java爬取百度图片
2016-06-22 23:22
639 查看
公司智能分析部的一位同事遇到难题了,他正阵子做人脸识别,经理给他的图片来源都是外国图片,他想用中国的人脸来作测试,当然最好是中国明星,但是又嫌从百度上一张一张下载比较麻烦,于是找我帮个忙,看看能不能解决。恰巧之前用Java弄过从网络上下载图片,于是我就答应他工作之余一起来想办法。刚开始我用Jsoup来做,后来发现Jsoup获取不到百度图片的地址,因为百度图库的图片是JS异步加载的,网上找了很多资料,竟然发现没有关于下载百度图片的相关实例代码,最后让我庆幸的是原来开源的HtmlUnit可以帮我解决这个问题,让我有种“山重水复疑无路,柳暗花明又一村”的感觉。
下面我就以从百度下载张学友为例进行分析:
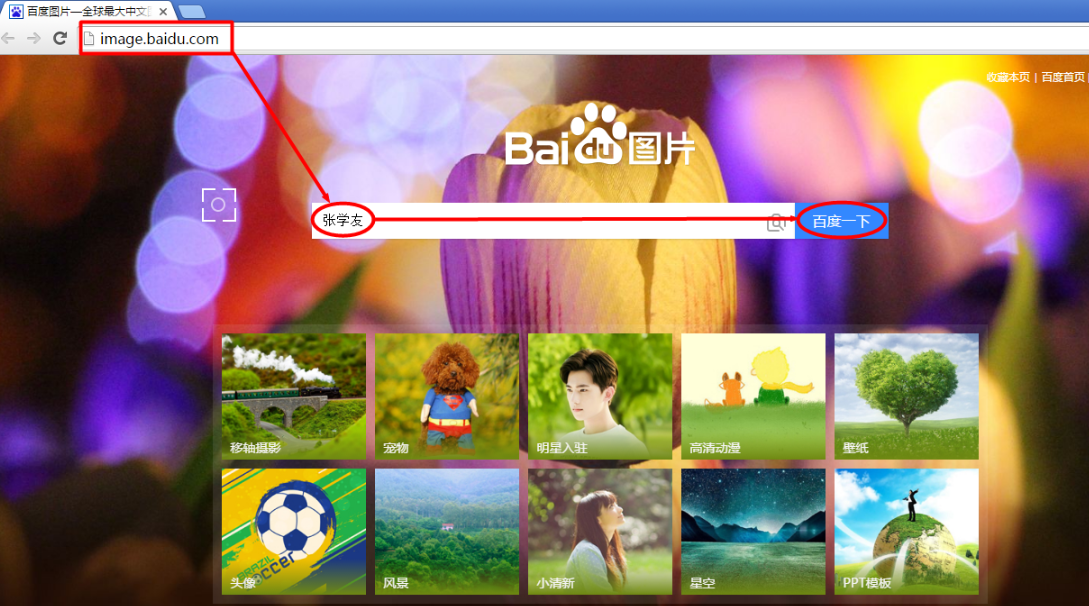
步骤1:打开百度图库(http://image.baidu.com/),在检索框内输入“张学友”,点击“百度一下”。
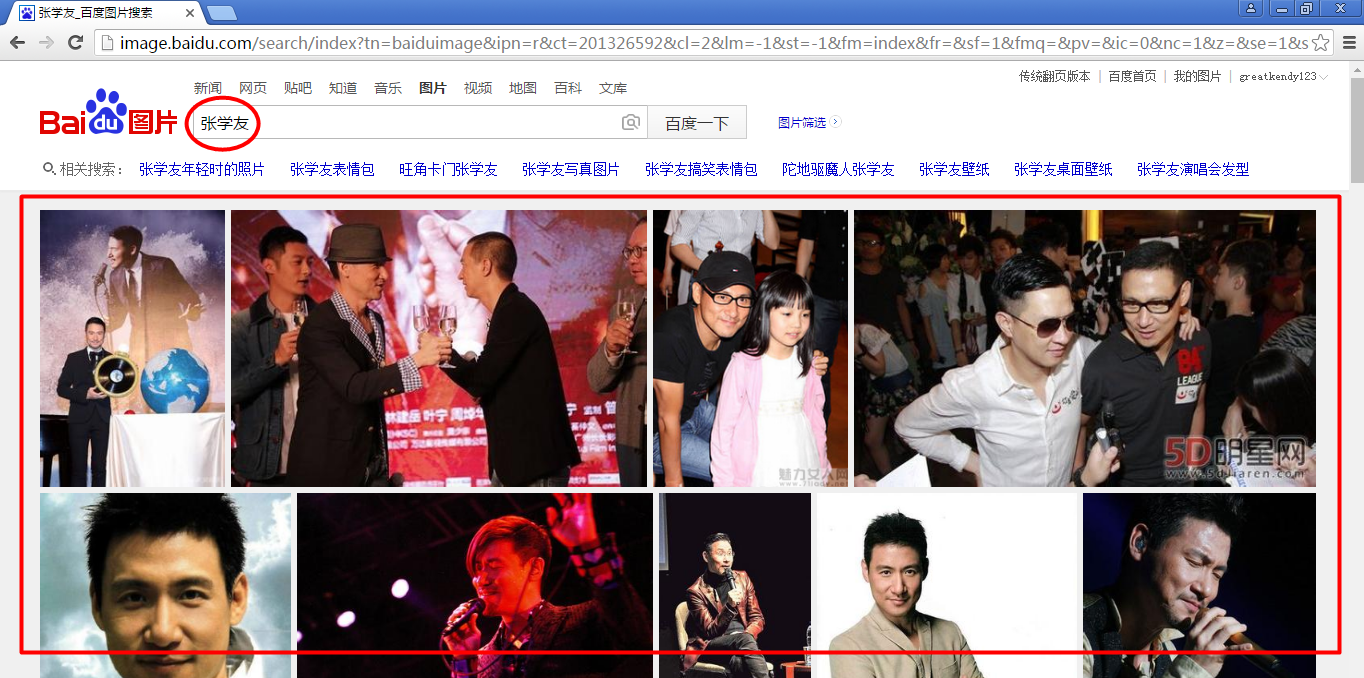
步骤2:看到检索结果,红框区就是我们要下载的图片
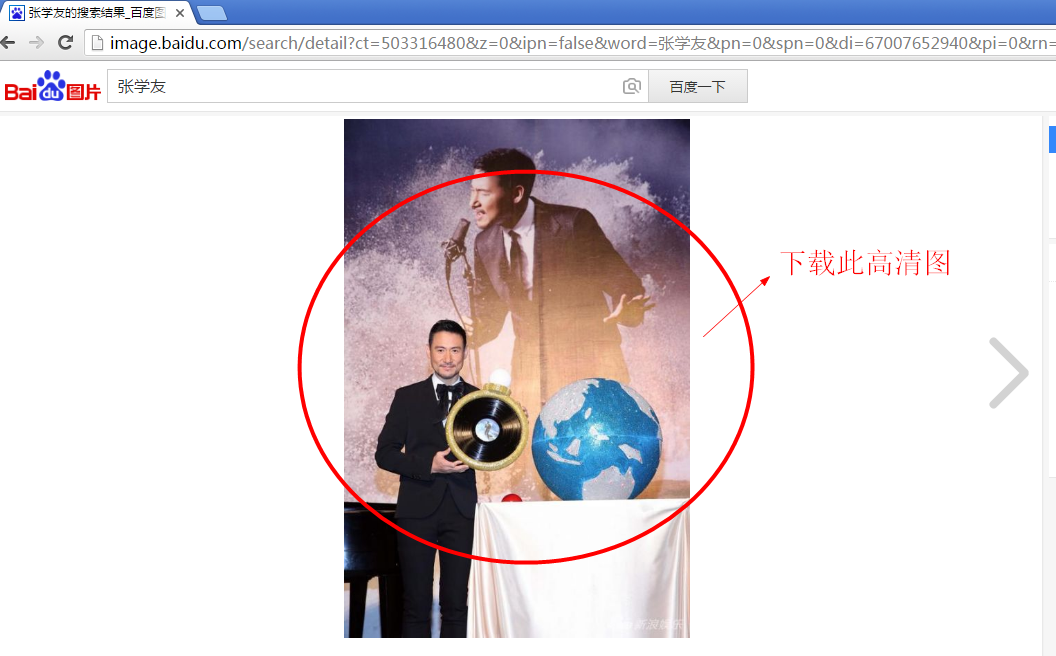
步骤3:点击第一张图片,会看到一个大图,我们通常会右键下载
步骤4:现在我们不妨试着用程序去把拿到这张大图的原地址(最关键)
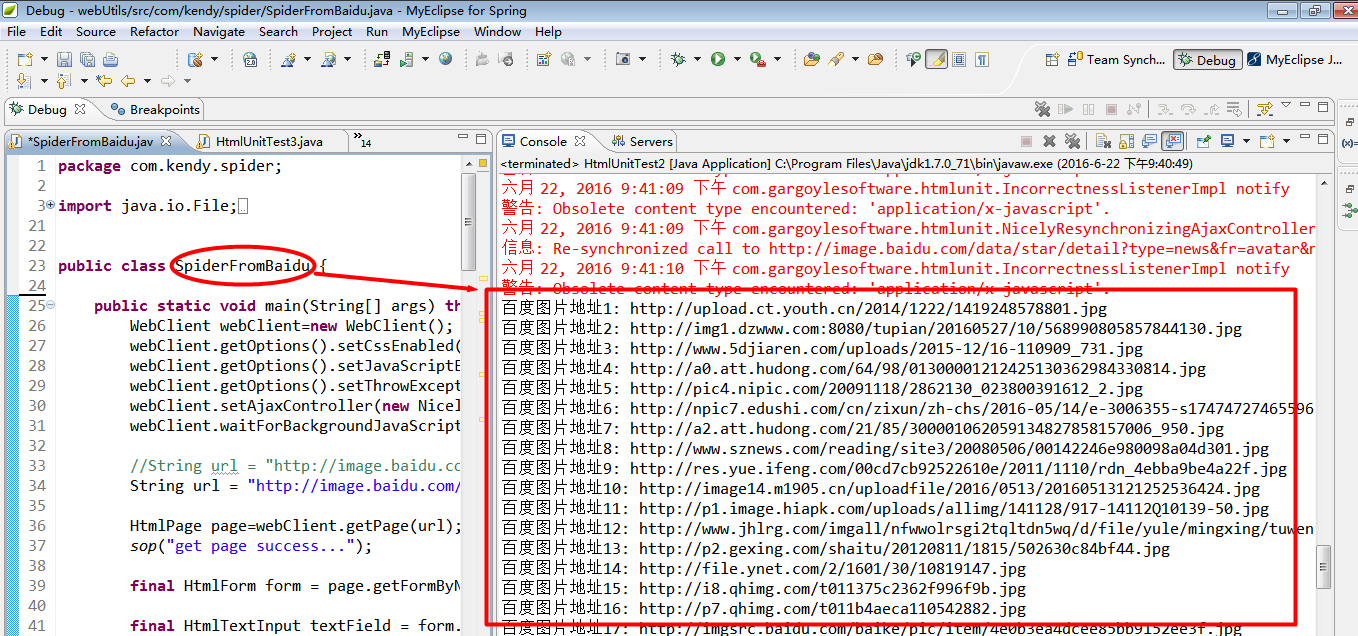
步骤5:根据图片原地址去下载到本地文件夹。
注意:百度图片是根据百度算法去一些网站爬取的,然后Copy一份到百度数据库,经验告诉我,如果去访问百度数据库的图片可能经常会碰到403禁止访问的情况,所以建议各位先获取到图片原网站的地址,根据原图片网络地址去下载。好处有两个,一是保证可以正常下载,二是下载的图片比较高清。
下面我就以从百度下载张学友为例进行分析:
步骤1:打开百度图库(http://image.baidu.com/),在检索框内输入“张学友”,点击“百度一下”。
步骤2:看到检索结果,红框区就是我们要下载的图片
步骤3:点击第一张图片,会看到一个大图,我们通常会右键下载
步骤4:现在我们不妨试着用程序去把拿到这张大图的原地址(最关键)
步骤5:根据图片原地址去下载到本地文件夹。
注意:百度图片是根据百度算法去一些网站爬取的,然后Copy一份到百度数据库,经验告诉我,如果去访问百度数据库的图片可能经常会碰到403禁止访问的情况,所以建议各位先获取到图片原网站的地址,根据原图片网络地址去下载。好处有两个,一是保证可以正常下载,二是下载的图片比较高清。
代码实现:
package com.kendy.spider;
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLConnection;
import java.net.URLDecoder;
import java.util.List;
import com.gargoylesoftware.htmlunit.NicelyResynchronizingAjaxController;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlAnchor;
import com.gargoylesoftware.htmlunit.html.HtmlDivision;
import com.gargoylesoftware.htmlunit.html.HtmlElement;
import com.gargoylesoftware.htmlunit.html.HtmlForm;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.html.HtmlSubmitInput;
import com.gargoylesoftware.htmlunit.html.HtmlTextInput;
public class SpiderFromBaidu {
public static void main(String[] args) throws Exception {
WebClient webClient=new WebClient();
webClient.getOptions().setCssEnabled(true);
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
webClient.waitForBackgroundJavaScript(600*1000);
String url = "http://image.baidu.com/";
HtmlPage page=webClient.getPage(url);
sop("get page success...");
final HtmlForm form = page.getFormByName("f1");
final HtmlTextInput textField = form.getInputByName("word");
textField.setValueAttribute("张学友");
List list = page.getByXPath("//form/span/input[@type=\"submit\"]");
HtmlSubmitInput go = (HtmlSubmitInput)list.get(0);
HtmlPage p =(HtmlPage)go.click();
webClient.waitForBackgroundJavaScript(3*1000);
List imgList = p.getByXPath("//div[@class='list']/div/div[@class='imgshadow']");
HtmlDivision imgDiv = null;
HtmlAnchor link = null;
HtmlElement element = null;
String str=null;
int begin=0;
int end = 0;
int k=1;
for(int i=0;i<imgList.size();i++){
imgDiv =(HtmlDivision)imgList.get(i);
element = (HtmlElement) imgDiv.getLastElementChild().getLastElementChild();
str = element.toString();
if(str.contains("url") && str.contains(".jpg")){
begin = str.indexOf("url")+4;
end = str.indexOf(".jpg")+4;
str = str.substring(begin,end);
str = URLDecoder.decode(str);
download(str,"C:\\Users\\kendy\\DeskTop\\SpiderFromBD\\");
sop("下载成功:");
}else{
str = "";
}
if(!str.equals("")){
sop("百度图片地址"+k+++": "+str);
}
}
}
public static void sop(Object obj){
System.out.println(obj);
}
//根据图片网络地址下载图片
public static void download(String url,String path){
File file= null;
File dirFile=null;
FileOutputStream fos=null;
HttpURLConnection httpCon = null;
URLConnection con = null;
URL urlObj=null;
InputStream in =null;
byte[] size = new byte[1024];
int num=0;
try {
String downloadName= url.substring(url.lastIndexOf("/")+1);
dirFile = new File(path);
if(!dirFile.exists()){
if(dirFile.mkdir()){
if(path.length()>0){
sop("creat document file \""+path.substring(0,path.length()-1)+"\" success...\n");
}
}
}else{
file = new File(path+downloadName);
fos = new FileOutputStream(file);
if(url.startsWith("http")){
urlObj = new URL(url);
con = urlObj.openConnection();
httpCon =(HttpURLConnection) con;
in = httpCon.getInputStream();
while((num=in.read(size)) != -1){
for(int i=0;i<num;i++)
fos.write(size[i]);
}
}
}
} catch (Exception e) {
e.printStackTrace();
} finally{
try {
fos.close();
in.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}

相关文章推荐
- 关于Heritrix学习的问题记录
- 入门级别的Python爬虫代码 爬取百度上的图片
- Python3 百度图片 美女 下载 爬虫 多线程
- Python3 根据关键字爬取百度图片
- 1.python爬取百度图片原图
- scrapy爬取百度图片,解决ajax+json的异步问题
- Python爬虫实现百度图片自动下载
- PHP CURL采集百度搜寻结果图片不显示问题的解决方法
- python实现爬取百度图片的方法示例
- Spring学习(二十五)Spring AOP之增强介绍
- Java之字节流与字符流的区别
- JavaEE实战——XML文档DOM、SAX、STAX解析方式详解
- Spring Data 系列(二) Spring+JPA入门
- 让 SpringMVC 接收多个对象的4种方法
- Java_Serializable
- 使Eclipse下支持编写HTML/JS/CSS/JSP页面的自动提示。
- JAVA之旅(十九)——ListIterator列表迭代器,List的三个子类对象,Vector的枚举,LinkedList,ArrayList和LinkedList的小练习
- JAVA之旅(十九)——ListIterator列表迭代器,List的三个子类对象,Vector的枚举,LinkedList,ArrayList和LinkedList的小练习
- eclipse开发中项目导入有红色感叹号
- 7、JavaBean技术