MIT6.828 Lab4 Part A: Multiprocessor Support and Cooperative Multitasking
2016-07-06 15:35
549 查看
Introduction
在这次试验中,我们将在同时运行的多用户环境实现抢占式多任务机制。
在Part A部分,我们将为JOS增加多处理器特性,实现轮转(RR)调度,增加用户环境管理的系统调用(创建和销毁环境,分配和映射内存)。
Lab 4添加的源文件:
kern/cpu.h 对多处理器支持的内核私有定义
kern/mpconfig.c 读取多处理器配置的代码
kern/lapic.c 引导每个CPU上的Local APIC的内核代码
kern/mpentry.S 非启动CPU的入口汇编代码
kern/spinlock.h 内核自旋锁定义
kern/spinlock.c 自旋锁实现的内核代码
kern/sched.c 调度器代码框架
Multiprocessor Support
我们将使JOS支持对称多处理器(SMP),一种多处理器架构,所有的CPU对等地访问系统资源。在SMP中所有CPU的功能是相同的,但是在启动过程中会被分为2类:引导处理器(BSP)负责初始化系统来启动操作系统,当操作系统被启动后,应用处理器(APs)被引导处理器激活。引导处理器是由硬件和BIOS决定的,我们目前所有的代码都是运行在BSP上。
在1个SMP系统中,每个CPU有1个附属的Local APIC单元。LAPIC单元负责处理系统中的中断,同时为它关联的CPU提供独一无二的标识符。在这次实验中,我们将使用LAPIC单元以下基本功能(在/kern/lapic.c):
读取LAPIC的标识符(ID)来告诉我们正在哪个CPU上运行代码(cpunum()).
从BSP发送STARTUP的处理器间中断(IPI) 到APs来唤醒其它CPU(lapic_startup()).
在Part C部分,我们将编程LAPIC内置的计时器来触发时钟中断来支持多任务抢占(apic_init).
处理器访通过内存映射IO(MMIO)的方式访问它的LAPIC。在MMIO中,一部分物理地址被硬连接到一些IO设备的寄存器,导致操作内存的指令load/store可以直接操作设备的寄存器。我们已经看到过1个IO hole在物理地址0xA0000(我们用这来写入VGA显示缓存)。LAPIC的空洞开始于物理地址0xFE000000(4GB之下地32MB),但是这地址太高我们无法访问通过过去的直接映射(虚拟地址0xF0000000映射0x0,即只有256MB)。但是JOS虚拟地址映射预留了4MB空间在MMIOBASE处,我们需要分配映射空间。
Exercise 1:
在kern/pmap.c中实现mmio_map。可以查看lapic_init函数的开头来搞清楚这是怎么实现的。
回答:
在lapic_init函数的开头就会调用mmio_map.
在kern/pmap.c中,有具体的提示,设置个静态变量记录每次变化后的虚拟基地址,使用boot_map_region函数将[pa,pa+size)的物理地址映射到[base,base+size),记得把size roundup到PGSIZE。由于这是设备内存并不是正常的DRAM,所以使用cache缓存访问是不安全的,我们可以用页的标志位来实现。
Application Processor Bootstrap
在启动APs之前,BSP应该先收集关于多处理器系统的配置信息,比如CPU总数,CPUs的APIC ID,LAPIC单元的MMIO地址等。在kern/mpconfig文件中的mp_init()函数通过读BIOS设定的MP配置表获取这些信息。
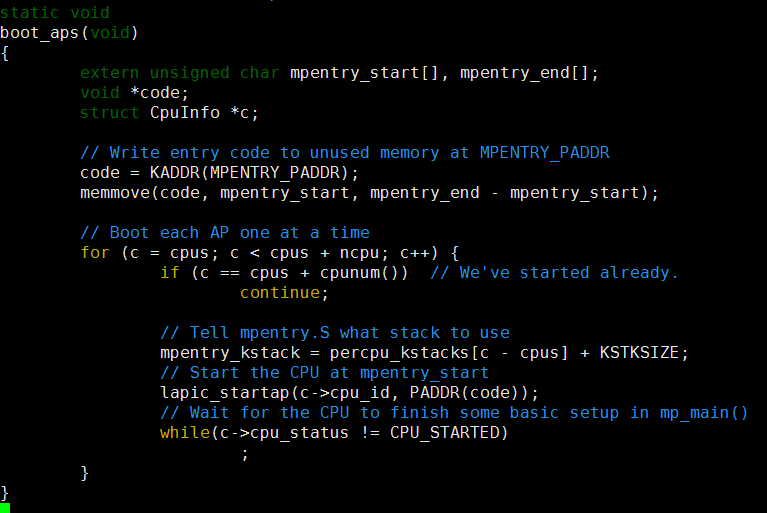
boot_aps(kern/init.c)函数驱使AP引导程序。APs开始于实模式,跟BSP的开始相同,故此boot_aps函数拷贝AP入口代码(kern/mpentry.S)到实模式下的内存寻址空间。但是跟BSP不一样的是,我们需要有一些控制当AP开始执行时。我们将拷贝入口代码到0x7000(MPENTRY_PADDR)。
之后,boot_aps函数通过发送STARTUP的IPI(处理器间中断)信号到AP的LAPIC单元来一个个地激活AP。在kern/mpentry.S中的入口代码跟boot/boot.S中的代码类似。在一些简短的配置后,它使AP进入开启分页机制的保护模式,调用C语言的setup函数mp_main。
总结:

在i386init函数中进行BSP启动的一些配置,经由lab2的 mem_init,lab3的env_init和trap_init,lab4的mp_init和lapic_init,然后boot_aps函数启动所有的CPU。
多核处理器的初始化都在mp_init函数中完成,首先是调用mpconfig函数,主要功能是寻找一个MP 配置条目,然后对所有的CPU进行配置,找到启动的处理器。

在启动过程中,mp_init和lapic_init是和硬件以及体系架构紧密相关的,通过读取某个特殊内存地址(当然前提是能读取的到,所以在mem_init中需要修改进行相应映射),来获取CPU的信息,根据这些信息初始化CPU结构。
在boot_aps函数中首先找到一段用于启动的汇编代码,该代码和上一章实验一样是嵌入在内核代码段之上的一部分,其中mpentry_start和mpentry_end是编译器导出符号,代表这段代码在内存(虚拟地址)中的起止位置,接着把代码复制到MPENTRY_PADDR处。随后调用lapic_startap来命令特定的AP去执行这段代码。
Exercise 2:
修改page_init函数(kern/page.c)的实现,来避免将MPENTRY_PADDR处的物理页加入到空闲链表中。故此我们能安全地拷贝和运行AP的启动代码。
回答:
在boot_aps函数中将启动代码放到了MPENTRY_PADDR处,而代码的来源则是在kern/mpentry.S中,功能与boot.S中的非常类似,主要就是开启分页,转到内核栈上去,当然这个时候实际上内核栈还没建好。在执行完mpentry.S中的代码之后,将会跳转到mp_main函数中去。而这里需要提前做的,就是将MPENTRY_PADDR处的物理页表标识为已用,这样不会讲这一页放在空闲链表中分配出去。只需要在page_init中添加一个判断就可以。
Qusetion 1:
仔细比较kern/mpentry.S与boot/boot.S,想想kern/mpentry.S是被编译链接来运行在KERNBASE之上的,那么定义MPBOOTPHYS宏的目的是什么?为什么在kern/mpentry.S中是必要的,在boot/boot.S中不是呢?换句话说,如果我们在kern/mpentry.S中忽略它,会出现什么错误?
回答:
#define MPBOOTPHYS(s) ((s) - mpentry_start + MPENTRY_PADDR))))
MPBOOTPHYS is to calculate symobl address relative to MPENTRY_PADDR. The ASM is executed in the load address above KERNBASE, but JOS need to run mp_main at 0x7000 address! Of course 0x7000’s page is reserved at pmap.c.
在AP的保护模式打开之前,是没有办法寻址到3G以上的空间的,因此用MPBOOTPHYS是用来计算相应的物理地址的。
但是在boot.S中,由于尚没有启用分页机制,所以我们能够指定程序开始执行的地方以及程序加载的地址;但是,在mpentry.S的时候,由于主CPU已经处于保护模式下了,因此是不能直接指定物理地址的,给定线性地址,映射到相应的物理地址是允许的。
**Per-CPU State and Initialization
当编写一个多进程OS时,这是非常重要的去区分哪些是每个进程私有的CPU状态,哪些是整个系统共享的全局状态。在kern/cpu.h中定义了大部分的per-CPU状态。
每个CPU独有的变量应该有:
内核栈,因为不同的核可能同时进入到内核中执行,因此需要有不同的内核栈
TSS描述符
每个核的当前执行的任务
每个核的寄存器
Exercise 3:
修改mem_init_mp函数来映射开始于KSTACKTOP的per-CPU栈。
回答:
多CPU的内存分布

需要为每个核都分配一个内核栈,每个内核栈的大小是KSTKSIZE,而内核栈之间的间距是KSTKGAP,起到保护作用。
Exercise 4:
在trap_init_percpu函数中为BSP初始化TSS和TSS描述符,这在Lab3中是可行的,但是在这里会有问题,修改代码使它可以运行在所以CPU上。
回答:
由于有多个CPU,所以在这里不能使用原先的全局变量ts,应该利用thiscpu指向的CpuInfo结构体和cpunum函数来为每个核的TSS进行初始化。
Locking
在mp_main函数中初始化AP后,代码就会进入自旋。在让AP进行更多操作之前,我们首先要解决多CPU同时运行在内核时产生的竞争问题。最简单的办法是实现1个大内核锁,1次只让一个进程进入内核模式,当离开内核时释放锁。
在kern/spinlock.h中声明了大内核锁,提供了lock_kernel和unlock_kernel函数来快捷地获得和释放锁。总共有四处用到大内核锁:
在启动的时候,BSP启动其余的CPU之前,BSP需要取得内核锁
mp_main中,也就是CPU被启动之后执行的第一个函数,这里应该是调用调度函数,选择一个进程来执行的,但是在执行调度函数之前,必须获取锁
trap函数也要修改,因为可以访问临界区的CPU只能有一个,所以从用户态陷入到内核态的话,要加锁,因为可能多个CPU同时陷入内核态
env_run函数,也就是启动进程的函数,之前在试验3中实现的,在这个函数执行结束之后,就将跳回到用户态,此时离开内核,也就是需要将内核锁释放
加锁后,将原有的并行执行过程在关键位置变为串行执行过程,整个启动过程大概如下:
i386_init–>BSP获得锁–>boot_ap–>(BSP建立为每个cpu建立idle任务、建立用户任务,mp_main)—>BSP的sched_yield–>其中的env_run释放锁–>AP1获得锁–>执行sched_yield–>释放锁–>AP2获得锁–>执行sched_yield–>释放锁…..
Exercise5:
在上述位置应用大内核锁。
回答:
Question2:
既然大内核锁保证了只有1个CPU能运行在内核,为什么我们还要为每个CPU准备1个内核栈。
回答:
因为不同的内核栈上可能保存有不同的信息,当1个CPU从内核退出来之后,有可能在内核栈中留下了一些将来还有用的数据,所以一定要有单独的栈。
Challenge 1:
大内核锁简单便于应用,但是它取消了内核模式的并行。大多数现代操作系统使用不同的锁来保护共享状态的不同部分,这称之为细粒度锁。细粒度锁能有效地提高性能,但是也更困难地去实现和检测错误。所以你可以去掉大内核锁,在JOS中实现内核并发。
回答:
实验指导中提供了一些JOS内核中的共享结构,具体实现就是在保证在使用这些结构体时保证互斥。
Round-Robin Scheduling
接下来的任务是改变JOS内核,实现round-robin调度算法。
主要是在sched_yield函数内实现,从该核上一次运行的进程开始,在进程描述符表中寻找下一个可以运行的进程,如果没找到而且上一个进程依然是可以运行的,那么就可以继续运行上一个进程,同时将这个算法实现为了一个系统调用,进程可以主动放弃CPU。
Exercise 6:
实现sched_yield函数,并添加系统调用。
然后修改kern/syscall.c添加相关的系统调用分发机制。
Question 3:
在lcr3运行之后,这个CPU对应的页表就立刻被换掉了,但是这个时候的参数e,也就是现在的curenv,为什么还是能正确的解引用?
回答:
因为当前是运行在系统内核中的,而每个进程的页表中都是存在内核映射的。每个进程页表中虚拟地址高于UTOP之上的地方,只有UVPT不一样,其余的都是一样的,只不过在用户态下是看不到的。所以虽然这个时候的页表换成了下一个要运行的进程的页表,但是curenv的地址没变,映射也没变,还是依然有效的。
Question 4:
在用户环境进行切换时,为什么旧进程的寄存器一定要被保存以便之后重新装载?在哪里发生这样的操作?
回答:
因为不进行保存,旧进程运行时的状态就丢失了,运行就不正确了。每次进入到内核态的时候,当前的运行状态都是在一进入的时候就保存了的。如果没有发生调度,那么之前trapframe中的信息还是会恢复回去,如果发生了调度,恢复的就是被调度运行的进程的上下文了。
Challenge 2:
添加固定优先级的调度策略,确保高优先级的进程总是先于低优先级的进程。
回答:
思路就是为每个进程的结构体添加1个标志优先级的变量,在sched_yield时遍历链表选取优先级最高的可运行进程作为下一个运行进程。
1、在inc/env.h中给Env结构添加1个成员int env_priority
2、在kern/env.c中的env_alloc中给进程赋值为默认优先级ENV_PRIOR_DEFAULT,一共设立了四个基本的优先级,数字越小优先级越高
3、修改kern/sched.c中sched_yield函数的调度策略
4、添加1个系统调用sys_env_set_priority(envid, priority),允许进程的父进程或者自己修改自己的优先级。这里的修改与前面添加系统调用类似。
Challenge3:
现在的JOS内核不支持应用来使用x86处理器的浮点数单元(FPU),MMX指令和SSE扩展指令。扩展Env结构提供保存处理器浮点数状态的空间,扩展进程上下文交换代码来保存和恢复浮点数状态 。
回答:
给中断加入保存浮点寄存器的功能。
1、给inc/trap.h文件中的Trapframe结构新增char tf_fpus[512]成员,并增加uint32_t tf_padding0[3]来对齐
2、修改kern/trapentry.S文件中的_alltraps函数,加入保存fpu寄存器的功能
3、修改kern/env.c文件中的env_pop_tf函数,加入恢复fpu功能
System Calls for Environment Creation
虽然你的内核现在有能力运行和切换多用户级进程,但是它仍然只能跑内核初始创建的进程。你现在将实现必要的JOS系统调用来运行用户进程来创建和启动其它新的用户进程。
Unix提供了fork系统调用来创建进程,它拷贝父进程的整个地址空间到新创建的子进程。两个进程之间唯一的区别是它们的进程ID,在父进程fork返回的是子进程ID,而在子进程fork返回的是0。
你将实现1个不同的更原始的JOS系统调用来创建进程。利用这些系统调用能实现类似Unix的fork函数。
用户级fork函数在user/dumbfork.c中的dumbfork中,该函数将父进程中所有页的内容全部复制过来,唯一不同的地方就是返回值不同。
Exercise 7:
实现ker/syscall.c中的系统调用。
回答:
首先是sys_exofork函数,这个系统调用将创建1个新的空白进程,没有映射的用户空间且无法运行。在调用函数时新进程的寄存器状态与父进程相同,但是在父进程会返回子进程的ID,而子进程会返回0。通过设置子进程的eax为0,来让系统调用的返回值为0。
接着是sys_env_set_status函数,设置进程的状态为ENV_RUNNABLE或者ENV_NOT_RUNNABLE。
然后是env_page_alloc函数,分配1个物理页并映射到给定进程的进程空间的虚拟地址。
接着是sys_page_map函数,从1个进程的页表中拷贝1个页映射到另1个进程的页表中。将进程id为srcenvid的进程的srcva处的物理页的内容,映射到进程id为dstenvid的进程的dstva处。
最后是sys_page_unmap函数,解除指定进程中的1个页映射。
至此所有系统调用都完成了,可以运行一下usr/umbfork.c。首先看一下主函数,逻辑是父进程创建1个子进程,然后每次打印1条信息后交出控制权,并且让父进程重复10次而子进程重复20次。
在这次试验中,我们将在同时运行的多用户环境实现抢占式多任务机制。
在Part A部分,我们将为JOS增加多处理器特性,实现轮转(RR)调度,增加用户环境管理的系统调用(创建和销毁环境,分配和映射内存)。
Lab 4添加的源文件:
kern/cpu.h 对多处理器支持的内核私有定义
kern/mpconfig.c 读取多处理器配置的代码
kern/lapic.c 引导每个CPU上的Local APIC的内核代码
kern/mpentry.S 非启动CPU的入口汇编代码
kern/spinlock.h 内核自旋锁定义
kern/spinlock.c 自旋锁实现的内核代码
kern/sched.c 调度器代码框架
Multiprocessor Support
我们将使JOS支持对称多处理器(SMP),一种多处理器架构,所有的CPU对等地访问系统资源。在SMP中所有CPU的功能是相同的,但是在启动过程中会被分为2类:引导处理器(BSP)负责初始化系统来启动操作系统,当操作系统被启动后,应用处理器(APs)被引导处理器激活。引导处理器是由硬件和BIOS决定的,我们目前所有的代码都是运行在BSP上。
在1个SMP系统中,每个CPU有1个附属的Local APIC单元。LAPIC单元负责处理系统中的中断,同时为它关联的CPU提供独一无二的标识符。在这次实验中,我们将使用LAPIC单元以下基本功能(在/kern/lapic.c):
读取LAPIC的标识符(ID)来告诉我们正在哪个CPU上运行代码(cpunum()).
从BSP发送STARTUP的处理器间中断(IPI) 到APs来唤醒其它CPU(lapic_startup()).
在Part C部分,我们将编程LAPIC内置的计时器来触发时钟中断来支持多任务抢占(apic_init).
处理器访通过内存映射IO(MMIO)的方式访问它的LAPIC。在MMIO中,一部分物理地址被硬连接到一些IO设备的寄存器,导致操作内存的指令load/store可以直接操作设备的寄存器。我们已经看到过1个IO hole在物理地址0xA0000(我们用这来写入VGA显示缓存)。LAPIC的空洞开始于物理地址0xFE000000(4GB之下地32MB),但是这地址太高我们无法访问通过过去的直接映射(虚拟地址0xF0000000映射0x0,即只有256MB)。但是JOS虚拟地址映射预留了4MB空间在MMIOBASE处,我们需要分配映射空间。
Exercise 1:
在kern/pmap.c中实现mmio_map。可以查看lapic_init函数的开头来搞清楚这是怎么实现的。
回答:
在lapic_init函数的开头就会调用mmio_map.
// lapicaddr is the physical address of the LAPIC's 4K MMIO // region. Map it in to virtual memory so we can access it. lapic = mmio_map_region(lapicaddr, 4096);
在kern/pmap.c中,有具体的提示,设置个静态变量记录每次变化后的虚拟基地址,使用boot_map_region函数将[pa,pa+size)的物理地址映射到[base,base+size),记得把size roundup到PGSIZE。由于这是设备内存并不是正常的DRAM,所以使用cache缓存访问是不安全的,我们可以用页的标志位来实现。
//kern/pmap.c
void *
mmio_map_region(physaddr_t pa, size_t size)
{
static uintptr_t base = MMIOBASE;
void *ret = (void *)base;
size = ROUNDUP(size, PGSIZE);
if (base + size > MMIOLIM || base + size < base)
panic("mmio_map_region: reservation overflow\n");
boot_map_region(kern_pgdir, base, size, pa, PTE_P | PTE_PCD | PTE_PWT);
base += size;
return ret;
}Application Processor Bootstrap
在启动APs之前,BSP应该先收集关于多处理器系统的配置信息,比如CPU总数,CPUs的APIC ID,LAPIC单元的MMIO地址等。在kern/mpconfig文件中的mp_init()函数通过读BIOS设定的MP配置表获取这些信息。
boot_aps(kern/init.c)函数驱使AP引导程序。APs开始于实模式,跟BSP的开始相同,故此boot_aps函数拷贝AP入口代码(kern/mpentry.S)到实模式下的内存寻址空间。但是跟BSP不一样的是,我们需要有一些控制当AP开始执行时。我们将拷贝入口代码到0x7000(MPENTRY_PADDR)。
之后,boot_aps函数通过发送STARTUP的IPI(处理器间中断)信号到AP的LAPIC单元来一个个地激活AP。在kern/mpentry.S中的入口代码跟boot/boot.S中的代码类似。在一些简短的配置后,它使AP进入开启分页机制的保护模式,调用C语言的setup函数mp_main。
总结:
在i386init函数中进行BSP启动的一些配置,经由lab2的 mem_init,lab3的env_init和trap_init,lab4的mp_init和lapic_init,然后boot_aps函数启动所有的CPU。
多核处理器的初始化都在mp_init函数中完成,首先是调用mpconfig函数,主要功能是寻找一个MP 配置条目,然后对所有的CPU进行配置,找到启动的处理器。
在启动过程中,mp_init和lapic_init是和硬件以及体系架构紧密相关的,通过读取某个特殊内存地址(当然前提是能读取的到,所以在mem_init中需要修改进行相应映射),来获取CPU的信息,根据这些信息初始化CPU结构。
在boot_aps函数中首先找到一段用于启动的汇编代码,该代码和上一章实验一样是嵌入在内核代码段之上的一部分,其中mpentry_start和mpentry_end是编译器导出符号,代表这段代码在内存(虚拟地址)中的起止位置,接着把代码复制到MPENTRY_PADDR处。随后调用lapic_startap来命令特定的AP去执行这段代码。
Exercise 2:
修改page_init函数(kern/page.c)的实现,来避免将MPENTRY_PADDR处的物理页加入到空闲链表中。故此我们能安全地拷贝和运行AP的启动代码。
回答:
在boot_aps函数中将启动代码放到了MPENTRY_PADDR处,而代码的来源则是在kern/mpentry.S中,功能与boot.S中的非常类似,主要就是开启分页,转到内核栈上去,当然这个时候实际上内核栈还没建好。在执行完mpentry.S中的代码之后,将会跳转到mp_main函数中去。而这里需要提前做的,就是将MPENTRY_PADDR处的物理页表标识为已用,这样不会讲这一页放在空闲链表中分配出去。只需要在page_init中添加一个判断就可以。
//kern/pmap.c
void page_init(void)
{
......
for (i = 0; i < npages; i++) {
......
else if (i == MPENTRY_PADDR / PGSIEZ)
continue;
......
}
}Qusetion 1:
仔细比较kern/mpentry.S与boot/boot.S,想想kern/mpentry.S是被编译链接来运行在KERNBASE之上的,那么定义MPBOOTPHYS宏的目的是什么?为什么在kern/mpentry.S中是必要的,在boot/boot.S中不是呢?换句话说,如果我们在kern/mpentry.S中忽略它,会出现什么错误?
回答:
#define MPBOOTPHYS(s) ((s) - mpentry_start + MPENTRY_PADDR))))
MPBOOTPHYS is to calculate symobl address relative to MPENTRY_PADDR. The ASM is executed in the load address above KERNBASE, but JOS need to run mp_main at 0x7000 address! Of course 0x7000’s page is reserved at pmap.c.
在AP的保护模式打开之前,是没有办法寻址到3G以上的空间的,因此用MPBOOTPHYS是用来计算相应的物理地址的。
但是在boot.S中,由于尚没有启用分页机制,所以我们能够指定程序开始执行的地方以及程序加载的地址;但是,在mpentry.S的时候,由于主CPU已经处于保护模式下了,因此是不能直接指定物理地址的,给定线性地址,映射到相应的物理地址是允许的。
**Per-CPU State and Initialization
当编写一个多进程OS时,这是非常重要的去区分哪些是每个进程私有的CPU状态,哪些是整个系统共享的全局状态。在kern/cpu.h中定义了大部分的per-CPU状态。
每个CPU独有的变量应该有:
内核栈,因为不同的核可能同时进入到内核中执行,因此需要有不同的内核栈
TSS描述符
每个核的当前执行的任务
每个核的寄存器
Exercise 3:
修改mem_init_mp函数来映射开始于KSTACKTOP的per-CPU栈。
回答:
多CPU的内存分布
需要为每个核都分配一个内核栈,每个内核栈的大小是KSTKSIZE,而内核栈之间的间距是KSTKGAP,起到保护作用。
//kern/pmap.c
static void
mem_init_mp(void)
{
int i;
uintptr_t kstacktop_i;
for (i = 0; i < NCPU; i++) {
kstacktop_i = KSTACKTOP - i * (KSTKGAP + KSTKSIZE);
boot_map_region(kern_pgdir,
kstacktop_i - KSTKSIZE,
ROUNDUP(KSTKSIZE, PGSIZE),
PADDR(&percpu_kstacks[i]),
PTE_W | PTE_P);
}
}Exercise 4:
在trap_init_percpu函数中为BSP初始化TSS和TSS描述符,这在Lab3中是可行的,但是在这里会有问题,修改代码使它可以运行在所以CPU上。
回答:
由于有多个CPU,所以在这里不能使用原先的全局变量ts,应该利用thiscpu指向的CpuInfo结构体和cpunum函数来为每个核的TSS进行初始化。
void
trap_init_percpu(void)
{
thiscpu->cpu_ts.ts_esp0 = KSTACKTOP - cpunum() * (KSTKGAP + KSTKSIZE);
thiscpu->cpu_ts.ts_ss0 = GD_KD;
// Initialize the TSS slot of the gdt.
gdt[(GD_TSS0 >> 3) + cpunum()] = SEG16(STS_T32A, (uint32_t) (&thiscpu->cpu_ts), sizeof(struct Taskstate) - 1, 0);
gdt[(GD_TSS0 >> 3) + cpunum()].sd_s = 0;
// Load the TSS selector (like other segment selectors, the
// bottom three bits are special; we leave them 0)
ltr(GD_TSS0 + sizeof(struct Segdesc) * cpunum());
// Load the IDT
lidt(&idt_pd);
}Locking
在mp_main函数中初始化AP后,代码就会进入自旋。在让AP进行更多操作之前,我们首先要解决多CPU同时运行在内核时产生的竞争问题。最简单的办法是实现1个大内核锁,1次只让一个进程进入内核模式,当离开内核时释放锁。
在kern/spinlock.h中声明了大内核锁,提供了lock_kernel和unlock_kernel函数来快捷地获得和释放锁。总共有四处用到大内核锁:
在启动的时候,BSP启动其余的CPU之前,BSP需要取得内核锁
mp_main中,也就是CPU被启动之后执行的第一个函数,这里应该是调用调度函数,选择一个进程来执行的,但是在执行调度函数之前,必须获取锁
trap函数也要修改,因为可以访问临界区的CPU只能有一个,所以从用户态陷入到内核态的话,要加锁,因为可能多个CPU同时陷入内核态
env_run函数,也就是启动进程的函数,之前在试验3中实现的,在这个函数执行结束之后,就将跳回到用户态,此时离开内核,也就是需要将内核锁释放
加锁后,将原有的并行执行过程在关键位置变为串行执行过程,整个启动过程大概如下:
i386_init–>BSP获得锁–>boot_ap–>(BSP建立为每个cpu建立idle任务、建立用户任务,mp_main)—>BSP的sched_yield–>其中的env_run释放锁–>AP1获得锁–>执行sched_yield–>释放锁–>AP2获得锁–>执行sched_yield–>释放锁…..
Exercise5:
在上述位置应用大内核锁。
回答:
//i386_init
lock_kernel();
boot_aps();
//mp_main
lock_kernel();
sched_yield();
//trap
if ((tf->tf_cs & 3) == 3) {
lock_kernel();
assert(curenv);
......
}
//env_run
lcr3(PADDR(curenv->env_pgdir));
unlock_kernel();
env_pop_tf(&(curenv->env_tf));Question2:
既然大内核锁保证了只有1个CPU能运行在内核,为什么我们还要为每个CPU准备1个内核栈。
回答:
因为不同的内核栈上可能保存有不同的信息,当1个CPU从内核退出来之后,有可能在内核栈中留下了一些将来还有用的数据,所以一定要有单独的栈。
Challenge 1:
大内核锁简单便于应用,但是它取消了内核模式的并行。大多数现代操作系统使用不同的锁来保护共享状态的不同部分,这称之为细粒度锁。细粒度锁能有效地提高性能,但是也更困难地去实现和检测错误。所以你可以去掉大内核锁,在JOS中实现内核并发。
回答:
实验指导中提供了一些JOS内核中的共享结构,具体实现就是在保证在使用这些结构体时保证互斥。
Round-Robin Scheduling
接下来的任务是改变JOS内核,实现round-robin调度算法。
主要是在sched_yield函数内实现,从该核上一次运行的进程开始,在进程描述符表中寻找下一个可以运行的进程,如果没找到而且上一个进程依然是可以运行的,那么就可以继续运行上一个进程,同时将这个算法实现为了一个系统调用,进程可以主动放弃CPU。
Exercise 6:
实现sched_yield函数,并添加系统调用。
void
sched_yield(void)
{
uint32_t i, j, start;
struct Env *runenv;
idle = thiscpu->cpu_env;
start = (idle != NULL) ? ENVX(idle->env_id) : 0;
runenv = NULL;
for (i = 0; i < NENV; i++) {
j = (start + i) % NENV;
if (envs[j].env_status == ENV_RUNNABLE) {
if (runenv == NULL || envs[j].env_priority < runenv->env_priority)
runenv = &envs[j];
}
}
if ((idle && idle->env_status == ENV_RUNNING) && (runenv == NULL || idle->env_priority < runenv->env_priority)){
env_run(idle);
return;
}
if (runenv) {
env_run(runenv);
return;
}
// sched_halt never returns
sched_halt();
}然后修改kern/syscall.c添加相关的系统调用分发机制。
Question 3:
在lcr3运行之后,这个CPU对应的页表就立刻被换掉了,但是这个时候的参数e,也就是现在的curenv,为什么还是能正确的解引用?
回答:
因为当前是运行在系统内核中的,而每个进程的页表中都是存在内核映射的。每个进程页表中虚拟地址高于UTOP之上的地方,只有UVPT不一样,其余的都是一样的,只不过在用户态下是看不到的。所以虽然这个时候的页表换成了下一个要运行的进程的页表,但是curenv的地址没变,映射也没变,还是依然有效的。
Question 4:
在用户环境进行切换时,为什么旧进程的寄存器一定要被保存以便之后重新装载?在哪里发生这样的操作?
回答:
因为不进行保存,旧进程运行时的状态就丢失了,运行就不正确了。每次进入到内核态的时候,当前的运行状态都是在一进入的时候就保存了的。如果没有发生调度,那么之前trapframe中的信息还是会恢复回去,如果发生了调度,恢复的就是被调度运行的进程的上下文了。
Challenge 2:
添加固定优先级的调度策略,确保高优先级的进程总是先于低优先级的进程。
回答:
思路就是为每个进程的结构体添加1个标志优先级的变量,在sched_yield时遍历链表选取优先级最高的可运行进程作为下一个运行进程。
1、在inc/env.h中给Env结构添加1个成员int env_priority
2、在kern/env.c中的env_alloc中给进程赋值为默认优先级ENV_PRIOR_DEFAULT,一共设立了四个基本的优先级,数字越小优先级越高
//inc/env.h #define ENV_PRIOR_SUPER 0 #define ENV_PRIOR_HIGH 10 #define ENV_PRIOR_NORMAL 100 #define ENV_PRIOR_LOW 1000
3、修改kern/sched.c中sched_yield函数的调度策略
//kern/sched.c sched_yield()
idle = thiscpu->cpu_env;
start = (idle != NULL) ? ENVX(idle->env_id) : 0;
runenv = NULL;
for (i = 0; i < NENV; i++) {
j = (start + i) % NENV;
if (envs[j].env_status == ENV_RUNNABLE) {
if (runenv == NULL || envs[j].env_priority < runenv->env_priority)
runenv = &envs[j];
}
}
if ((idle && idle->env_status == ENV_RUNNING) && (runenv == NULL || idle->env_priority < runenv->env_priority)){
env_run(idle);
return;
}
if (runenv) {
env_run(runenv);
return;
}4、添加1个系统调用sys_env_set_priority(envid, priority),允许进程的父进程或者自己修改自己的优先级。这里的修改与前面添加系统调用类似。
static int
sys_env_set_priority(envid_t envid, int priority)
{
int ret;
struct Env *env;
if ((ret = envid2env(envid, &env, 1)) < 0)
return ret;
env->env_priority = priority;
return 0;
}Challenge3:
现在的JOS内核不支持应用来使用x86处理器的浮点数单元(FPU),MMX指令和SSE扩展指令。扩展Env结构提供保存处理器浮点数状态的空间,扩展进程上下文交换代码来保存和恢复浮点数状态 。
回答:
给中断加入保存浮点寄存器的功能。
1、给inc/trap.h文件中的Trapframe结构新增char tf_fpus[512]成员,并增加uint32_t tf_padding0[3]来对齐
2、修改kern/trapentry.S文件中的_alltraps函数,加入保存fpu寄存器的功能
_alltraps: pushl %ds pushl %es pushal // save FPU subl $524, %esp fxsave (%esp) movl $GD_KD, %eax movl %eax, %ds movl %eax, %es push %esp call trap
3、修改kern/env.c文件中的env_pop_tf函数,加入恢复fpu功能
__asm __volatile("movl %0,%%esp\n"
"\tfxrstor (%%esp)\n"
"\taddl $524,%%esp\n"
"\tpopal\n"
"\tpopl %%es\n"
"\tpopl %%ds\n"
"\taddl $0x8,%%esp\n" /* skip tf_trapno and tf_errcode */
"\tiret"
: : "g" (tf) : "memory");System Calls for Environment Creation
虽然你的内核现在有能力运行和切换多用户级进程,但是它仍然只能跑内核初始创建的进程。你现在将实现必要的JOS系统调用来运行用户进程来创建和启动其它新的用户进程。
Unix提供了fork系统调用来创建进程,它拷贝父进程的整个地址空间到新创建的子进程。两个进程之间唯一的区别是它们的进程ID,在父进程fork返回的是子进程ID,而在子进程fork返回的是0。
你将实现1个不同的更原始的JOS系统调用来创建进程。利用这些系统调用能实现类似Unix的fork函数。
用户级fork函数在user/dumbfork.c中的dumbfork中,该函数将父进程中所有页的内容全部复制过来,唯一不同的地方就是返回值不同。
Exercise 7:
实现ker/syscall.c中的系统调用。
回答:
首先是sys_exofork函数,这个系统调用将创建1个新的空白进程,没有映射的用户空间且无法运行。在调用函数时新进程的寄存器状态与父进程相同,但是在父进程会返回子进程的ID,而子进程会返回0。通过设置子进程的eax为0,来让系统调用的返回值为0。
static envid_t
sys_exofork(void)
{
int ret;
struct Env *env;
if ((ret = env_alloc(&env, sys_getenvid())) < 0)
return ret;
env->env_status = ENV_NOT_RUNNABLE;
env->env_tf = curenv->env_tf;
env->env_tf.tf_regs.reg_eax = 0;
return env->env_id;
}接着是sys_env_set_status函数,设置进程的状态为ENV_RUNNABLE或者ENV_NOT_RUNNABLE。
static int
sys_env_set_status(envid_t envid, int status)
{
implemented");
int ret;
struct Env *env;
if (status != ENV_RUNNABLE && status != ENV_RUNNING)
return -E_INVAL;
if ((ret = envid2env(envid, &env, 1)) < 0)
return ret;
env->env_status = status;
return 0;
}然后是env_page_alloc函数,分配1个物理页并映射到给定进程的进程空间的虚拟地址。
static int
sys_page_alloc(envid_t envid, void *va, int perm)
{
struct Env *env;
struct PageInfo *pp;
if (envid2env(envid, &env, 1) < 0)
return -E_BAD_ENV;
if ((uintptr_t)va >= UTOP || PGOFF(va))
return -E_INVAL;
if ((perm & PTE_U) == 0 || (perm & PTE_P) == 0)
return -E_INVAL;
if ((perm & ~(PTE_U | PTE_P | PTE_W | PTE_AVAIL)) != 0)
return -E_INVAL;
if ((pp = page_alloc(ALLOC_ZERO)) == NULL)
return -E_NO_MEM;
if (page_insert(env->env_pgdir, pp, va, perm) < 0) {
page_free(pp);
return -E_NO_MEM;
}
return 0;
}接着是sys_page_map函数,从1个进程的页表中拷贝1个页映射到另1个进程的页表中。将进程id为srcenvid的进程的srcva处的物理页的内容,映射到进程id为dstenvid的进程的dstva处。
static int
sys_page_map(envid_t srcenvid, void *srcva,
envid_t dstenvid, void *dstva, int perm)
{
struct Env *srcenv, *dstenv;
struct PageInfo *pp;
pte_t *pte;
if (envid2env(srcenvid, &srcenv, 1) < 0 || envid2env(dstenvid, &dstenv, 1) < 0)
return -E_BAD_ENV;
if ((uintptr_t)srcva >= UTOP || PGOFF(srcva) || (uintptr_t)dstva >= UTOP || PGOFF(dstva))
return -E_INVAL;
if ((perm & PTE_U) == 0 || (perm & PTE_P) == 0 || (perm & ~PTE_SYSCALL) != 0)
return -E_INVAL;
if ((pp = page_lookup(srcenv->env_pgdir, srcva, &pte)) == NULL)
return -E_INVAL;
if ((perm & PTE_W) && (*pte & PTE_W) == 0)
return -E_INVAL;
if (page_insert(dstenv->env_pgdir, pp, dstva, perm) < 0)
return -E_NO_MEM;
return 0;
}最后是sys_page_unmap函数,解除指定进程中的1个页映射。
static int
sys_page_unmap(envid_t envid, void *va)
{
struct Env *env;
if (envid2env(envid, &env, 1) < 0)
return -E_BAD_ENV;
if ((uintptr_t)va >= UTOP || PGOFF(va))
return -E_INVAL;
page_remove(env->env_pgdir, va);
return 0;
}至此所有系统调用都完成了,可以运行一下usr/umbfork.c。首先看一下主函数,逻辑是父进程创建1个子进程,然后每次打印1条信息后交出控制权,并且让父进程重复10次而子进程重复20次。
void
umain(int argc, char **argv)
{
envid_t who;
int i;
// fork a child process
who = dumbfork();
// print a message and yield to the other a few times
for (i = 0; i < (who ? 10 : 20); i++) {
cprintf("%d: I am the %s!\n", i, who ? "parent" : "child");
sys_yield();
}
}

相关文章推荐
- java之架构基础-动态代理&cglib
- OpenCV2:Mat属性type,depth,step
- 开发者相聚杭州,探讨华为开发者大赛三大赛题奥秘!!!
- 【Hadoop】HDFS的运行原理
- Linux的内存回收和交换
- 救援模式下解决linux开机失败
- 在Linux环境下搭建Java Web测试环境
- linux redhat配置yum源为网易(163)源的方法 (
- Centos64 安装指南
- 玩转Flume之核心架构深入解析
- Tomcat
- Debian修改时间后重启出现问题的原因
- Centos 6.4 python 2.6 升级到 2.7
- Nginx RTMP模块 nginx-rtmp-module指令详解
- 【转】Java开发必会的Linux命令
- SEDA架构模型
- Nginx
- 跟我学系列之JVM远程性能监控
- kali下安装docker
- OpenGL