著名的卷积神经网络
2016-07-04 21:48
537 查看
AlexNet
网络结构
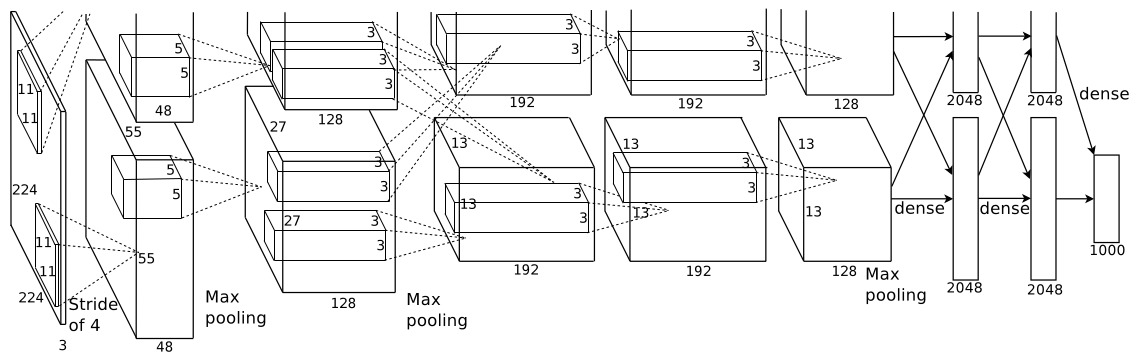
参数个数:参数主要集中在全连接层,全连接层的参数个数为6×6×256×4096+4096×4096+4096×1000=5.8622×107,卷积层的参数个数为2.33×106。可见,全连接层的参数个数大约占了96%.
卷积核的尺寸:11×11 with stride 4, 5×5 , 3×3
pooling核的尺寸:3×3 with stride 2
局部相应归一化层(LRN):模拟人脑的横向抑制
bix,y=aix,y/(k+α∑j=max(0,i−n/2)min(N−1,i+n/2)(ajx,y)2)β
Dropout:训练时fc6和fc7后面都有概率为0.5的dropout层。dropout的作用:
减少优化的参数量,避免过拟合。
打断节点之间的强联系。
在一定程度上等效模型平均,因为每一次迭代dropout都会随机丢弃节点,所以每一次迭代模型的结构都不同,相当于每次迭代都在训练不同的模型。
数据集
ILSVRC 2010, 1000个类, 120万张训练图片,5万张测试图片。数据集扩充:
1. 水平翻转。
2. 裁剪。输入图片是256×256,训练时逐像素裁剪227×227的patches(论文里是这个意思。论文中说patches是224×224的,这应该是个错误。)。测试的时候对一幅图片测试10次取平均值,左上,左下,右上,
右下,中心的5个patches,加上水平翻转。
3. 改变颜色值。按照我的理解,应该是先对RGB的协方差矩阵求特征值和特征向量,然后对一幅图像的所有像素加上一个关于特征值和特征向量的随机扰动。

训练
minibatch:128momentum:0.9
weight_decay:0.0005
weight_fillers:所有的权重都用N(0,0.01)初始化。第2,4,5,6,7,8层的偏置被初始化为1,是为了加速早期训练。如果所有偏置都初始化为0,那么很可能很多节点的激励为非正,此时梯度为0,训练会很慢。
lr_base:0.01
lr_policy:当验证误差不再减小时,lr乘以0.1,但最多乘上3次
Network in Network
网络结构
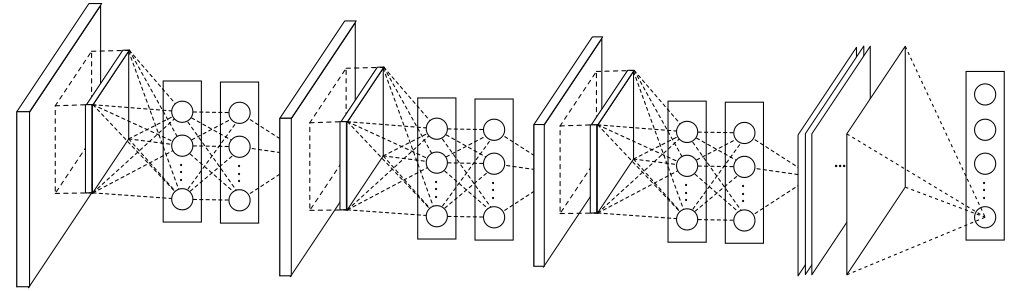
mlpconv:多层感知机卷积层,在两个卷积层之间加一个多层感知机。感知机的输入是多个卷积核对同一个patch的卷积结果,输出一个值作为下一层特征图对应位置的值。忽略非线性函数,多层感知机就是对多个卷积核的结果线性加权,所以实际可用1×1的卷积实现。
全局平均pooling:全连接层有很多参数,容易过拟合。现抛弃全连接层,全用卷积层。输入图的尺寸可以不固定,网络输出K个特征图,其中K是类别数。可以将输出的特征图解释成每个类别的置信图,对每个图内部求平均就可得到概率矢量。
训练
跟AlexNet基本一样数据集
Cifar-10, Cifar-100, SVHN, MNIST.预处理是全局对比度归一化和ZCA白化。VGG
网络结构
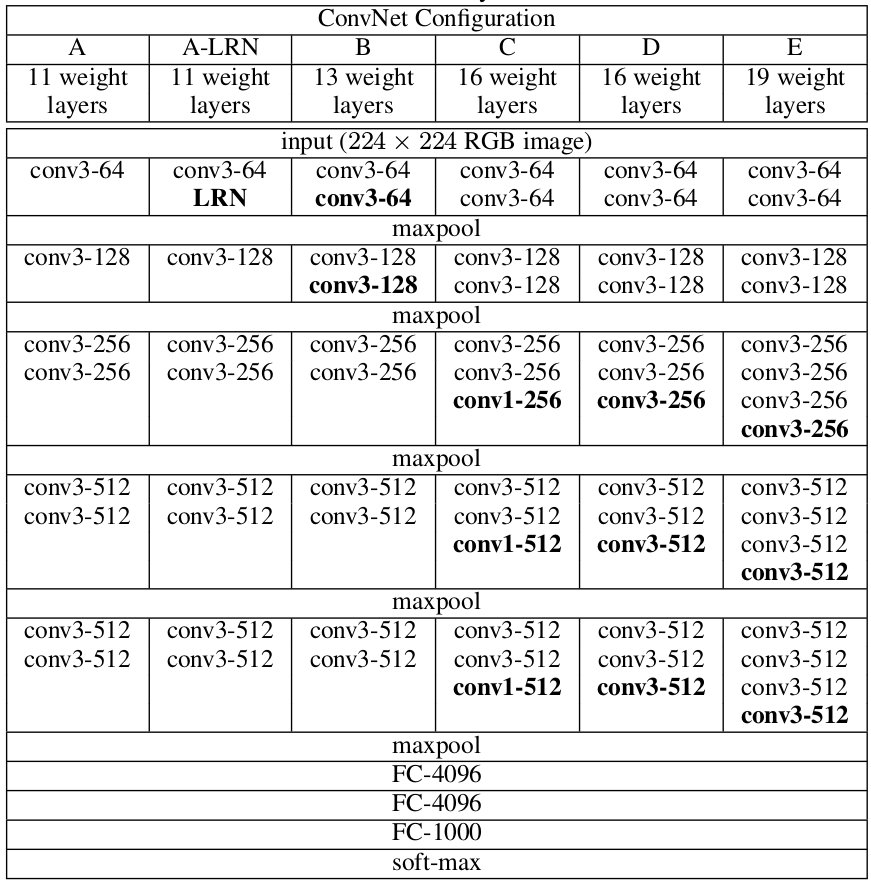
使用3×3卷积核,第3层的节点感受野是7×7。与直接使用7×7卷积核的1层隐层相比,使用3×3卷积核的3层隐层的好处:
1. 增加非线性。 相比而言,使用小的卷积核,当达到同样大小的感受野时,经过了更多的非线性函数。
2. 减少参数。假设层数都是C,使用7×7卷积核时的参数72C2=49C2。使用3×3卷积核时的参数3×32C2=27C2.
参数个数:

训练
训练方式跟AlexNet基本一样,连超参数都一样。比较特别的是深层网络的初始化。初始化:先训练较浅的net A,然后net B,C,D,E的前4层卷积层和后3层全连接层都用A的初始化。
数据集
训练
设S是缩放后图像短边的长度。有两种训练方案:1. 单尺度训练,S=256和S=384,然后crop224×224的patches
2. 多尺度训练,S∈[256,512],用S=384得到的网络权重初始化
测试
测试方案借鉴了OverFeat。首先将Fc层改写成Conv层,参数个数不变。此时网络中全是卷积,从任意大小的输入图出发可以得到K个概率特征图,K是类别数。然后对每个概率特征图求平均,就得到了K个类别的概率矢量。所以不要求测试图片的尺寸固定。测试时,也借鉴了GoogLeNet使用多crop的方案。
GoogleNet
深层理论
改善深度神经网络性能的最直接办法是增加网络的宽度和深度,然而这样做会带来两个问题:1. 参数增加,容易过拟合。
2. 计算量大,尤其当新增加的权重大多趋于0时,对计算资源的利用率低。
解决上述两个问题的方法是采用稀疏的连接结构,即使在卷积操作中。理论研究表明如果数据集的概率分布可由大的、非常稀疏的深度神经网络
表示,那么最优拓扑网络结构可通过以下方式逐层构建:分析前一层节点输出的相关性,根据相关性将节点聚类。这个结论也符合神经科学中的Hebbian原理:
一同兴奋的神经元之间有突触连接。
另一方面,如今的计算基础结构在遇到非均匀稀疏数据时会很不高效。即使使用稀疏矩阵,查找和缓存丢失的开销仍很大。而且,很多CPU和GPU的运算库都是为密集矩阵设计的,使用稀疏矩阵会大大降低效率。
以上这些自然引出一个问题:是否存在一种结构,既能利用额外的稀疏性,甚至在卷积中,又能以密集矩阵运算的方式利用计算资源。Inception正是作者们研究该问题得出的结构。
网络结构
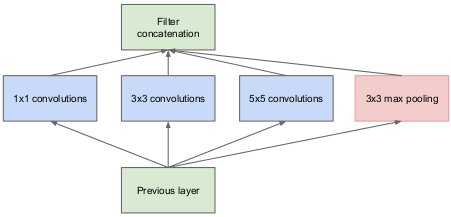
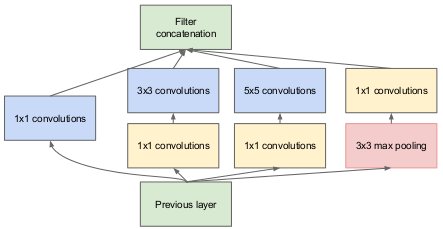
Inception:假设每一个节点都对应输入图像中的某一个区域,那么对应相同或相近区域的节点就能聚成一类。根据”Network in Network”理论,前一层同一类的节点可由下一层1×1的卷积操作覆盖。然而,即使同一类中的节点对应的区域也不可能完全一样,一类中所有节点对应的总区域很可能有一定的空间的跨度,所以除了1×1的卷积,还使用的3×3和5×5的卷积。因为池化在当下很流行,所以把池化也加了进来。
Inception的好处有:
1. 节点数增加,计算复杂度可控
2. 多尺度处理
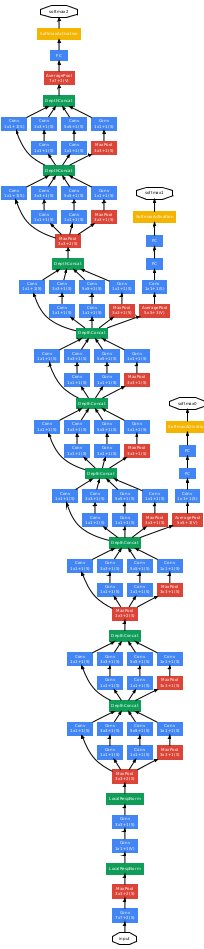
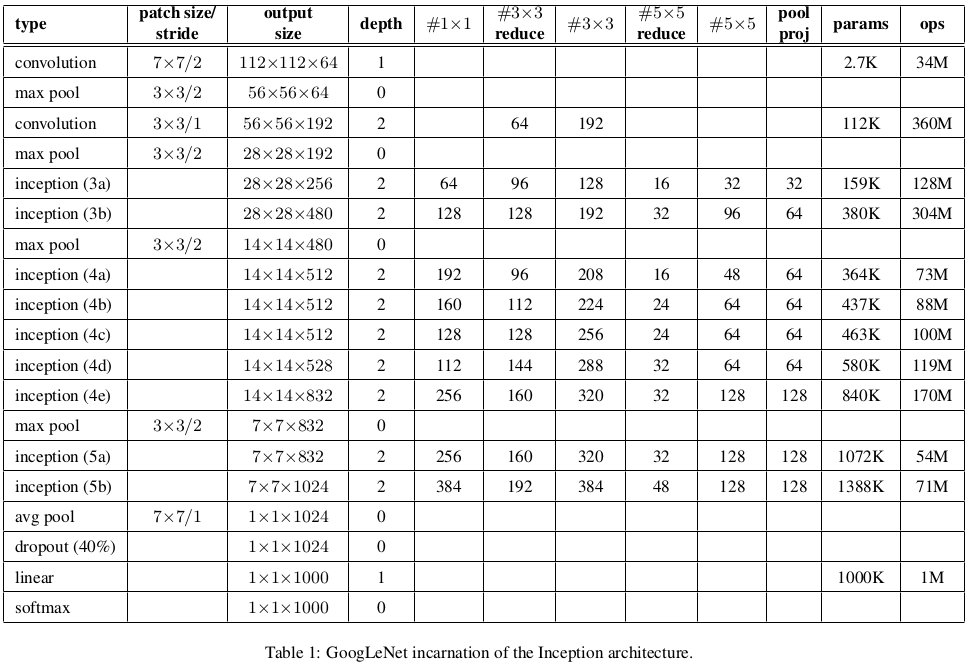
参数个数:680万,不到1千万。
卷积核尺寸:7×7 with stride 2,1×1,3×3,5×5
池化核尺寸:3×3 with stride 2(Inception外部), 7×7, 3×3 with stride 1(Inception内部)
训练
辅助分类器:强迫增加中间层特征的可区分性,测试时没有。momentum:0.9
lr_policy:每8个epochs降低4%
多个模型平均:不同的超参数,比如dropout和learning rate;不同的输入尺寸:patches的大小与原图比例在[0.08, 1]之间,长宽比在[1/4, 3/4]之间
数据集
ILSVRC2014,跟ILSVRC2012差别不大测试:将每副图片的短边分别缩放到256,288,320,352。然后crop左中右或上中下三个子图。接着在每个子图里面crop4个角和中心的224×224的patches,子图本身也会缩小到224×224。加上水平翻转,每副图片会测试144次取平均值。
ResNet
网络结构
单纯增加网络深度有两个弊端:1. 梯度消失/爆炸,可由初始化归一化和批归一化(Batch Normalization, BN)解决
2. 准确率退化,深层网络的误差反而大于浅层网络的误差。潜在原因可能是深层网络难以优化,无法通过增加深度解决。作者提出了残差学习的解决办法。


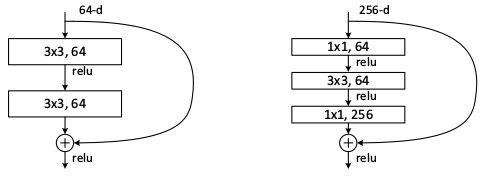
* 残差学习:准确率退化的原因可能是使用无法使用非线性函数的组合去逼近线性函数,作者使用shortcut连接显示将线性部分分离出来。假设一个网络需要学习潜在的映射H(x),通过shortcut连接,将H(x)显示拆分成线性部分x和非线性部分F(x),H(x)=F(x)+x。这样,网络的学习就是用非线性函数的组合去逼近非线性函数,而这种逼近已被证明能达到任意精度。
* Batch Normalization:卷积层之后,ReLU层之前
* 参数个数:
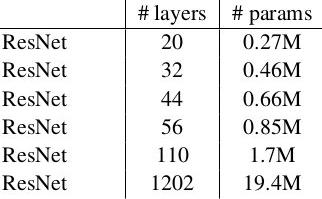
训练
minibatch:256weight_decay:0.0001
momentum:0.9
lr_rate:0.1
lr_policy:×0.1,当误差不再下降
dropout:无,因为有了BN
数据集
多尺度。训练集:[256, 480];测试集:{224, 256, 384, 480, 640}多crop。训练集:同GoogLeNet;测试集:AlexNet的10-crop testing
FractlNet
网络结构
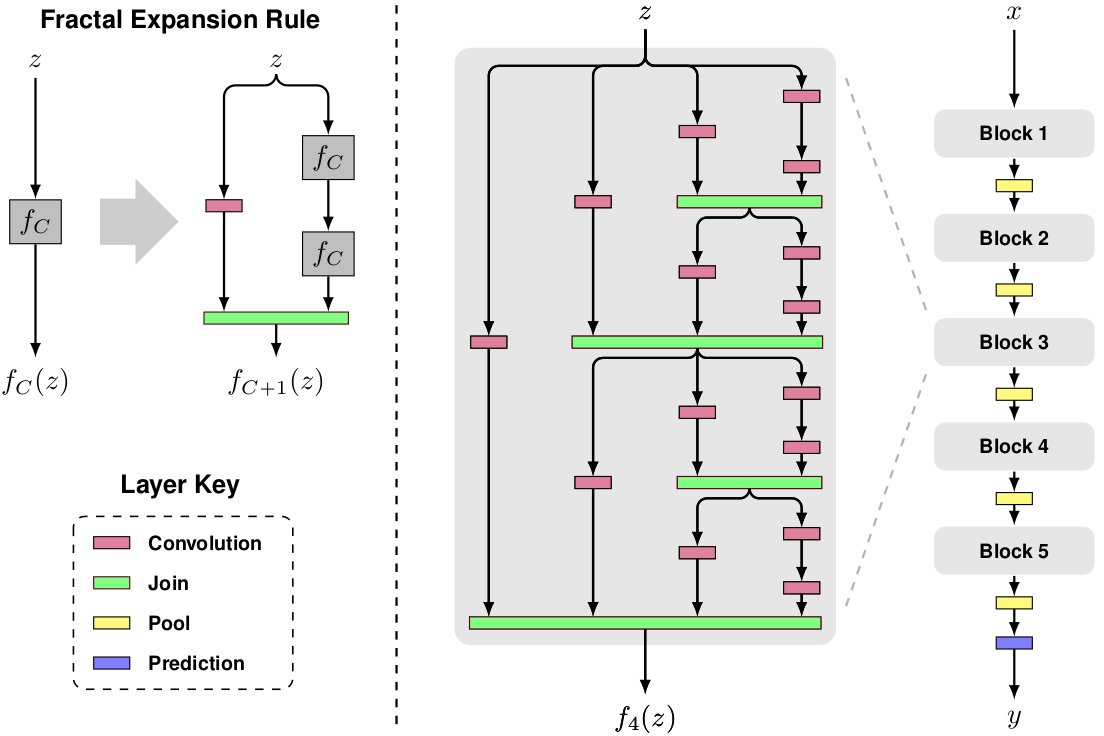
分形扩展:Block内部具有自相似性。join层的作用是逐像素取平均。一个Block的最大深度是2C−1,其中C是列数。
Batch Normalization:卷积之后,ReLU之前。
训练
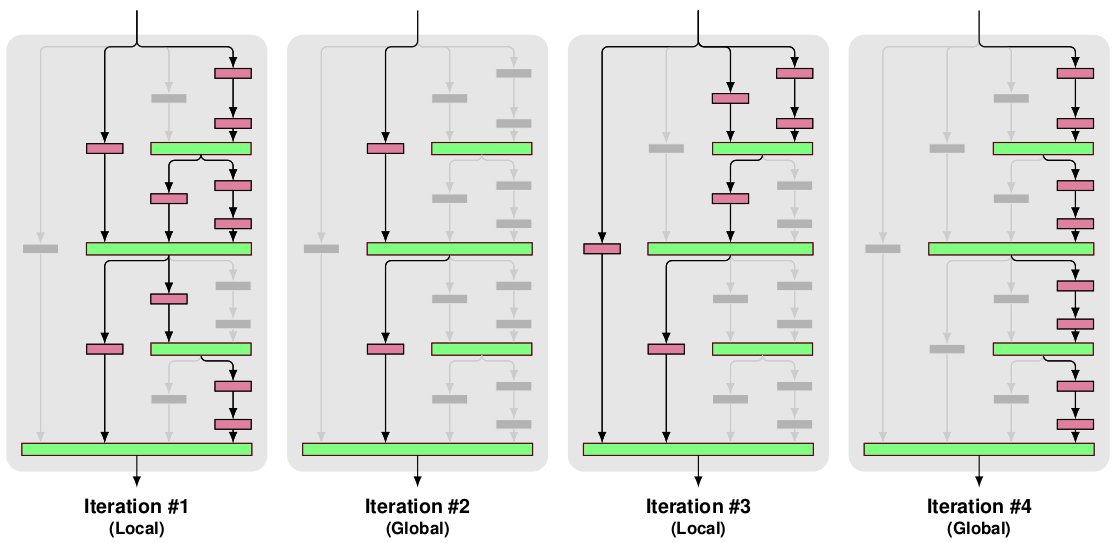
三种drop
dropout:每个bnlock的rate分别为(0%,10%,20%,30%,40%)
local drop-path:rate为15%.在block内部随机地将滤波器组无效化,但是确保join层至少有一个有效输入。
global drop-path:将block内部的3列无效化。
minibatch:100
初始化方式:Xavier
lr_rate:0.02
lr_policy: ×0.1,每当剩下的epochs减半
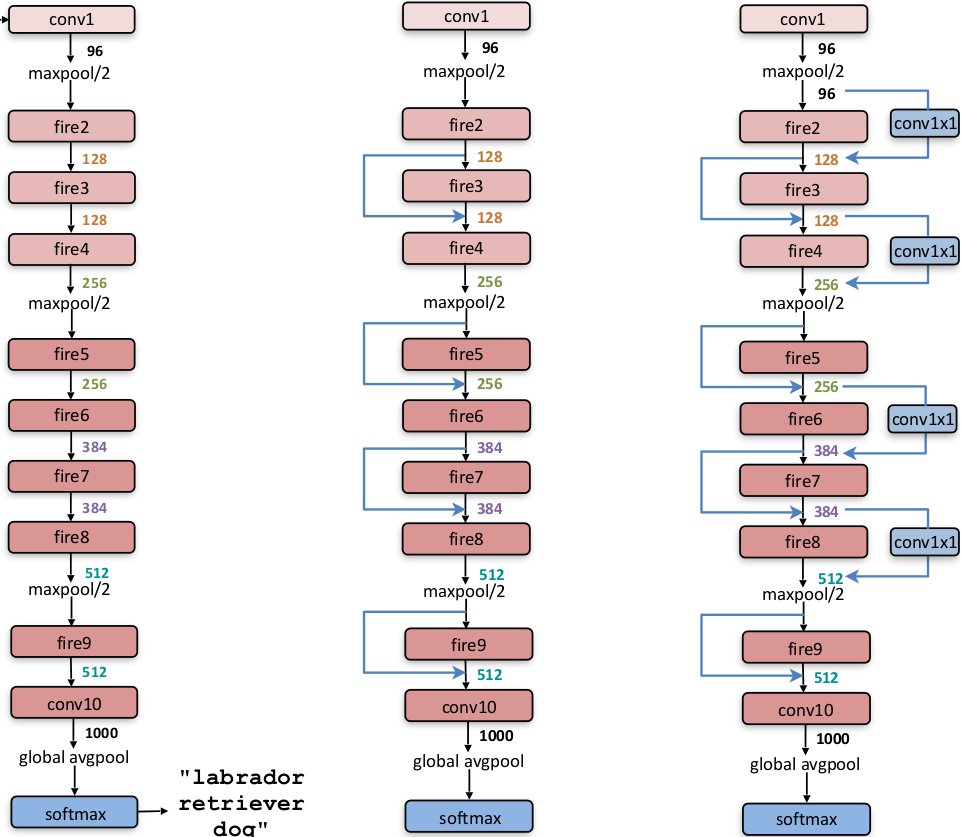
SqueezeNet
网络结构
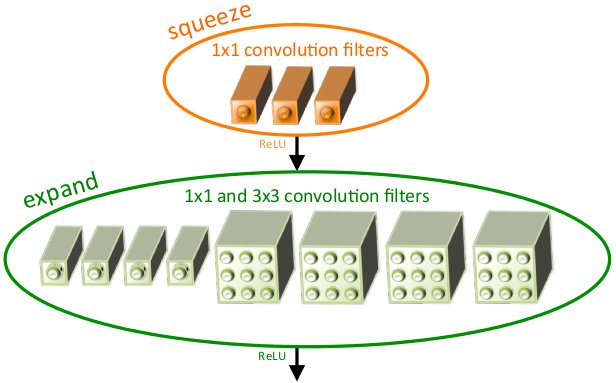
将3×3的卷积核替换成1×1的卷积核,参数减少9倍。
用1×1的卷积减少channels。假设前后两层的channels都是C,直接使用3×3卷积,参数个数为3×3×C×C=9C2;先用1×1的卷积减少一半channels,再使用3×3卷积的恢复,参数个数1×1×C×0.5C+3×3×0.5C×C=5C2;如果channels的恢复也用1×1的卷积,那么参数个数1×1×C×0.5C+3×3×0.5C×0.5C+1×1×0.5C×C=3.5C2.减少参数的同时,也可以增加了非线性。
以前的CNNs中较低层的卷积有较大的stride,所以网络中的特征图都比较小。作者反其道而行,只在较高层使用较大的stride,这样网络中的特征图都比较大。作者引用其他论文,说这样做能提高准确率。
fire module内部,squeeze卷积核的个数与expand卷积核的个数之比由ratio参数控制。expand内部,更多的3×3卷积核并没有比二者各占一半时的效果提升。
模型压缩
SVD,Network Pruning,Deep Compressio.其中,最后一种方法是减少数据的bit位数,降低数据精度。BinaryNet
网络结构
二值化:除了第一层的权重和最后一层的激励,其余层的权重和激励都只用±1.确定量化
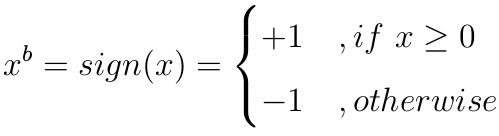
作者使用的是这个。
随机量化
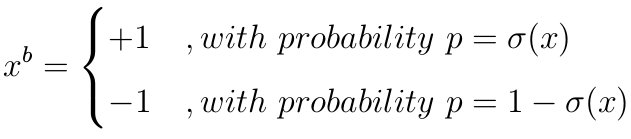
其中σ(x)=clip(x+12,0,1)
shift-based Batch Normalization:BN的近似,利用比特层面的移位操作减少乘加操作。
训练

)
前馈传播:权重二值化(除了第一层)→ BN得到激励 → 激励二值化(除了最后一层)
反向传播:关键是二值化的梯度的计算,Sign函数的导数在原点外处处为0,显然不能直接用。
q=sign(r)
gradr=gradg1|r|≤1
shift based AdaMax:Adam学习算法的变种。

相关文章推荐
- CUDA搭建
- 卷积神经网络初探
- 深入理解CNN的细节
- TensorFlow人工智能引擎入门教程所有目录
- convolutional neural network
- UFLDL Exercise: Convolutional Neural Network
- 使用深度卷积网络和支撑向量机实现的商标检测与分类的例子
- 对Pedestrian Detection aided by Deep Learning Semantic Tasks的小结
- 卷积神经网络知识要点
- CNN学习(一)
- CNN学习(一)
- 阅读 理解 思考 - Learning to Segment Object Candidates
- 卷积神经网络学习
- CNN: single-label to multi-label总结
- 总结:Large Scale Distributed Deep Networks
- 总结:One weird trick for parallelizing convolutional neural networks
- Extract CNN features using Caffe
- Deep Learning Face Attributes in the Wild
- 卷积神经网络CNN