数据挖掘,并不是想象的那么神秘!
2016-07-05 13:46
330 查看
数据挖掘项目的成功与否,很大一部分取决于IT部门与业务部门的紧密配合,由于数据挖掘与业务的结合非常紧密,既需要数据,又需要专业的业务经验与理解,数据一般在IT部门手上,而业务人员当然最了解自己的业务,因此,这彼此之间的沟通与协调经常会遇到一些问题。之前有过不少血的教训,IT人员好不容易分析出来的模型,业务部门对此信任度不高,对分析结果执行不到位,没能很好的反馈给IT人员做进一步的优化,造成模型没能真正应用到业务中,也没能进一步优化模型,造成时间、成本的浪费。
为了让业务人员能够相信分析结果能够给业务带来价值,需要让他们更多地参与到项目中,让业务人员了解、参与、甚至自己动手分析的过程,是当前企业做此类项目的趋势。只有这样,才能让数据挖掘分析结果更好地应用于业务。
我们一直强调,IBM SPSS Modeler最大的优势就是易用性,它提供了图形化界面,让使用人员可以非常方便地通过拖拽的方式实现数据分析流程,让我们有更多的时间和精力集中在业务理解上,而不是编程的调试上。这个听起来会让人觉得有点忽悠的感觉,我们下面通过一个例子,来体验下,当然要有比较才会有区别,我们分别用R和SPSS来实现一个聚类分析,看看两者实现过程的优劣。
分析场景
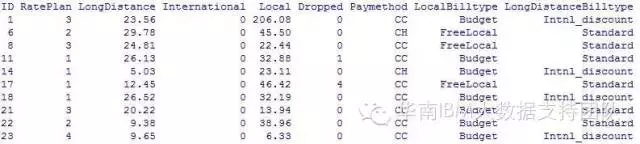
对电信客户做聚类分析,了解各类客户特征。已有的数据包括:客户ID、RatePlan、LongDistance(长途话费)、International(国际话费)、Local(本地话费)、Drop(掉线次数)、Paymethod(付款方式)、LocalBilltype(本地话费类型)和LongDistanceBilltype(长途话费类型)。
分析步骤
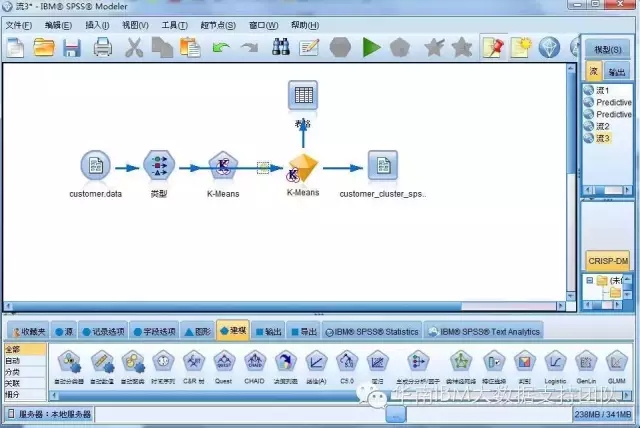
读取数据源、选择要作为输入因素的指标、使用聚类算法实现建模、导出分析结果。通过R实现分析过程
如果用R实现,我们需要以下代码:

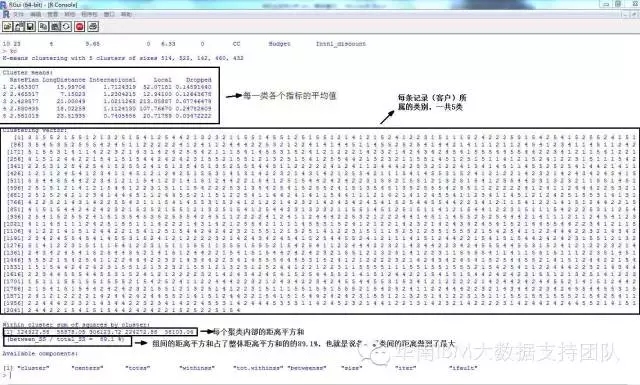
这个代码看起来也并不复杂,R语言的强大之处也在于它的语言很简洁,我们来看它的分析结果,下图就是显示聚类结果:
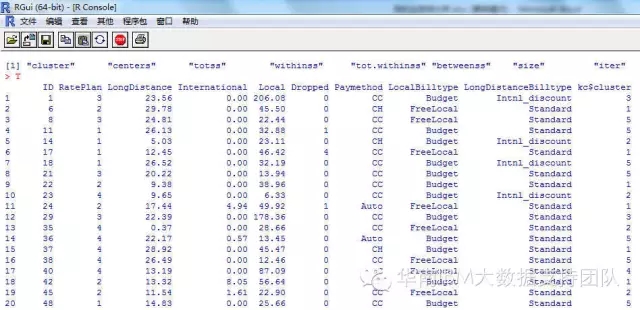
将这个聚类的结果与原来的数据合并在一起,可以看到每个客户所属的类别。
如果你是业务人员,您能看得出这个结果的优劣吗?或者您能从中看明白了什么样的业务结果吗?思考一下,我们接下来看使用SPSS分析是怎么个过程?
通过SPSS Modeler实现分析过程
按照刚才的步骤,我们在SPSS Modeler界面上拖拽相关的功能节点,连接起来得到的数据分析流如下图,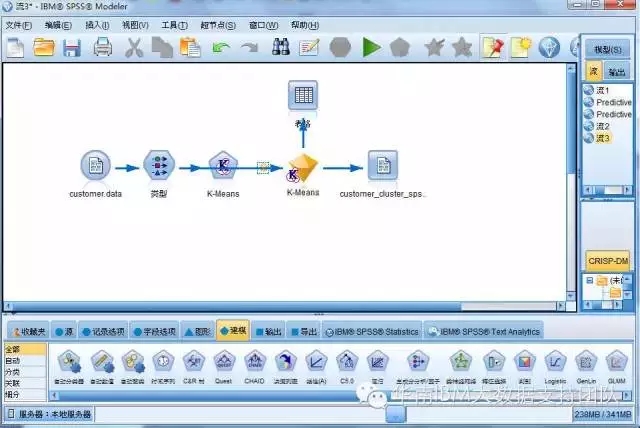
每个功能节点都可以添加注释,解释所实现的功能,可以让业务人员一目了然:
接下来我们看下SPSS Modeler的分析结果,双击生成的模型 ,可以看到以下结果:
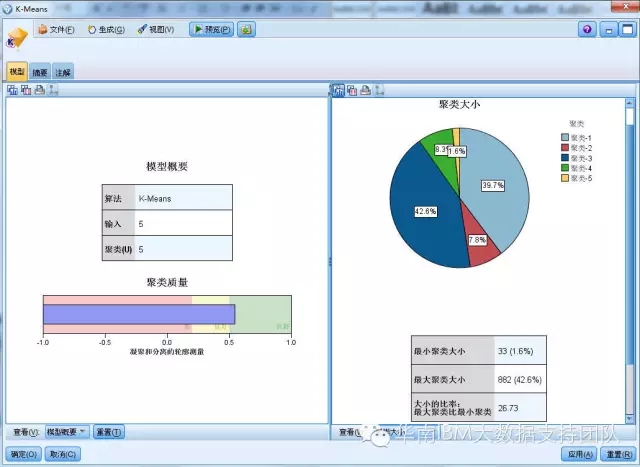
首先,左边的模型概要结果,通过聚类质量数值告诉我们模型聚类结果的优劣,越接近1是越好的,这个业务人员很好理解,当然,如果要追溯到本质,到底这个聚类质量数值是什么样的统计指标,那我们通过它自带的帮助文档也可以知道,这个值其实是Silhouette 测量:测量所有记录的平均值,(B−A)/ max(A,B),其中 A 是记录与其聚类中心的距离,B 是记录与其非所属最近聚类中心的距离。作为业务人员,可以不必深究这个统计指标,只需要通过这个数值比较各种聚类结果的优劣。
右边的饼图直观地看到各类的占比,我们可以通过各类的占比判断各类分布是否均匀,如果不均匀,从业务上会不会不好落实管理。
除此之外,我们需要了解,到底哪些因素影响了我的聚类结果,哪些因素是重要的,哪些是不重要的影响因素,我们可以通过预测变量重要性来了解,如下图:
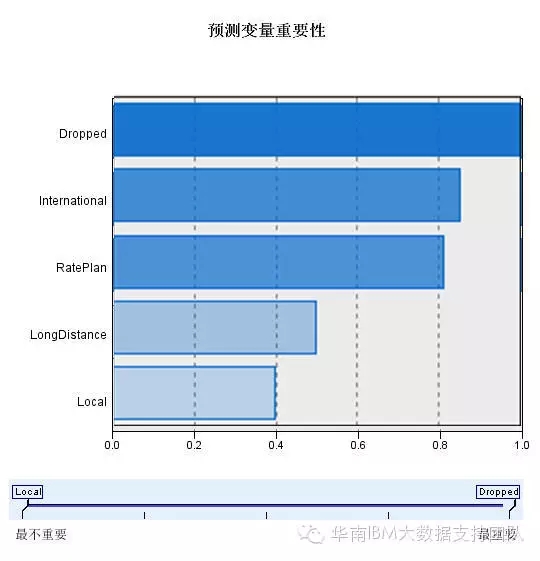
另外,我们在下方查看选择框中选择“聚类”和“聚类比较”,可以看到以下结果:
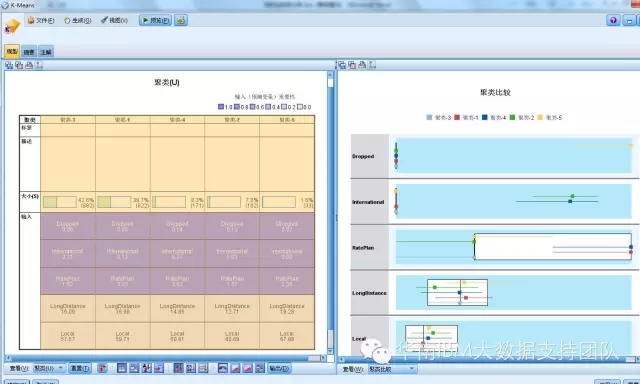
左边的图形中,我们可以看到,每一类,各个指标的平均值,我们想到刚才通过R实现的聚类结果,也有各类的平均值,这个理论上来说是一样的,但为什么结果看起来不一样呢?这个我们后面再解释。我们先看从上面这个图,我们可以怎样从业务上理解这个分析结果。
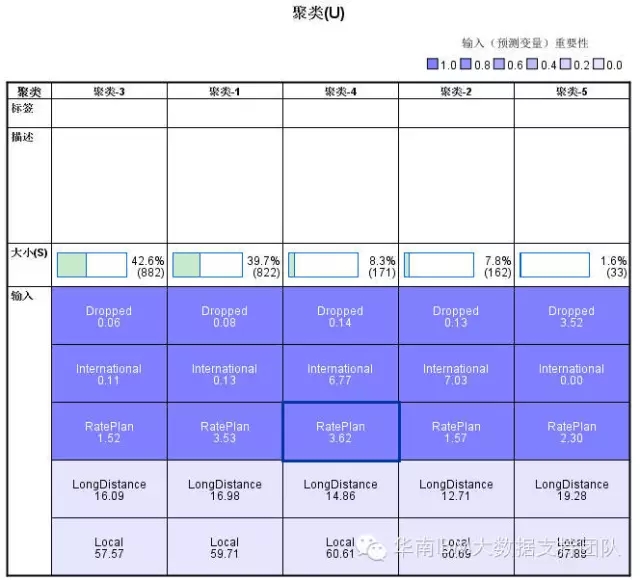
从上图中,我们可以清楚看到每个类别各个指标的平均值,可以先从数值上分析出各类有哪些指标比较异于其它类别,比如说,聚类5,掉线次数平均值为3.52,远远高于其它类别,这个从下面的箱图也可以明显看出(黑色框标识出)。
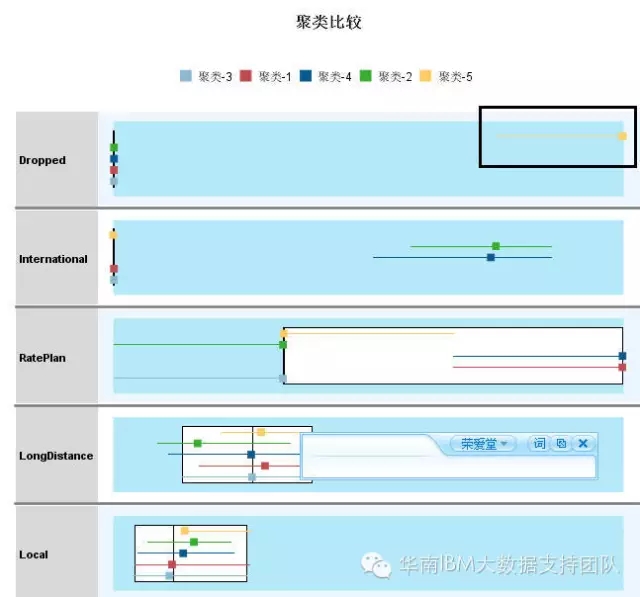
通过这两个图形,我们可以很快地找出每一类异于其它类别的特征,并从业务的角度来描述这一群人的特征,比如第5类,我们可以大概总结为:掉线次数最多,国际长途几乎没有,本地话费和长途话费最多等等。SPSS Modeler这样的分析展现结果,我们业务人员可以很好的结合自己的业务经验来对群组进行特征描述,然后根据每一类的特征,我们再根据我们的业务目标,制定营销策略或者是管理策略,这就是业务人员擅长的问题了。
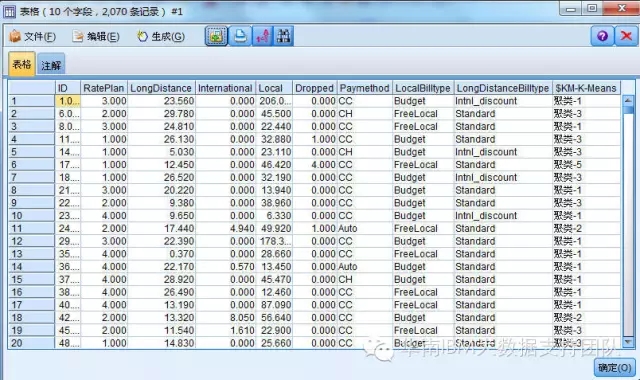
最终的分析结果,每个客户到底属于哪一类,我们直接通过表格就可以看到:
分析总结
从以上的例子,我们做下总结:1.从使用者的视角来看,R语言当然有它强大的地方,但对于不懂R语言编程或者不是很熟练的人员来说,还是会有一定的障碍,每个函数其实都包括了相关的参数,要搞懂这些参数必须查阅帮助文档,全是英文版本,如果英文不太好的话,又是另外的障碍。如果没有花费一定的时间,也不容易熟练地掌握R语言,而且对于最终模型的维护与优化也是要花时间与人力成本的。
2.从分析过程及结果来看,我们可以看到两个分析结果,虽然都是用了K-Means算法,都是分成5类,但结果截然不同,为什么呢?主要有两个原因:
(1)K-Means算法逻辑中,是用距离来做计算,因此一般要求分析前,需要对指标做归一化,如果0-1的指标与10000-100000的指标同时来计算距离的话,结果肯定会聚焦在10000-100000这个指标上,而上面用R计算的时候,我是没有做归一化的,那如果使用人员对这一逻辑不熟悉,那么出来的结果肯定会有问题。而SPSS Modeler里面的K-Means算法,它已经考虑了这个问题,在这个算法中,已经涵盖了将数据归一化这一处理,因此即使不太懂K-Means计算逻辑,使用这个算法,也不会有太大的问题。
(2)K-Means算法本身在选择初始中心点的时候,是随机的,因此也可能造成结果的不一致。
3.SPSS Modeler封装的算法,为了让不是很懂算法的人员也可以使用,它的算法里面会内嵌一些数据处理功能,还是以K-Means为例,本身K-Means只支持数值型数据,如果使用R平台,如果数据中有空白值,需要先处理,不然会报错。但SPSS Modeler中,如果数据有分类型数据,而且有些数据存在空白值,它仍然能够计算得到分析结果,也是缘于它已经提前做了数据处理,把分类型的转为数值型的,有空白值做了填补。这也是它为什么受业务人员或者是没有太多统计学背景的人员喜欢的原因。
4.R语言也有它自己非常大的优势,由于是开源的,它的算法非常广泛,特别是一些创新的算法,有时候使用者也非常希望可以尝试使用。IBM也看到了这一点,从SPSS Modeler 16版本起,已经封装了R节点,可以直接在SPSS Modeler的R节点上,编写R代码,引入新的算法;甚至还可以自己设计面板,自定义封装R算法,下次使用时,也不需要再修改代码,直接使用即可。如果大家对这个感兴趣,我们可以下回再做具体介绍。
SPSS Modeler的可视化、易用性不仅仅体现在它的图形化界面上,更多的是体现在它里面对算法封装时考虑的全面性,分析结果的可读性,即使你不太懂得统计分析,同样可以借助它来实现业务分析,带来业务价值。
SPSS Modeler 试用版下载地址:
http://bigdata.evget.com/product/168.html

相关文章推荐
- BMP图像数据格式详解
- 互联网新的产品形式——API接口和数据模块
- 环形ProgressBar特效
- ibatis 模糊查询和多条件查询
- Retrofit 2.0的改进以及使用
- 在Android Sudio中使用Uiautomator
- slf4J+logback日志多文件输出
- Mybatis Generator 最完整配置详解
- java注释规范
- 那些Android中的性能优化
- Fragment切换重新与不重新加载界面
- MySQL创建触发器实现统一主机下两个数据库的表同步
- Python Paramiko模块安装和使用
- php反射机制
- 如何把U盘设置为电脑锁
- Eclipse-----Debug Maven依赖Jar包找不到源码
- oracl 自增长序列 和触发器
- 【网络】Linux网络相关配置
- 敏捷BI比传统BI功能强大是否属实?
- java.lang.NoClassDefFoundError: org/activiti/image/ProcessDiagramGenerator