SPP-Net 与 RCNN 网络的区别
2016-06-28 18:17
281 查看
RCNN 与 SPP-Net网络区别
RCNN 详解
说了这么多有关object detection的个人见解,我还是说说这个跨时代的RCNN吧,如果我写的不够详细的话,我相信大家在别的博客上也能看到RCNN的介绍。流程图大家应该都比较熟悉了, 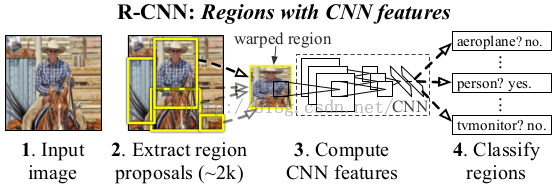
RCNN全程就是Regions with CNN features,从名字也可以看出,RCNN的检测算法是基于传统方法来找出一些可能是物体的区域,再把该区域的尺寸归一化成卷积网络输入的尺寸,最后判断该区域到底是不是物体,是哪个物体,以及对是物体的区域进行进一步回归的微微调整(与深度学习里的finetune去分开,我想表达的就只是对框的位置进行微微调整)学习,使得框的更加准确。这就是主要的思路,我去,直接说完了??还是再说一下具体细节吧,这样也好为下一章过渡一下,哈哈。
正如上面所说的,RCNN的核心思想就是把图片区域内容送给深度网络,然后提取出深度网络某层的特征,并用这个特征来判断是什么物体(文章把背景也当成一种类别,故如果是判断是不是20个物体时,实际上在实现是判断21个类。),最后再对是物体的区域进行微微调整。实际上文章内容也说过用我之前所说的方法(先学习分类器,然后sliding windows),不过论文用了更直观的方式来说明这样的消耗非常大。它说一个深度网络(alexNet)在conv5上的感受野是195×195,按照我的理解,就是195×195的区域经过五层卷积后,才变成一个点,所以想在conv5上有一个区域性的大小(7×7)则需要原图为227×227,这样的滑窗每次都要对这么大尺度的内容进行计算,消耗可想而知,故论文得下结论,不能用sliding
windows的方式去做检测(消耗一次用的不恰当,望各位看官能说个更加准确的词)。不过论文也没有提为什么作者会使用先找可能区域,再进行判断这种方式,只是说他们根据09年的另一篇论文[1],而做的。这也算是大神们与常人不同的积累量吧。中间的深度网络通过ILSVRC分类问题来进行训练,即利用训练图片和训练的分类监督信号,来学习出这个网络,再根据这个网络提取的特征,来训练21个分类器和其相应的回归器,不过分类器和回归器可以放在网络中学习,这也是下面要讲的Fast RCNN的内容。
最后补充一下大牛们的针对rcnn的创新思路吧,从上面图片我们可以把RCNN看成四个部分,ss提proposals,深度网络提特征,训练分类器,训练对应回归器,这四个是相对独立的,每种算法都有它的缺陷,那么我们如何对它进行改进呢?如果让你现在对这个算法进行改进,该怎么改进呢??首先肯定能想到的是,如何让深度网络更好的训练,之前训练只用了分类信息,如果先利用ground truth信息把图片与object 无关的内容先cut掉,然后再把cut后的图片用于深度网络的训练,这样训练肯定会更好。这是第一种思路,另外如果把最后两个放在一起训练,并放入深度网络中,这就是joint
learning,也就是Fast RCNN的内容,如果把ss也放入深度网络中,成为一个大的网络,则是Faster RCNN的内容。这也就是后面一系列论文的思路了。(这个如何创新的思维是从某某公司的深度学习讲座听到的,我只是深刻学习后地一名合格的搬运工,哈哈。)
SPP-Net 网络
如下图所示,由于传统的CNN限制了输入必须固定大小(比如AlexNet是224x224),所以在实际使用中往往需要对原图片进行crop或者warp的操作
crop:截取原图片的一个固定大小的patch
warp:将原图片的ROI缩放到一个固定大小的patch
无论是crop还是warp,都无法保证在不失真的情况下将图片传入到CNN当中。
crop:物体可能会产生截断,尤其是长宽比大的图片。
warp:物体被拉伸,失去“原形”,尤其是长宽比大的图片

Sptial Pyramid Pooling,以下简称SPP,为的就是解决上述的问题,做到的效果为:不管输入的图片是什么尺度,都能够正确的传入网络。
思路很直观,首先发现了,CNN的卷积层是可以处理任意尺度的输入的,只是在全连接层处有限制尺度——换句话说,如果找到一个方法,在全连接层之前将其输入限制到等长,那么就解决了这个问题。
然后解决问题的方法就是SPP了。
从BoW到SPM
SPP的思想来源于SPM,然后SPM的思想来源自BoW。关于BoW和SPM,找到了两篇相关的博文,就不在这里展开了。
第九章三续:SIFT算法的应用—目标识别之Bag-of-words模型
Spatial Pyramid 小结
最后做到的效果如下图:

如果原图输入是224x224,对于conv5出来后的输出,是13x13x256的,可以理解成有256个这样的filter,每个filter对应一张13x13的reponse map。
如果像上图那样将reponse map分成4x4 2x2 1x1三张子图,做max pooling后,出来的特征就是固定长度的(16+4+1)x256那么多的维度了。
如果原图的输入不是224x224,出来的特征依然是(16+4+1)x256
直觉地说,可以理解成将原来固定大小为(3x3)窗口的pool5改成了自适应窗口大小,窗口的大小和reponse map成比例,保证了经过pooling后出来的feature的长度是一致的
如何训练网络
理论上说,SPP-net支持直接以多尺度的原始图片作为输入后直接BP即可。实际上,caffe等实现中,为了计算的方便,输入是固定了尺度了的。所以为了使得在固定输出尺度的情况下也能够做到SPP-net的效果,就需要定义一个新的SSP-layer
作者以输入224x224举例,这时候conv5出来的reponse map为13x13,计算出来的步长如下图所示。

具体的计算方法,看一眼2.3的Single-size training部分就明白了。
如果输入改成180x180,这时候conv5出来的reponse map为10x10,类似的方法,能够得到新的pooling参数。
两种尺度下,在SSP后,输出的特征维度都是(9+4+1)x256,之后接全连接层即可。
训练的时候,224x224的图片通过随机crop得到,180x180的图片通过缩放224x224的图片得到。之后,迭代训练,即用224的图片训练一个epoch,之后180的图片训练一个epoth,交替地进行。
如何测试网络
作者说了一句话:Note that the above single/multi-size solutions are for training only. At the testing stage, it is straightforward to apply SPP-net on images of any sizes.笔者觉得没有那么简单吧,毕竟caffe对于test网络也是有固定尺度的要求的。
实验
之后是大量的实验。分类实验
如下图,一句话概括就是,都有提高。
一些细节:
为了保证公平,test时候的做法是将图片缩放到短边为256,然后取10crop。这里的金字塔为{6x6 3x3 2x2 1x1}(笔者注意到,这里算是增加了特征,因为常规pool5后来说,只有6x6;这里另外多了9+4+1个特征)
作者将金字塔减少为{4x4 3x3 2x2 1x1},这样子,每个filter的feature从原来的36减少为30,但依然有提高。(笔者认为这个还是保留意见比较好)
其实这部分的实验比较多,详见论文,不在这里写了。
在ILSVRC14上的cls track,作者是第三名
定位实验
这里详细说说笔者较为关心的voc07上面的定位实验用来对比的对象是RCNN。
方法简述:
提取region proposal部分依然用的是selective search
CNN部分,结构用的是ZF-5(单尺度训练),金字塔用了{6x6 3x3 2x2 1x1},共50个bin
分类器也是用了SVM,后处理也是用了cls-specific regression
所以主要差别是在第二步,做出的主要改进在于SPP-net能够一次得到整个feature map,大大减少了计算proposal的特征时候的运算开销。
具体做法,将图片缩放到s∈{480,576,688,864,1200}的大小,于是得到了6个feature map。尽量让region在s集合中对应的尺度接近224x224,然后选择对应的feature map进行提取。(具体如何提取?后面的附录会说)
最后效果如图:

准确率从58.5提高到了59.2,而且速度快了24x
如果用两个模型综合,又提高了一点,到60.9

附录
如何将图像的ROI映射到feature map?
说实话,笔者还是没有完全弄懂这里的操作。先记录目前能够理解的部分。总体的映射思路为:In our implementation, we project the corner point of a window onto a pixel in the feature maps, such that this corner point (in the image
domain) is closest to the center of the receptive field of that pixel.
略绕,我的理解是:
映射的是ROI的两个角点,左上角和右下角,这两个角点就可以唯一确定ROI的位置了。
将feature map的pixel映射回来图片空间
从映射回来的pixel中选择一个距离角点最近的pixel,作为映射。
如果以ZF-5为例子,具体的计算公式为:

这里有几个变量
139代表的是感受野的直径,计算这个也需要一点技巧了:如果一个filter的kernelsize=x,stride=y,而输出的reponse map的长度是n,那么其对应的感受野的长度为:n+(n-1)*(stride-1)+2*((kernelsize-1)/2)

16是effective stride,这里笔者理解为,将conv5的pixel映射到图片空间后,两个pixel之间的stride。(计算方法,所有stride连乘,对于ZF-5为2x2x2x2=16)
63和75怎么计算,还没有推出来。。。。囧
RCNN 与 SPP-Net网络区别
一。RCNN:
1、首先通过选择性搜索,对待检测的图片进行搜索出2000个候选窗口。
2、把这2k个候选窗口的图片都缩放到227*227,然后分别输入CNN中,每个候选窗台提取出一个特征向量,也就是说利用CNN进行提取特征向量。
3、把上面每个候选窗口的对应特征向量,利用SVM算法进行分类识别。
可以看到R-CNN计算量肯定很大,因为2k个候选窗口都要输入到CNN中,分别进行特征提取,计算量肯定不是一般的大。
二。SPPnet:
1、首先通过选择性搜索,对待检测的图片进行搜索出2000个候选窗口。这一步和R-CNN一样。
2、特征提取阶段。这一步就是和R-CNN最大的区别了,同样是用卷积神经网络进行特征提取,但是SPP-Net用的是金字塔池化。这一步骤的具体操作如下:把整张待检测的图片,输入CNN中,进行一次性特征提取,得到feature maps,然后在feature maps中找到各个候选框的区域,再对各个候选框采用金字塔空间池化,提取出固定长度的特征向量。而R-CNN输入的是每个候选框,然后在进入CNN,因为SPP-Net只需要一次对整张图片进行特征提取,速度是大大地快啊。江湖传说可一个提高100倍的速度,因为R-CNN就相当于遍历一个CNN两千次,而SPP-Net只需要遍历1次。
3、最后一步也是和R-CNN一样,采用SVM算法进行特征向量分类识别。
三。一个问题:
如何在feature maps中找到原始图片中候选框的对应区域?
因为候选框是通过一整张原图片进行检测得到的,而feature maps的大小和原始图片的大小是不同的,feature maps是经过原始图片卷积、下采样等一系列操作后得到的。那么我们要如何在feature maps中找到对应的区域呢?Mapping a Window to Feature Maps。作者直接给出了一个很方便我们计算的公式:假设(x’,y’)表示特征图上的坐标点,坐标点(x,y)表示原输入图片上的点,那么它们之间有如下转换关系:
(x,y)=(S*x’,S*y’)
其中S的就是CNN中所有的strides的乘积。比如paper所用的ZF-5:
S=2*2*2*2=16
而对于Overfeat-5/7就是S=12,这个可以看一下下面的表格:
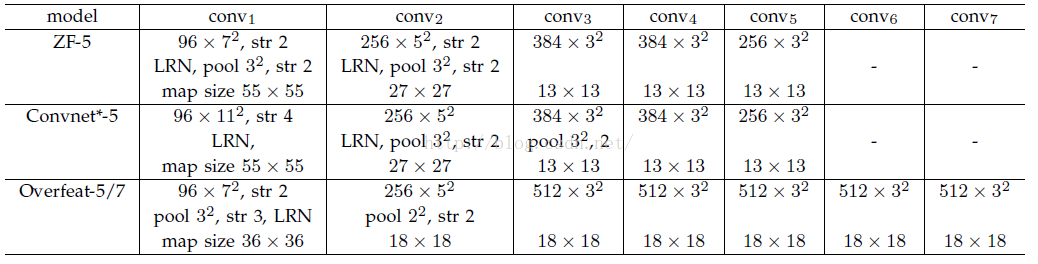
需要注意的是Strides包含了池化、卷积的stride。自己计算一下Overfeat-5/7(前5层)是不是等于12。
反过来,我们希望通过(x,y)坐标求解(x’,y’),那么计算公式如下:
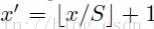
因此我们输入原图片检测到的windows,可以得到每个矩形候选框的四个角点,然后我们再根据公式:
Left、Top:
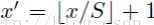
Right、Bottom:
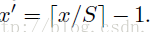

相关文章推荐
- ajax原理和XmlHttpRequest对象
- rtp/rtcp header
- angular $http 官方实例说明
- handler、HttpURLConnection、网络数据下载综合使用。
- 用CHttpFile实现简单的GET/POST数据【转】
- http://www.douco.com/help
- tcpdump非常实用的抓包实例
- TCP之文件传输
- 卷积神经网络反向BP算法公式推导
- http url转义字符,特殊字符
- OkHttp使用(三)文件上传
- 网络字节序转换
- http://www.cnblogs.com/linjiqin/archive/2013/05/27/3101694.html
- 验证视图状态 MAC 失败。如果此应用程序由网络场或群集承载,请确保<machineKey>配置指定了相同的 validationKey 和验证算法。不能在群集中使用 AutoGenerate。
- http_ui查询接口配置
- 企业级日志收集系统——ELKstack 推荐
- 计算机网络基础知识
- c# tcp socket 通信
- HttpClient,DefaultHttpClient使用详解
- NodeJS 创建TCP服务器 客户端