Storm入门之第一章
2016-07-06 18:53
253 查看
一些术语的字面意义翻译如下,由于这个工具的名字叫Storm,这些术语一律按照气象名词解释
spout 龙卷,读取原始数据为bolt提供数据
bolt 雷电,从spout或其它bolt接收数据,并处理数据,处理结果可作为其它bolt的数据源或最终结果
nimbus 雨云,主节点的守护进程,负责为工作节点分发任务。
下面的术语跟气象就没有关系了
topology 拓扑结构,Storm的一个任务单元
define field(s) 定义域,由spout或bolt提供,被bolt接收
基础知识
Storm是一个分布式的,可靠的,容错的数据流处理系统。它会把工作任务委托给不同类型的组件,每个组件负责处理一项简单特定的任务。Storm集群的输入流由一个被称作spout的组件管理,spout把数据传递给bolt, bolt要么把数据保存到某种存储器,要么把数据传递给其它的bolt。你可以想象一下,一个Storm集群就是在一连串的bolt之间转换spout传过来的数据。
这里用一个简单的例子来说明这个概念。昨晚我在新闻节目里看到主持人在谈论政治人物和他们对于各种政治话题的立场。他们一直重复着不同的名字,而我开始考虑这些名字是否被提到了相同的次数,以及不同次数之间的偏差。
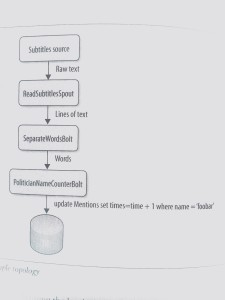
想像播音员读的字幕作为你的数据输入流。你可以用一个spout读取一个文件(或者socket,通过HTTP,或者别的方法)。文本行被spout传给一个bolt,再被bolt按单词切割。单词流又被传给另一个bolt,在这里每个单词与一张政治人名列表比较。每遇到一个匹配的名字,第二个bolt为这个名字在数据库的计数加1。你可以随时查询数据库查看结果, 而且这些计数是随着数据到达实时更新的。所有组件(spouts和bolts)及它们之间的关系请参考拓扑图1-1
现在想象一下,很容易在整个Storm集群定义每个bolt 和spout的并行性级别,因此你可以无限的扩展你的拓扑结构。很神奇,是吗?尽管这是个简单例子,你也可以看到Storm的强大。
有哪些典型的Storm应用案例?
数据处理流
正如上例所展示的,不像其它的流处理系统,Storm不需要中间队列。
连续计算
连续发送数据到客户端,使它们能够实时更新并显示结果,如网站指标。
分布式远程过程调用
频繁的CPU密集型操作并行化。
Storm组件
对于一个Storm集群,一个连续运行的主节点组织若干节点工作。
在Storm集群中,有两类节点:主节点master node和工作节点worker nodes。主节点运行着一个叫做Nimbus的守护进程。这个守护进程负责在集群中分发代码,为工作节点分配任务,并监控故障。Supervisor守护进程作为拓扑的一部分运行在工作节点上。一个Storm拓扑结构在不同的机器上运行着众多的工作节点。
因为Storm在Zookeeper或本地磁盘上维持所有的集群状态,守护进程可以是无状态的而且失效或重启时不会影响整个系统的健康(见图1-2)

在系统底层,Storm使用了zeromq(0mq, zeromq(http://www.zeromq.org))。这是一种先进的,可嵌入的网络通讯库,它提供的绝妙功能使Storm成为可能。下面列出一些zeromq的特性。
一个并发架构的Socket库
对于集群产品和超级计算,比TCP要快
可通过inproc(进程内), IPC(进程间), TCP和multicast(多播协议)通信
异步I / O的可扩展的多核消息传递应用程序
利用扇出(fanout), 发布订阅(PUB-SUB),管道(pipeline), 请求应答(REQ-REP),等方式实现N-N连接
NOTE: Storm只用了push/pull sockets
Storm的特性
在所有这些设计思想与决策中,有一些非常棒的特性成就了独一无二的Storm。
简化编程 如果你曾试着从零开始实现实时处理,你应该明白这是一件多么痛苦的事情。使用Storm,复杂性被大大降低了。
使用一门基于JVM的语言开发会更容易,但是你可以借助一个小的中间件,在Storm上使用任何语言开发。有现成的中间件可供选择,当然也可以自己开发中间件。
容错 Storm集群会关注工作节点状态,如果宕机了必要的时候会重新分配任务。
可扩展 所有你需要为扩展集群所做的工作就是增加机器。Storm会在新机器就绪时向它们分配任务。
可靠的 所有消息都可保证至少处理一次。如果出错了,消息可能处理不只一次,不过你永远不会丢失消息。
快速 速度是驱动Storm设计的一个关键因素
事务性 You can get exactly once messaging semantics for pretty much any computation.你可以为几乎任何计算得到恰好一次消息语义。
spout 龙卷,读取原始数据为bolt提供数据
bolt 雷电,从spout或其它bolt接收数据,并处理数据,处理结果可作为其它bolt的数据源或最终结果
nimbus 雨云,主节点的守护进程,负责为工作节点分发任务。
下面的术语跟气象就没有关系了
topology 拓扑结构,Storm的一个任务单元
define field(s) 定义域,由spout或bolt提供,被bolt接收
基础知识
Storm是一个分布式的,可靠的,容错的数据流处理系统。它会把工作任务委托给不同类型的组件,每个组件负责处理一项简单特定的任务。Storm集群的输入流由一个被称作spout的组件管理,spout把数据传递给bolt, bolt要么把数据保存到某种存储器,要么把数据传递给其它的bolt。你可以想象一下,一个Storm集群就是在一连串的bolt之间转换spout传过来的数据。
这里用一个简单的例子来说明这个概念。昨晚我在新闻节目里看到主持人在谈论政治人物和他们对于各种政治话题的立场。他们一直重复着不同的名字,而我开始考虑这些名字是否被提到了相同的次数,以及不同次数之间的偏差。
想像播音员读的字幕作为你的数据输入流。你可以用一个spout读取一个文件(或者socket,通过HTTP,或者别的方法)。文本行被spout传给一个bolt,再被bolt按单词切割。单词流又被传给另一个bolt,在这里每个单词与一张政治人名列表比较。每遇到一个匹配的名字,第二个bolt为这个名字在数据库的计数加1。你可以随时查询数据库查看结果, 而且这些计数是随着数据到达实时更新的。所有组件(spouts和bolts)及它们之间的关系请参考拓扑图1-1
现在想象一下,很容易在整个Storm集群定义每个bolt 和spout的并行性级别,因此你可以无限的扩展你的拓扑结构。很神奇,是吗?尽管这是个简单例子,你也可以看到Storm的强大。
有哪些典型的Storm应用案例?
数据处理流
正如上例所展示的,不像其它的流处理系统,Storm不需要中间队列。
连续计算
连续发送数据到客户端,使它们能够实时更新并显示结果,如网站指标。
分布式远程过程调用
频繁的CPU密集型操作并行化。
Storm组件
对于一个Storm集群,一个连续运行的主节点组织若干节点工作。
在Storm集群中,有两类节点:主节点master node和工作节点worker nodes。主节点运行着一个叫做Nimbus的守护进程。这个守护进程负责在集群中分发代码,为工作节点分配任务,并监控故障。Supervisor守护进程作为拓扑的一部分运行在工作节点上。一个Storm拓扑结构在不同的机器上运行着众多的工作节点。
因为Storm在Zookeeper或本地磁盘上维持所有的集群状态,守护进程可以是无状态的而且失效或重启时不会影响整个系统的健康(见图1-2)
在系统底层,Storm使用了zeromq(0mq, zeromq(http://www.zeromq.org))。这是一种先进的,可嵌入的网络通讯库,它提供的绝妙功能使Storm成为可能。下面列出一些zeromq的特性。
一个并发架构的Socket库
对于集群产品和超级计算,比TCP要快
可通过inproc(进程内), IPC(进程间), TCP和multicast(多播协议)通信
异步I / O的可扩展的多核消息传递应用程序
利用扇出(fanout), 发布订阅(PUB-SUB),管道(pipeline), 请求应答(REQ-REP),等方式实现N-N连接
NOTE: Storm只用了push/pull sockets
Storm的特性
在所有这些设计思想与决策中,有一些非常棒的特性成就了独一无二的Storm。
简化编程 如果你曾试着从零开始实现实时处理,你应该明白这是一件多么痛苦的事情。使用Storm,复杂性被大大降低了。
使用一门基于JVM的语言开发会更容易,但是你可以借助一个小的中间件,在Storm上使用任何语言开发。有现成的中间件可供选择,当然也可以自己开发中间件。
容错 Storm集群会关注工作节点状态,如果宕机了必要的时候会重新分配任务。
可扩展 所有你需要为扩展集群所做的工作就是增加机器。Storm会在新机器就绪时向它们分配任务。
可靠的 所有消息都可保证至少处理一次。如果出错了,消息可能处理不只一次,不过你永远不会丢失消息。
快速 速度是驱动Storm设计的一个关键因素
事务性 You can get exactly once messaging semantics for pretty much any computation.你可以为几乎任何计算得到恰好一次消息语义。

相关文章推荐
- Release Notes - Apache Storm - Version 0.9.2-incub
- C/C++实现对STORM运行信息查看及控制的方法
- 基于Storm的Nginx log实时监控系统
- Storm配置属性和操作命令
- Storm集群的搭建
- storm topology优化之lib库分离
- 从storm-jdbc谈谈component的生命周期
- Storm 实时云计算 学习使用 包括基本api 以及 高层次api trident 的基本使用
- 整合Kafka到Spark Streaming——代码示例和挑战
- 大白话storm
- kafka+storm初探
- storm集群 + kafka单机性能测试
- flume、kafka、storm常用命令
- Storm DRPC实现机制分析剖析
- spark自带示例一
- storm
- Storm配置项详解
- Twitter Storm 安装篇
- Storm入门教程 Storm安装部署步骤
- Storm常见问题及解决方法收集