Elasticsearch 2.3.3 搜索引擎的elasticsearch-jdbc插件安装
2016-06-29 12:14
417 查看
摘要: Elasticsearch 2.3.3的jdbc插件安装跟之前的版本是不一样的,之前的版本,网上的内容介绍的都是elasticsearch使用river同步mysql数据 ,哪些都是老的文章了,最新的版本是不适用的
Elasticsearch 2.3.3的jdbc插件安装跟之前的版本是不一样的,之前的版本,网上的内容介绍的都是elasticsearch使用river同步mysql数据 ,哪些都是老的文章了,最新的版本是不适用的。那么我们如何从数据库导入数据呢?其实安装 Elasticsearch 2.3.3 的JDBC插件很简单,只不过,安装完以后的配置,稍微有些麻烦。
第一步:下载JDBC链接包
具体可以执行下面的命令:
Elasticsearch 2.3.3的jdbc插件安装跟之前的版本是不一样的,之前的版本,网上的内容介绍的都是elasticsearch使用river同步mysql数据 ,哪些都是老的文章了,最新的版本是不适用的。那么我们如何从数据库导入数据呢?其实安装 Elasticsearch 2.3.3 的JDBC插件很简单,只不过,安装完以后的配置,稍微有些麻烦。
第一步:下载JDBC链接包
具体可以执行下面的命令:
wget http://xbib.org/repository/org/xbib/elasticsearch/importer/elasticsearch-jdbc/2.3.3.0/elasticsearch-jdbc-2.3.3.0-dist.zip[/code]
第二步: 解压 elasticsearch-jdbc-2.3.3.0-dist.zipunzip elasticsearch-jdbc-2.3.3.0-dist.zip
第三步:进入elasticsearch-jdbc-2.3.3.0/bin目录
我们看到下面有很多链接数据库的样例文件。
我们以MSYQL为例,做一个基本的介绍。
第四步:编辑mysql-blog.sh,修改成如下的样子。#!/bin/sh DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )" bin=${DIR}/../bin lib=${DIR}/../lib echo ' { "type" : "jdbc", "jdbc" : { "url" : "jdbc:mysql://192.168.1.100:3306/hotel?useUnicode=true&characterEncoding=gbk", "statefile" : "statefile.json", "user" : "root", "password" : "root", "sql" : "select * from hotel", "index" : "hotel", "type" : "hotel", "elasticsearch" : { "cluster" : "elasticsearch", "host" : "192.168.133.134", "port" : 9300 } } } ' | java \ -cp "${lib}/*" \ -Dlog4j.configurationFile=${bin}/log4j2.xml \ org.xbib.tools.Runner \ org.xbib.tools.JDBCImporter
上述脚本的意思是:链接192.168.1.100这个机器上的hotel数据库,将此数据库中的hotel数据全部导入到hotel索引中。导入的集群名称是elasticsearch,搜索引擎访问地址是192.168.133.132.
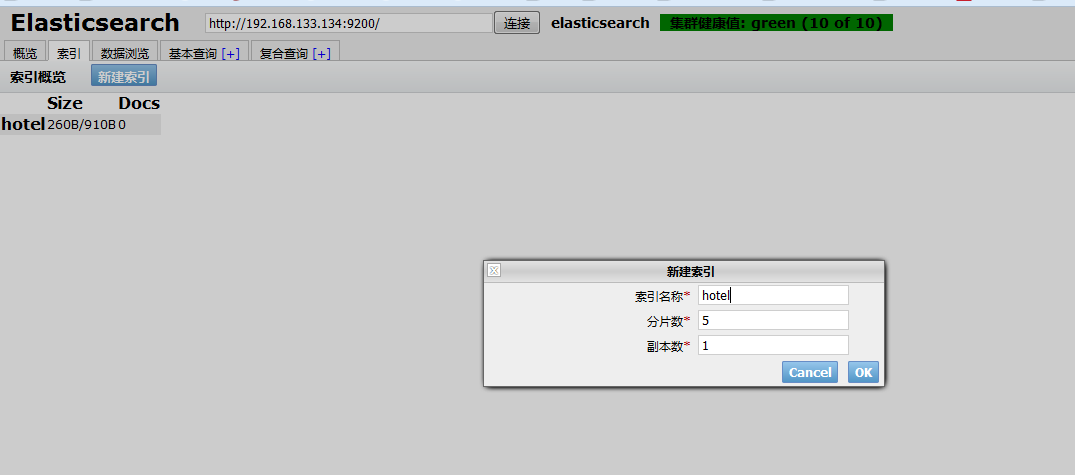
第五步,结合之前的内容,我们搭建了 elasticsearch 集群,但是没有建立索引。
我们可以再head插件中新建索引.
索引创建成功后,我们可以在 “概览”里面看到新建的索引。
暂且不表分片和复制。我们看到我们成功了创建了一个hotel索引,目前索引中文档个数为0.
第六步,执行刚才修改的mysql-blog.sh脚本。
执行之前确定你的Mysql数据库已经启动,并且数据库的链接账号和密码存在。
我的数据库中是5W条酒店的数据。
脚本执行完成后,5W条数据从导入到索引创建完成,大约是2分钟,速度还是蛮快的。,我们再次查看head插件,可以看到,文件个数已经发生了变化。
好了,本篇文章就写到这里,其实ElasticSerach-jdbc导入数据还有很多的参数。
大家可以看https://github.com/jprante/elasticsearch-jdbc 文章,或者点击链接观看 数航教育的在线视频教程






相关文章推荐
- 巧用mysql提示符prompt清晰管理数据库的方法
- 两大步骤教您开启MySQL 数据库远程登陆帐号的方法
- phpmyadmin 4+ 访问慢的解决方法
- linux系统下实现mysql热备份详细步骤(mysql主从复制)
- CentOS 5.5下安装MySQL 5.5全过程分享
- MySQL复制的概述、安装、故障、技巧、工具(火丁分享)
- MySQL中删除重复数据的简单方法
- MySQL5.5.21安装配置教程(win7)
- 使用ElasticSearch6.0快速实现全文搜索功能的示例代码
- elasticsearch批量数据导入和导出
- 使用ElasticSearch+LogStash+Kibana+Redis搭建日志管理服务
- ElasticSearch 使用心得
- ES中如何使用逗号来分词
- ElasticSearch 守护进程 JSW
- elasticsearch2.3安装以及集群部署
- elasticsearch增删改查
- Elasticsearch2.2.0数据操作
- Elasticsearch2.2.0安装ik中文分词
- Elasticsearch2.2.0安装pinyin插件
- Elasticsearch Client(JAVA API) JAVA实例