机器学习:集成算法(随机森林,Adaboost)
2016-06-29 17:28
393 查看
单模型分类方法模型往往精度不高,如决策树, 容易出现过拟合问题,因此通过组合多个单分类模型来提高预测精度,这些方法称为分类器集成组合方法。
组合方法称为集成方法(ensemble method),可以是不同算法的集成,也可以是同一算法在不同设置下的集成,还可以是数据集不同部分分配给不同分类器之后的集成。集合方式有bagging,如random forest,Boosting(比如Adaboost,GBDT)都是其中典型的方法。
Bagging:基于数据随机重抽样的分类器构建方法。
自聚汇聚法(bootstrap aggregating),也称为bagging方法,是在从原始数据集选择S次后得到S个新数据集的一种技术。新数据集和原数据集的大小相等。
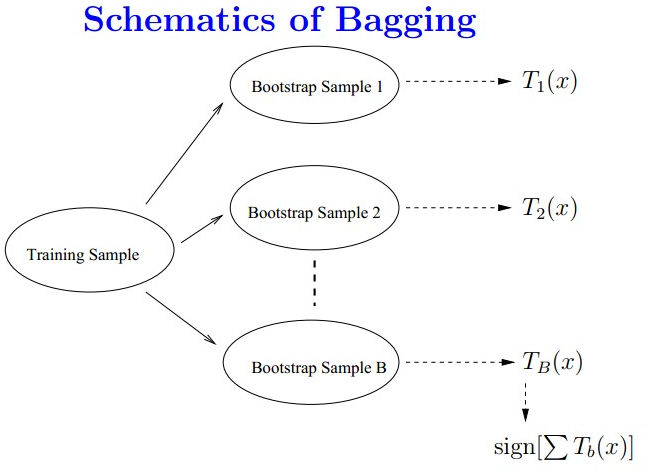
Bagging的策略:
随机森林
随机森林在bagging基础上做了修改。既可以处理属性为离散值的量,比如ID3算法,也可以处属性为连续值的量,比如C4.5算法。
随机森林( Random Forest,RF)是决策树的组合,每棵决策树都是通过对原始数据集中随机生成新的数据集来训练生成,随机森林决策的结果是多数决策树的决策结果。
因此要想明白随机森林,就应该先弄明白决策树。
决策树( decision tree)是一个树结构(一般取二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
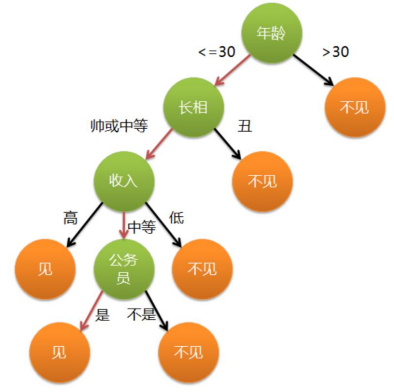
这里引用一个经典的例子。假设这个女孩对男人的要求是: 30岁以下、长相中等以上并且是高收入者或中等以上收入的公务员,年龄,长相,收入,是否公务员就是特征,可以用下图表示女孩的决策逻辑。
怎么选择特征进行树的构建,就需要具体看下id3,c4,5等算法。本文不作重点。
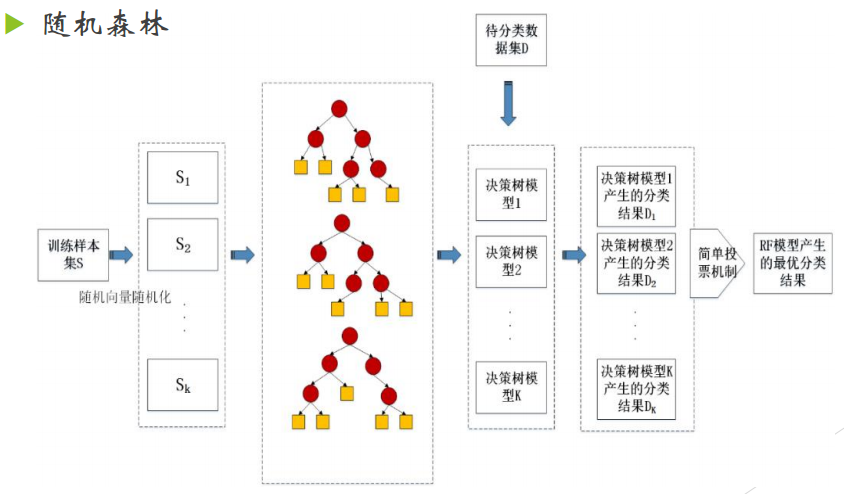
随机森林,是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。利用bootstrap重抽样方法从原始样本中抽取多个样本,然后对每个bootstrap样本进行决策树建模,在得到森林之后,当有一个新的输 入样本进入的时候,采用投票机制,让森林中的每一棵决策树分别进行一下判断,看看哪一类被选择最多,就预测这个样本为那一类。
核心思想在n个原始样本数据的范围内做有放回的抽样,样本容量仍为n,每个观测对象被抽到的概率相等,即为1/n.它是将样本看作整体,将样本中抽样得到的子样本看作样本,把所得到的这个子样本称为Bootstrap样本。
在建立每一棵决策树的过程中,有两点需要注意 : 采样与完全分裂。
1:首先是两个随机采样的过程,random forest对输入的数据要进行行、列的采样。对于行采样,采用有放回的方式,也就是在采样得到的样本集合中,可能有重复的样本。假设输入样本为N个,那么采样的样本也为N个。这样使得在训练的时候,每一棵树的输入样本都不是全部的样本,使得相对不容易出现over-fitting。然后进行列采样,从M 个feature中,选择m个(m < M)。此后过程保持m不变。
2:之后就是对采样之后的数据使用完全分裂的方式建立出决策树,这样决策树的某一个叶子节点要么是无法继续分裂的,要么里面的所有样本的都是指向的同一个分类。由于之前的两个随机采样的过程保证了随机性,所以就不用剪枝,也不会出现over-fitting。
按这种算法得到的随机森林中的每一棵都是很弱的,但是大家组合起来就很厉害了。每一棵决策树就是从M个feature中选择m让每一棵决策树进行学习,这样在随机森林中不同的树就有擅长不同的特征,对一个新的输入数据,可以用不同的角度去看待它,最终由各个树投票得到结果。
随机森林是一个最近比较火的算法,它有很多的优点:
缺点:
boosting
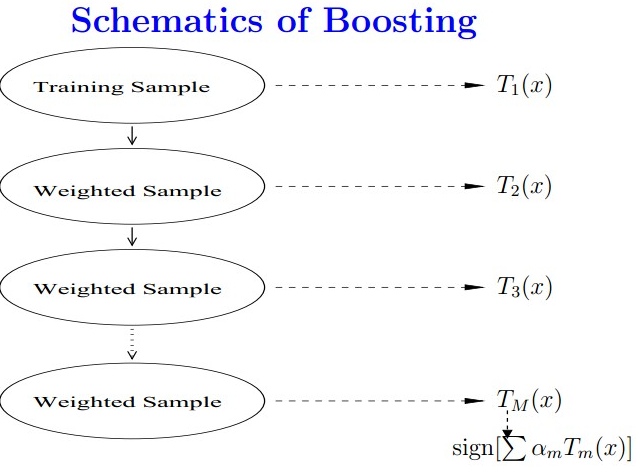
boosting是一种与bagging很相似的技术。但前者不同的分类器是通过串行训练而得到的,每个新分类器都根据已训练出的分类器的性能来进行训练。boosting中的分类的结果是基于所有分类器的加权求和结果的,使得loss function尽量考虑那些分错类的样本(i.e.分错类的样本weight大)。因此boosting与bagging不太一样。bagging中的分类器权值是相等的,而boosting中的分类器权重并不相等。
···待续···
组合方法称为集成方法(ensemble method),可以是不同算法的集成,也可以是同一算法在不同设置下的集成,还可以是数据集不同部分分配给不同分类器之后的集成。集合方式有bagging,如random forest,Boosting(比如Adaboost,GBDT)都是其中典型的方法。
Bagging:基于数据随机重抽样的分类器构建方法。
自聚汇聚法(bootstrap aggregating),也称为bagging方法,是在从原始数据集选择S次后得到S个新数据集的一种技术。新数据集和原数据集的大小相等。
Bagging的策略:
- 从样本集中用Bootstrap采样选出n个样本 - 在所有属性上,对这n个样本建立分类器(CART or SVM or ...) - 重复以上两步m次,i.e.build m个分类器(CART or SVM or ...) - 将数据放在这m个分类器上跑,最后vote看到底分到哪一类
随机森林
随机森林在bagging基础上做了修改。既可以处理属性为离散值的量,比如ID3算法,也可以处属性为连续值的量,比如C4.5算法。
随机森林( Random Forest,RF)是决策树的组合,每棵决策树都是通过对原始数据集中随机生成新的数据集来训练生成,随机森林决策的结果是多数决策树的决策结果。
因此要想明白随机森林,就应该先弄明白决策树。
决策树( decision tree)是一个树结构(一般取二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
这里引用一个经典的例子。假设这个女孩对男人的要求是: 30岁以下、长相中等以上并且是高收入者或中等以上收入的公务员,年龄,长相,收入,是否公务员就是特征,可以用下图表示女孩的决策逻辑。
怎么选择特征进行树的构建,就需要具体看下id3,c4,5等算法。本文不作重点。
随机森林,是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。利用bootstrap重抽样方法从原始样本中抽取多个样本,然后对每个bootstrap样本进行决策树建模,在得到森林之后,当有一个新的输 入样本进入的时候,采用投票机制,让森林中的每一棵决策树分别进行一下判断,看看哪一类被选择最多,就预测这个样本为那一类。
核心思想在n个原始样本数据的范围内做有放回的抽样,样本容量仍为n,每个观测对象被抽到的概率相等,即为1/n.它是将样本看作整体,将样本中抽样得到的子样本看作样本,把所得到的这个子样本称为Bootstrap样本。
在建立每一棵决策树的过程中,有两点需要注意 : 采样与完全分裂。
1:首先是两个随机采样的过程,random forest对输入的数据要进行行、列的采样。对于行采样,采用有放回的方式,也就是在采样得到的样本集合中,可能有重复的样本。假设输入样本为N个,那么采样的样本也为N个。这样使得在训练的时候,每一棵树的输入样本都不是全部的样本,使得相对不容易出现over-fitting。然后进行列采样,从M 个feature中,选择m个(m < M)。此后过程保持m不变。
2:之后就是对采样之后的数据使用完全分裂的方式建立出决策树,这样决策树的某一个叶子节点要么是无法继续分裂的,要么里面的所有样本的都是指向的同一个分类。由于之前的两个随机采样的过程保证了随机性,所以就不用剪枝,也不会出现over-fitting。
按这种算法得到的随机森林中的每一棵都是很弱的,但是大家组合起来就很厉害了。每一棵决策树就是从M个feature中选择m让每一棵决策树进行学习,这样在随机森林中不同的树就有擅长不同的特征,对一个新的输入数据,可以用不同的角度去看待它,最终由各个树投票得到结果。
随机森林是一个最近比较火的算法,它有很多的优点:
在数据集上表现良好 在当前的很多数据集上,相对其他算法有着很大的优势 它能够处理很高维度(feature很多)的数据,并且不用做特征选择 在训练完后,它能够给出哪些feature比较重要 在创建随机森林的时候,对generlization error使用的是无偏估计 训练速度快 在训练过程中,能够检测到feature间的互相影响 容易做成并行化方法 实现比较简单
缺点:
随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟. 对于有不同级别的属性的数据,级别划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的。
boosting
boosting是一种与bagging很相似的技术。但前者不同的分类器是通过串行训练而得到的,每个新分类器都根据已训练出的分类器的性能来进行训练。boosting中的分类的结果是基于所有分类器的加权求和结果的,使得loss function尽量考虑那些分错类的样本(i.e.分错类的样本weight大)。因此boosting与bagging不太一样。bagging中的分类器权值是相等的,而boosting中的分类器权重并不相等。
boosting重采样的不是样本,而是样本的分布,对于分类正确的样本权值低,分类错误的样本权值高(通常是边界附近的样本),最后的分类器是很多弱分类器的线性叠加(加权组合).
···待续···

相关文章推荐
- 书评:《算法之美( Algorithms to Live By )》
- 动易2006序列号破解算法公布
- C#递归算法之分而治之策略
- Ruby实现的矩阵连乘算法
- C#插入法排序算法实例分析
- C#算法之大牛生小牛的问题高效解决方法
- C#算法函数:获取一个字符串中的最大长度的数字
- 超大数据量存储常用数据库分表分库算法总结
- C#数据结构与算法揭秘二
- C#冒泡法排序算法实例分析
- 算法练习之从String.indexOf的模拟实现开始
- C#算法之关于大牛生小牛的问题
- C#实现的算24点游戏算法实例分析
- 经典排序算法之冒泡排序(Bubble sort)代码
- c语言实现的带通配符匹配算法
- 浅析STL中的常用算法
- 算法之排列算法与组合算法详解
- C++实现一维向量旋转算法
- Ruby实现的合并排序算法
- C#折半插入排序算法实现方法