POJ Shortest Prefixes -- 最短前缀问题 -- 字典树
2016-06-24 14:00
369 查看
Shortest Prefixes
Description
A prefix of a string is a substring starting at the beginning of the given string. The prefixes of "carbon" are: "c", "ca", "car", "carb", "carbo", and "carbon". Note that the empty string is not considered a prefix in this problem, but every non-empty string
is considered to be a prefix of itself. In everyday language, we tend to abbreviate words by prefixes. For example, "carbohydrate" is commonly abbreviated by "carb". In this problem, given a set of words, you will find for each word the shortest prefix that
uniquely identifies the word it represents.
In the sample input below, "carbohydrate" can be abbreviated to "carboh", but it cannot be abbreviated to "carbo" (or anything shorter) because there are other words in the list that begin with "carbo".
An exact match will override a prefix match. For example, the prefix "car" matches the given word "car" exactly. Therefore, it is understood without ambiguity that "car" is an abbreviation for "car" , not for "carriage" or any of the other words in the list
that begins with "car".
Input
The input contains at least two, but no more than 1000 lines. Each line contains one word consisting of 1 to 20 lower case letters.
Output
The output contains the same number of lines as the input. Each line of the output contains the word from the corresponding line of the input, followed by one blank space, and the shortest prefix that uniquely (without ambiguity) identifies this word.
Sample Input
Sample Output
Source
ac:
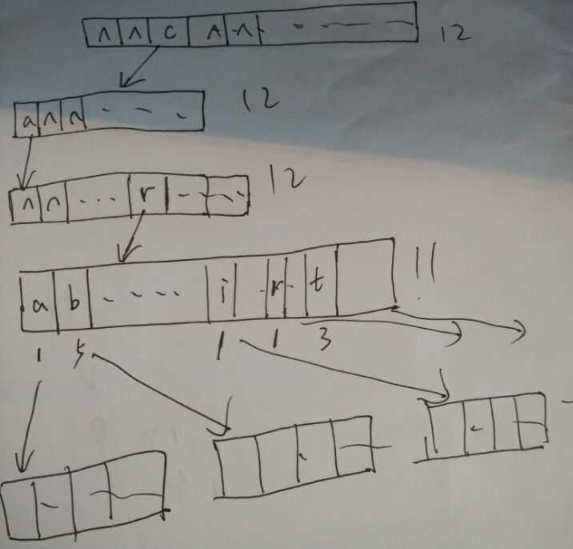
借用字典数,存储单词, 把出现字母的次数记录下来
当 某个字母出现次数为1时,表示从树根到此位置组成的字母串 是能够代表一个单词的
字典树参考学习:
实现及应用:http://www.cnblogs.com/binyue/p/3771040.html
Trie树:应用于统计和排序
http://blog.csdn.net/hguisu/article/details/8131559
| Time Limit: 1000MS | Memory Limit: 30000K | |
| Total Submissions: 16990 | Accepted: 7364 |
A prefix of a string is a substring starting at the beginning of the given string. The prefixes of "carbon" are: "c", "ca", "car", "carb", "carbo", and "carbon". Note that the empty string is not considered a prefix in this problem, but every non-empty string
is considered to be a prefix of itself. In everyday language, we tend to abbreviate words by prefixes. For example, "carbohydrate" is commonly abbreviated by "carb". In this problem, given a set of words, you will find for each word the shortest prefix that
uniquely identifies the word it represents.
In the sample input below, "carbohydrate" can be abbreviated to "carboh", but it cannot be abbreviated to "carbo" (or anything shorter) because there are other words in the list that begin with "carbo".
An exact match will override a prefix match. For example, the prefix "car" matches the given word "car" exactly. Therefore, it is understood without ambiguity that "car" is an abbreviation for "car" , not for "carriage" or any of the other words in the list
that begins with "car".
Input
The input contains at least two, but no more than 1000 lines. Each line contains one word consisting of 1 to 20 lower case letters.
Output
The output contains the same number of lines as the input. Each line of the output contains the word from the corresponding line of the input, followed by one blank space, and the shortest prefix that uniquely (without ambiguity) identifies this word.
Sample Input
carbohydrate cart carburetor caramel caribou carbonic cartilage carbon carriage carton car carbonate
Sample Output
carbohydrate carboh cart cart carburetor carbu caramel cara caribou cari carbonic carboni cartilage carti carbon carbon carriage carr carton carto car car carbonate carbona
Source
ac:
#include<cstdio>
#include<stack>
#include<iostream>
#include <cstring>
#include <string>
#include <vector>
using namespace std;
typedef struct node{
int count;
struct node* next[27];
node(int _count = 0)
{
count = _count;
int i;
for(i = 0 ; i < 27 ; i ++)
{
next[i] = NULL;
}
}
}Trie;
void insertNode(Trie* trie , string s, int len)
{
Trie* t = trie;
int i = 0;
for(i = 0 ;i < len ; i ++)
{
int tmp = s[i]-'a';
if(t->next[tmp] == NULL){
t->next[tmp] = new node(0);
}
t = t->next[tmp]; // 这两个的顺序不能弄错
t->count ++;
}
}
int findrs(Trie *trie, string s, int len)
{
Trie* t = trie;
int i = 0;
for(i = 0 ;i < len ; i ++)
{
int tmp = s[i]-'a';
if(t->next[tmp] == NULL)
return -1;
if(t->next[tmp]->count == 1)
return i + 1 ;
t = t->next[tmp];
}
return len;
}
int main()
{
//freopen("in.txt","r",stdin);
Trie* trie = new node(0);
int i = 0;
vector<string> v;
vector<int> vlen;
string s;
while(getline(cin, s))
{
int len = s.length();
v.push_back(s);
vlen.push_back(len);
insertNode(trie , s, len);
i ++;
}
for(int j = 0 ; j < i ; j ++)
{
string rs = v[j].substr(0,findrs(trie, v[j], vlen[j]));
cout << v[j] << " " << rs << endl;
}
return 0;
}借用字典数,存储单词, 把出现字母的次数记录下来
当 某个字母出现次数为1时,表示从树根到此位置组成的字母串 是能够代表一个单词的
字典树参考学习:
实现及应用:http://www.cnblogs.com/binyue/p/3771040.html
Trie树:应用于统计和排序
http://blog.csdn.net/hguisu/article/details/8131559

相关文章推荐
- java jms
- android 获取屏幕信息
- Mac环境下svn的使用
- Spark之WordCount
- std::set::lower_bound与std::lower_bound的效率问题
- iOS内存管理(5)--深、浅拷贝与copy、strong
- 你具备成为亿万富翁的必要条件吗?
- 最全面的 C++ 资源、框架大全
- java基础集合之TreeSet练习2(带答案)
- Python限制函数运行时间,记录函数运行时间的装饰器
- 添物零基础到大型全栈架构师 Java实战及解析(实战篇)- 概述
- 添物零基础到大型全栈架构师 Java实战及解析(实战篇)- 概述
- 飞思卡尔IMX6处理器的GPIO配置方式
- iOS开发内存管理
- java用JNA调用DLL文件
- Xcode 快捷使用方式
- 腾讯“云+未来”峰会嘉宾解读智慧社区
- Redis之java操作篇(Jedis)
- 男人的深度和品级
- android中使用PopupWindow实现弹出窗口菜单