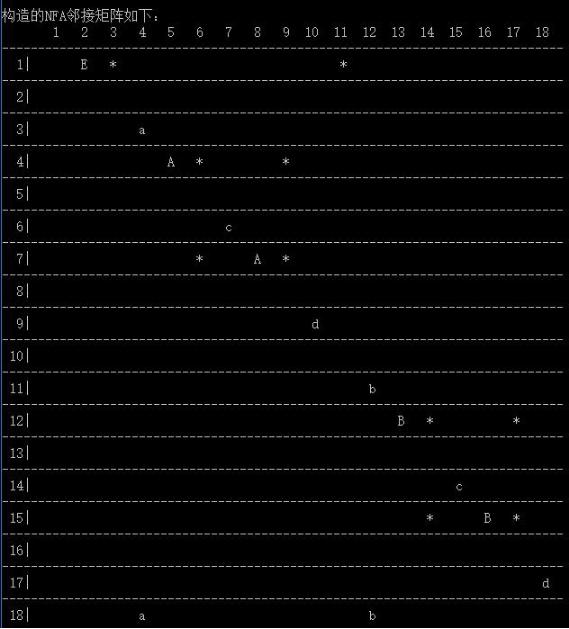
图中的行列的数字代表NFA的结点序号,具体对应哪个结点可以看图1,表中的字母表示行结点通过该子母可以到达列结点,图中的*代表两个结点之间存在一条ε弧。图是使用邻接矩阵进行存储的。
5.3 DFA

DFA图中的结点使用NFA结点的编号,但是这里的编号已经和NFA中的编号有区别了,这里的编号是DFA中的编号,每一个编号是由若干的NFA结点组成新的结点,只是使用了旧的编号而已,方便存储。图中出现了很多没有用到的结点,那些是被合并的结点,它们本应该不出现在这张表中,但是为了方便,这里还是没有进行结点编号的重新整理,直接使用旧编号。
5.4 LR分析表

可以看出,程序一个很大的优点就是有很直观的数据显示,这样的表格输出给人清楚地展示处理的结果。
5.5 规约过程

本来程序使用c++封装好的栈对象来实现分析过程,但是封装的对象中只有对栈顶的相关操作,并不能直观的输出栈的所有元素,使得归约过程不清楚。为了有更清楚的过程显示,程序中定义栈结构体又自己写了栈操作,这样一来就可以显示栈中的所有数据,每一步的归约过程十分清楚。
六、源程序
/*
*功能:LR(0)分析方法
*作者:王文堃
*创建时间:2016/6/14
*/
/*
----------------任务分解--------------------
任务一:确定文法G的LR0项目,对文法加'.'
任务二:构造NFA
任务三:构造DFA
任务四:构造LR(0)分析表
任务五:规约
*/
#include <iostream>
#include <string>
#include <malloc.h>
using namespace std;
#define LR_MAXSIZE 20
#define MAXSIZE 10
#define NUM 20
#define NUM_VN 4
#define NUM_VT 5
/*---------------------------------数据结构----------------------------------*/
//NFA结点数据结构
typedef struct wenfanode { int num; //文法的NFA编号 char data[MAXSIZE]; //文法内容 bool state; //判断文法是否已经被加入DFA };
//栈操作
typedef struct Stack
{
int data[MAXSIZE];
int top;
};
/*---------------------------------全局变量----------------------------------*/
//文法加点
enum { S, E, A, B };
char WenFa[MAXSIZE][MAXSIZE]; //存放从文件中读取的文法
int g_num_wenfa = 0; //存放文法的个数,初值为0
wenfanode* LRWenFa[LR_MAXSIZE]; //将加点后的文法存放于此
int g_wenfa_dot = 1; //记录加点后文法的下标
char str_after[MAXSIZE]; //保存加点过后的文法
//NFA
char NFA[NUM][NUM]; //构造的NFA表
char VN[NUM_VN] = { 'S','E','A','B' };
char VT[NUM_VT] = { 'a', 'b', 'c', 'd', '#' };
//DFA
static unsigned int g_DFA_num = 0; //用来表示DFA的结点下标
char DFA[NUM][NUM]; //构造的DFA表
wenfanode* DFA_node[LR_MAXSIZE][MAXSIZE]; //用来存放DFA结点中的NFA结点
//LR表
string ACTION[LR_MAXSIZE][NUM_VT];
int GOTO[LR_MAXSIZE][NUM_VN];
//分析
int g_num = 0; //用来记录步骤
int g_input = 0; //用来检索输入串
Stack *State_Stack; //状态栈
Stack *Symbol_Stack; //符号栈
char inputstring[10]; //输入串
/*---------------------------------函数声明----------------------------------*/
//文法加点
bool readfromfile(char* str); //读取文法
void AddChar2Str(const char str[], char str_after[], int i, int k); //在字符串的某位置加一个字符'.'
void AddDot(); //给文法加点
void Print_Dot(); //输出加点的结果
//NFA
void init_NFA(); //初始化NFA
int find_pos_point(char* str); //找到点的位置
bool isVN(char ch); //判断一个字符是不是非终结符
bool isVT(char ch); //判断一个字符是不是终结符
int find_node(char ch, int a[]); //查找以ch开头,右部首为点的文法,将文法的编号存入数组a中,返回个数
void make_NFA(); //构造NFA,使用邻接矩阵存储
void print_NFA(); //输出NFA
//DFA
void init_DFA(); //初始化DFA
void add_state(int to, int from); //经from连接的结点添加到to可以连接的节点中去
void make_DFA(); //构造DFA
void print_DFA(); //输出DFA
//LR分析表
void count_DFA_State(); //计算DFA结点的个数
void init_LR_Table(); //初始化LR分析表
int VN2int(char ch); //非终结符转为对应表格下标
int VT2int(char ch); //终结符转为对应表格下标
char* need_protocol(int point); //判断结点中的点有没有规约项
int find_wenfa(char* str); //根据文法内容找到文法编号
void fill_LRtable(); //填充LR分析表
void print_LR_Table(); //输出LR分析表
//规约
void init_Stack(Stack **s); //初始化栈
bool empty_Stack(Stack *s); //判断栈空
void Push(Stack *s, char x); //入栈
char Pop(Stack *s); //出栈
char Top(Stack *s); //取栈顶元素
void print_Stack_ch(Stack *s); //输出符号栈
void print_Stack_int(Stack *s); //输出状态栈
bool inputformfile(char* str); //从文件中读取输入
bool is_End(); //判断规约是否完成
int count_right_num(string str); //统计产生式右部字符的个数
void output(); //输出一次操作
void do_sipulstions(); //进行规约
int main()
{
//任务一
readfromfile("wenfa.txt"); //从文件中读取文法
AddDot(); //给文法加点
Print_Dot(); //输出加点结果
//任务二
make_NFA();
print_NFA();
//任务三
make_DFA();
print_DFA();
//任务四
fill_LRtable();
print_LR_Table();
//任务五
init_Stack(&Symbol_Stack);
init_Stack(&State_Stack);
inputformfile("input.txt"); //从文件中读取输入串
do_sipulstions(); //进行规约
getchar();
return 0;
}
//-----------------------------任务一:给文法加点,存储在链表中-----------------------------------------
//读取文法
bool readfromfile(char* str)
{
FILE* fp = fopen(str, "r");
if (fp) //succeed
{
while (EOF != fscanf(fp, "%s", WenFa[g_num_wenfa]))
{
g_num_wenfa++;
}
fclose(fp);
return true;
}
else
{
printf("error to open the file\n");
return false;
}
}
/*
功能:在字符串的某位置加一个字符'.'
参数:str为原字符串,str_after为修改后的字符串,i要插入的位置,k为str的长度
*/
void AddChar2Str(const char str[], char str_after[], int i, int k)
{
for (int j = 0; j <= MAXSIZE; j++)
{
str_after[j] = str[j];
}
for (int j = k; j >= i; j--)
{
str_after[j + 1] = str_after[j];
}
str_after[i] = '.';
}
//给文法加点
void AddDot()
{
for (int now_wenfa = 0; now_wenfa < g_num_wenfa; now_wenfa++) //对每一个文法
{
int k = 0; //记录最后一个字符的位置
for (int j = MAXSIZE - 1; j > 2; j--) //文法从最后向前搜索最后一个字符
{
if (WenFa[now_wenfa][j] != 0) //该文法当前字符为空
{
k = j;
break;
}
}
//加点
for (int j = 3; j <= k + 1; j++) //加点的位置
{
AddChar2Str(WenFa[now_wenfa], str_after, j, k);
wenfanode* temp = (wenfanode*)malloc(sizeof(wenfanode));
strcpy(temp->data, str_after);
temp->num = g_wenfa_dot;
temp->state = false;
LRWenFa[g_wenfa_dot++] = temp;
}
}
g_wenfa_dot--; //因为多加了一个
}
//输出加点的结果
void Print_Dot()
{
printf("\n给文法加点的结果如下:");
printf("\n------------------------------------------------------\n");
for (int i = 1; i <= g_wenfa_dot; i++)
{
printf("%2d:%s\t", i, LRWenFa[i]->data);
if (i % 5 == 0)
printf("\n");
}
printf("\n");
}
//------------------------------------任务二:构造NFA--------------------------------------
//初始化NFA
void init_NFA()
{
for (int i = 1; i <= g_wenfa_dot; i++)
{
for (int j = 1; j <= g_wenfa_dot; j++)
{
NFA[i][j] = ' ';
}
}
}
//找到点的位置
int find_pos_point(char* str)
{
int i = 0;
while (str[i] != '\0')
{
if (str[i] == '.')
return i;
i++;
}
}
//判断一个字符是不是非终结符
bool isVN(char ch)
{
switch (ch)
{
case 'S':
case 'E':
case 'A':
case 'B':
return true;
default:
return false;
}
}
//判断一个字符是不是终结符
bool isVT(char ch)
{
switch (ch)
{
case 'a':
case 'b':
case 'c':
case 'd':
case '#':
return true;
default:
return false;
}
}
//查找以ch开头,右部首为点的文法,将文法的编号存入数组a中,返回个数
int find_node(char ch, int a[])
{
int num = 0;
for (int i = 1; i <= g_wenfa_dot; i++) //对每一个加点的文法链
{
if (LRWenFa[i]->data[0] == ch && LRWenFa[i]->data[3] == '.')
{
a[num++] = i;
}
}
return num--; //因为多加了一个
}
//构造NFA,使用邻接矩阵存储
void make_NFA()
{
int a[MAXSIZE]; //记录ε弧要连接的结点编号
init_NFA(); //初始化NFA
for (int i = 1; i <= g_wenfa_dot; i++) //对每一个加点的文法链
{
int pos_point = find_pos_point(LRWenFa[i]->data); //找点的位置
NFA[i][i + 1] = LRWenFa[i]->data[pos_point + 1]; //将该节点和下一个节点连接
//构造ε弧
if (isVN(LRWenFa[i]->data[pos_point + 1])) //点之后紧跟着非终结符
{
int j = find_node(LRWenFa[i]->data[pos_point + 1], a);
for (int k = 0; k < j; k++)
{
NFA[i][a[k]] = '*';
}
}
}
}
//输出NFA
void print_NFA()
{
int i, j;
printf("\n构造的NFA邻接矩阵如下:\n");
printf(" ");
for (i = 1; i <= g_wenfa_dot; i++)
{
printf("%4d", i);
}
printf("\n------------------------------------------------------------------------------\n");
for (i = 1; i <= g_wenfa_dot; i++)
{
printf("%3d|", i);
for (j = 1; j <= g_wenfa_dot; j++)
{
printf("%4c", NFA[i][j]);
}
printf("\n------------------------------------------------------------------------------\n");
}
}
//--------------------------------------任务三:构造DFA--------------------------------------
//初始化DFA
void init_DFA()
{
for (int i = 0; i < NUM; i++)
{
for (int j = 0; j < NUM; j++)
{
DFA[i][j] = ' ';
}
}
}
//经from连接的结点添加到to可以连接的节点中去
void add_state(int to, int from)
{
for (int i = 1; i <= g_wenfa_dot; i++)
{
if (NFA[to][i] != ' ' && NFA[to][i] != '*') //将自己能连接的结点加入DFA
{
DFA[to][i] = NFA[to][i];
}
if (NFA[from][i] != ' ') //from可以连接的点
{
DFA[to][i] = NFA[from][i];
}
}
}
//构造DFA
void make_DFA()
{
int k = 0;
init_DFA();
for (int i = 1; i <= g_wenfa_dot; i++)
{
if (LRWenFa[i]->state == false) //对每一个未被选入DFA的NFA结点
{
//将自己加入DFA结点
k = 0;
wenfanode *temp = (wenfanode*)malloc(sizeof(wenfanode));
strcpy(temp->data, LRWenFa[i]->data);
DFA_node[i][k++] = temp;
LRWenFa[i]->state = true;
for (int j = 1; j <= g_wenfa_dot; j++)
{
if (NFA[i][j] == '*') //有ε弧
{
wenfanode *temp = (wenfanode*)malloc(sizeof(wenfanode));
strcpy(temp->data, LRWenFa[j]->data);
temp->num = j;
DFA_node[i][k++] = temp;
LRWenFa[j]->state = true;
//修改DFA
add_state(i, j);
}
}
}
}
}
//输出DFA
void print_DFA()
{
int i, j;
printf("\n构造的DFA邻接矩阵如下:\n");
printf(" ");
for (i = 1; i <= g_wenfa_dot; i++)
{
printf("%4d", i);
}
printf("\n------------------------------------------------------------------------------\n");
for (i = 1; i <= g_wenfa_dot; i++)
{
printf("%3d|", i);
for (j = 1; j <= g_wenfa_dot; j++)
{
printf("%4c", DFA[i][j]);
}
printf("\n------------------------------------------------------------------------------\n");
}
}
//-------------------------------------构造LR分析表------------------------------------------
//计算DFA结点的个数
void count_DFA_State()
{
for (int i = 1; i <= g_wenfa_dot; i++)
{
if (DFA_node[i][0] != NULL)
{
g_DFA_num++;
}
}
}
//初始化LR分析表
void init_LR_Table()
{
count_DFA_State(); //得到DFA结点的个数
for (int i = 1; i <= g_wenfa_dot; i++)
{
for (int j = 0; j < NUM_VT; j++)
{
ACTION[i][j] = " ";
}
for (int k = 0; k < NUM_VT; k++)
{
GOTO[i][k] = -1;
}
}
}
//非终结符转为对应表格下标
int VN2int(char ch)
{
switch (ch)
{
case 'E':
return 0;
case 'A':
return 1;
case 'B':
return 2;
default:
return -1;
}
}
//终结符转为对应表格下标
int VT2int(char ch)
{
switch (ch)
{
case 'a':
return 0;
case 'b':
return 1;
case 'c':
return 2;
case 'd':
return 3;
case '#':
return 4;
default:
return -1;
}
}
//判断结点中的点有没有规约项
char* need_protocol(int point)
{
if (DFA_node[point][0] != NULL)
{
for (int i = 0; i < MAXSIZE; i++)
{
int j = 0;
while (DFA_node[point][i]->data[j] != '\0')
{
j++;
}
if (DFA_node[point][i]->data[j - 1] == '.')
{
return DFA_node[point][i]->data;
}
else
{
return NULL;
}
}
}
else
{
return NULL;
}
}
//根据文法内容找到文法编号
int find_wenfa(char* str)
{
//去掉最后的点
int j = 0;
while (str[j] != '\0')
{
j++;
}
str[j - 1] = '\0';
//判断
for (int i = 0; i < g_num_wenfa; i++)
{
if (strcmp(str, WenFa[i]) == 0)
{
return i;
}
}
}
//填充LR分析表
void fill_LRtable()
{
char *temp_ch = (char*)malloc(2 * sizeof(char)); //用来存放数据
init_LR_Table();
int i, j;
//访问DFA
for (i = 1; i <= g_wenfa_dot; i++)
{
char *str;
if (str = need_protocol(i))
{
int num = find_wenfa(str);
sprintf(temp_ch, "%d", num);
string temp = "r";
temp += temp_ch;
for (j = 0; j < NUM_VT; j++)
{
ACTION[i][j] = temp;
}
}
else
{
for (j = 1; j <= g_wenfa_dot; j++)
{
char ch = DFA[i][j];
if (ch != ' ') //有内容
{
if (isVN(ch) == true) //是非终结符
{
GOTO[i][VN2int(ch)] = j;
}
else //是终结符
{
sprintf(temp_ch, "%d", j);
string temp = "s";
temp += temp_ch;
ACTION[i][VT2int(ch)]= temp;
}
}
}
}
}
}
//输出LR分析表
void print_LR_Table()
{
int state = 1;
//表头
printf("\n构造的LR分析表如下:\n");
printf("\t|\t\t\tACTION\t\t\t|\t\tGOTO\t\t|\n");
printf("\t|\t");
for (int i = 0; i < NUM_VT; i++)
{
printf("%c\t", VT[i]);
}
printf("|\t");
for (int i = 1; i < NUM_VN; i++)
{
printf("%c\t", VN[i]);
}
printf("|");
printf("\n------------------------------------------------------------------------------------------\n");
//表体
for (int i = 1; i <= g_wenfa_dot; i++)
{
printf("%5d\t|\t", state++); //状态编号
//action
for (int j = 0; j < NUM_VT; j++)
{
cout << ACTION[i][j] << "\t";
}
printf("|\t");
//goto
for (int j = 0; j < NUM_VN-1; j++)
{
if (GOTO[i][j] != -1)
{
cout << GOTO[i][j] << "\t";
}
else
{
cout << " \t";
}
}
printf("|\n");
}
printf("------------------------------------------------------------------------------------------\n");
}
//-------------------------------------规约------------------------------------------
//初始化栈
void init_Stack(Stack **s)
{
*s = (Stack*)malloc(sizeof(Stack));
(*s)->top = -1;
}
//判断栈空
bool empty_Stack(Stack *s)
{
if (s->top == -1)
{
return true;
}
else
{
return false;
}
}
//入栈
void Push(Stack *s, char x)
{
if (s->top == MAXSIZE - 1)
{
printf("栈已经满了,无法完成入栈操作\n");
}
else
{
s->top++;
s->data[s->top] = x;
}
}
//出栈
char Pop(Stack *s)
{
char temp;
if (s->top == -1)
{
printf("栈已经空了,无法完成出栈操作");
return NULL;
}
else
{
temp = s->data[s->top];
s->top--;
return temp;
}
}
//取栈顶元素
char Top(Stack *s)
{
return s->data[s->top];
}
//输出符号栈
void print_Stack_ch(Stack *s)
{
for (int i = 0; i <= s->top; i++)
{
printf("%c ", s->data[i]);
}
}
//输出状态栈
void print_Stack_int(Stack *s)
{
for (int i = 0; i <= s->top; i++)
{
printf("%d ", s->data[i]);
}
}
//从文件中读取输入
bool inputformfile(char* str)
{
FILE* fp = fopen(str, "r");
if (fp) //succeed
{
while (EOF != fscanf(fp, "%s", inputstring))
{
//
}
fclose(fp);
return true;
}
else
{
printf("error to open the file\n");
return false;
}
}
//判断分析是否完成
bool is_End()
{
//判断输入串
if (inputstring[0] == '#')
{
//判断符号栈
if (Symbol_Stack->data[0] == '#' && Symbol_Stack->data[1] == 'S')
{
return true;
}
else
{
return false;
}
}
else
{
return false;
}
}
//统计产生式右部的个数
int count_right_num(string str)
{
int temp = 0;
int i = 3;
while (str[i] != '\0')
{
temp++;
i++;
}
return temp;
}
//输出
void output()
{
printf("%d)\t\t", g_num++); //输出步骤
print_Stack_int(State_Stack); //输出状态栈
printf(" \t\t");
print_Stack_ch(Symbol_Stack); //输出符号栈
printf(" \t");
int temp = g_input;
while (inputstring[temp] != '\0')
{
printf("%c", inputstring[temp++]);
}
printf("\n");
if(inputstring[g_input+1] != '\0')
{
g_input++;
}
}
//进行规约
void do_sipulstions()
{
int now_state, next_state; //栈顶状态
char input_ch; //输入字符
char symbol_ch; //符号栈栈顶
printf("\n分析过程如下:\n");
printf("\n步骤\t\t状态\t\t\t符号\t\t输入串\t\n");
printf("--------------------------------------------------------------\n");
Push(State_Stack, 1); //初始化状态栈为0状态
Push(Symbol_Stack, '#'); //初始化符号栈为#
while (!is_End()) //当没有完的时候
{
now_state = Top(State_Stack); //取状态栈顶
input_ch = inputstring[g_input]; //取当前字符
output(); //输出
string ret_string = ACTION[now_state][VT2int(input_ch)]; //查ACTION表
if (ret_string[0] == 's') //进行状态转移
{
Push(Symbol_Stack, input_ch); //当前字符入符号栈
//下一个状态入状态栈
//取数字
int temp = 1;
int num = 0;
while (ret_string[temp] != '\0')
{
num = num * 10 + ret_string[temp++] - 48;
}
Push(State_Stack, num);
}
else if (ret_string[0] == 'r') //进行规约
{
int num_wenfa = ret_string[1] - 48; //规约的文法编号
string str_wenfa = WenFa[num_wenfa]; //取出规约文法
int popnum = count_right_num(str_wenfa); //计算右部个数
for (int i = 0; i < popnum; i++) //符号栈状态栈出栈右部个数次
{
Pop(Symbol_Stack);
Pop(State_Stack);
}
Push(Symbol_Stack, str_wenfa[0]); //文法左部入符号栈
//查GOTO表加入新状态
(int)now_state = Top(State_Stack); //取状态栈顶
symbol_ch = Top(Symbol_Stack); //取符号栈顶
int ret_num = GOTO[now_state][VN2int(symbol_ch)]; //查GOTO表
if (ret_num == -1)
{
printf("\n分析失败\n");
break;
}
Push(State_Stack, ret_num); //goto表返回状态入栈
}
else
{
break;
}
}
printf("\n分析成功\n");
}

相关文章推荐