Torch7深度学习教程
2016-06-22 16:36
363 查看
原文 http://blog.csdn.net/zackzhaoyang/article/details/51417705 https://github.com/soumith/cvpr2015/blob/master/Deep Learning with Torch.ipynb
本文简单介绍了torch做深度学习模型的简单用法,并给出了CIFAR-10的分类例子和代码。
在torch中,模块(Module)是构建神经网络的基石。模块本身也是神经网络,它可以和其他网络借助容器(Container)构建更复杂的神经网络。
我们借助经典的手写体识别(mnist)的例子,如图是个简单的LeNet5前向反馈网络。
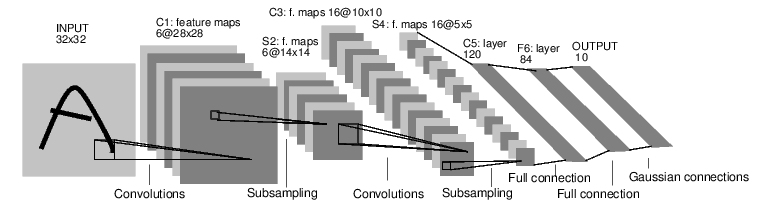
下面一段代码就是上图中网络的定义描述,结合注释应该可以看得比较清楚。
关于反向传输算法这里也不赘述,每个神经元模块都有forward(input)和backward(input,gradient)方法,通过BP传递梯度来更新权重。下面一段代码展示了前向和后向传输的用法:
比如下面代码在torch中建立一个NLL(negative -loglikelihood)的准则:
神经网络层中并不都是可以学习的参数,卷积层根据输入数据和待解决的问题可以学习得到最佳的卷积核大小。但max-pooling层就没有可学习的参数,它只是找到局部最大窗口。
在torch中有可学习的权重都有.weight(可能有.bias)的属性。 比如:
我们用简单的随机梯度下降法(Stochastic Gradient Descent)来更新权值。在nn.StochasticGradient模块中, 里面有个train(dataset)的方法,直接调用就可以了。

我们来总结一下用torch神经网络的几个步骤:
加载数据并对其预处理
定义神经网络模型
定义损失函数
在训练集上训练网络
在测试集上测试网络
下面就按照这5个步骤,实现一个小程序。
数据加载好了,我们还要使得数据满足train(dataset)的要求。
必须要要有size()方法
dataset[i]是其第i个例子(lua是从1开始索引的)。
举个daset格式的例子:
下面要使得我们的数据均值为0标准差为1。
for i=1,3 do -- over each image channel
testset.data[{ {}, {i}, {}, {} }]:add(-mean[i]) -- mean subtraction
testset.data[{ {}, {i}, {}, {} }]:div(stdv[i]) -- std scaling
end
在GPU上用CUDA训练做的改动
如何安装cuda这里就不详说了,网上一堆一堆教程。
包。require ‘cunn’;
网络。net=net:cuda()
标准。criterion = criterion:cuda()
数据。trainset.data = trainset.data:cuda()
trainset.label = trainset.label:cuda()
训练代码倒没什么改变:
因为上面例子的迭代次数较少,结果并不是特别好。自己可以试试。
本文简单介绍了torch做深度学习模型的简单用法,并给出了CIFAR-10的分类例子和代码。
简单概念概述
torch中有神经网络(Neural Networks)的包‘nn’。在torch中,模块(Module)是构建神经网络的基石。模块本身也是神经网络,它可以和其他网络借助容器(Container)构建更复杂的神经网络。
我们借助经典的手写体识别(mnist)的例子,如图是个简单的LeNet5前向反馈网络。
下面一段代码就是上图中网络的定义描述,结合注释应该可以看得比较清楚。
net = nn.Sequential()
net:add(nn.SpatialConvolution(1, 6, 5, 5)) -- 1 input image channel, 6 output channels, 5x5 convolution kernel
net:add(nn.ReLU()) -- non-linearity
net:add(nn.SpatialMaxPooling(2,2,2,2)) -- A max-pooling operation that looks at 2x2 windows and finds the max.
net:add(nn.SpatialConvolution(6, 16, 5, 5))
net:add(nn.ReLU()) -- non-linearity
net:add(nn.SpatialMaxPooling(2,2,2,2))
net:add(nn.View(16*5*5)) -- reshapes from a 3D tensor of 16x5x5 into 1D tensor of 16*5*5
net:add(nn.Linear(16*5*5, 120)) -- fully connected layer (matrix multiplication between input and weights)
net:add(nn.ReLU()) -- non-linearity
net:add(nn.Linear(120, 84))
net:add(nn.ReLU()) -- non-linearity
net:add(nn.Linear(84, 10)) -- 10 is the number of outputs of the network (in this case, 10 digits)
net:add(nn.LogSoftMax()) -- converts the output to a log-probability. Useful for classification problems
print('Lenet5\n' .. net:__tostring());关于反向传输算法这里也不赘述,每个神经元模块都有forward(input)和backward(input,gradient)方法,通过BP传递梯度来更新权重。下面一段代码展示了前向和后向传输的用法:
input=torch.rand(1,32,32) output=net:forward(input) print(output) net:zeroGradParameters() -- zero the internal gradient buffers of the network (will come to this later) gradInput = net:backward(input, torch.rand(10)) print(#gradInput)
损失函数
loss function是调整权重的准则,其重要性不言而喻,loss值越低往往标志着其模型越好(也可能有过拟合的情况,在此不讨论其泛化能力)。我们训练的目标也是为了找到使得损失函数较小的权重。比如下面代码在torch中建立一个NLL(negative -loglikelihood)的准则:
criterion = nn.ClassNLLCriterion() -- a negative log-likelihood criterion for multi-class classification criterion:forward(output, 3) -- let's say the groundtruth was class number: 3 gradients = criterion:backward(output, 3) gradInput = net:backward(input, gradients)
神经网络层中并不都是可以学习的参数,卷积层根据输入数据和待解决的问题可以学习得到最佳的卷积核大小。但max-pooling层就没有可学习的参数,它只是找到局部最大窗口。
在torch中有可学习的权重都有.weight(可能有.bias)的属性。 比如:
m = nn.SpatialConvolution(1,3,2,2) -- learn 3 2x2 kernels print(m.weight) -- initially, the weights are randomly initialized print(m.bias) -- The operation in a convolution layer is: output = convolution(input,weight) + bias如何训练网络
我们用简单的随机梯度下降法(Stochastic Gradient Descent)来更新权值。在nn.StochasticGradient模块中, 里面有个train(dataset)的方法,直接调用就可以了。
输入数据格式
处理图像、文本、音频和视频数据时,可以用image.load或者audio.load把数据保存到torch.Tensor或者Lua table格式的变量中。我们先用一下简单的CIFAR-10数据库来训练我们的模型吧。CIFAR-10是3通道的32*32的彩色图片集。有airplane,automobile,bird,cat,deer,dog,frog,horse,ship,truck共十类。总共有50000训练图片,10000测试图片。我们来总结一下用torch神经网络的几个步骤:
加载数据并对其预处理
定义神经网络模型
定义损失函数
在训练集上训练网络
在测试集上测试网络
下面就按照这5个步骤,实现一个小程序。
加载数据并对其预处理
因为有人已经事先把数据转换成4D的torch ByteTensor形式了。训练集是50000*3*32*32,测试集是10000*3*32*32。require 'paths'
if (not paths.filep("cifar10torchsmall.zip")) then
os.execute('wget -c https://s3.amazonaws.com/torch7/data/cifar10torchsmall.zip') os.execute('unzip cifar10torchsmall.zip')
end
trainset = torch.load('cifar10-train.t7')
testset = torch.load('cifar10-test.t7')
classes = {'airplane', 'automobile', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck'}
print(trainset)
print(#trainset.data)数据加载好了,我们还要使得数据满足train(dataset)的要求。
必须要要有size()方法
dataset[i]是其第i个例子(lua是从1开始索引的)。
举个daset格式的例子:
dataset={};
function dataset:size() return 100 end -- 100 examples
for i=1,dataset:size() do
local input = torch.randn(2); -- normally distributed example in 2d
local output = torch.Tensor(1);
if input[1]*input[2]>0 then -- calculate label for XOR function
output[1] = -1;
else
output[1] = 1
end
dataset[i] = {input, output}
end下面要使得我们的数据均值为0标准差为1。
mean = {} -- store the mean, to normalize the test set in the future
stdv = {} -- store the standard-deviation for the future
for i=1,3 do -- over each image channel
mean[i] = trainset.data[{ {}, {i}, {}, {} }]:mean() -- mean estimation
print('Channel ' .. i .. ', Mean: ' .. mean[i])
trainset.data[{ {}, {i}, {}, {} }]:add(-mean[i]) -- mean subtraction
stdv[i] = trainset.data[{ {}, {i}, {}, {} }]:std() -- std estimation
print('Channel ' .. i .. ', Standard Deviation: ' .. stdv[i])
trainset.data[{ {}, {i}, {}, {} }]:div(stdv[i]) -- std scaling
end定义神经网络模型
net = nn.Sequential() net:add(nn.SpatialConvolution(3, 6, 5, 5)) -- 3 input image channels, 6 output channels, 5x5 convolution kernel net:add(nn.ReLU()) -- non-linearity net:add(nn.SpatialMaxPooling(2,2,2,2)) -- A max-pooling operation that looks at 2x2 windows and finds the max. net:add(nn.SpatialConvolution(6, 16, 5, 5)) net:add(nn.ReLU()) -- non-linearity net:add(nn.SpatialMaxPooling(2,2,2,2)) net:add(nn.View(16*5*5)) -- reshapes from a 3D tensor of 16x5x5 into 1D tensor of 16*5*5 net:add(nn.Linear(16*5*5, 120)) -- fully connected layer (matrix multiplication between input and weights) net:add(nn.ReLU()) -- non-linearity net:add(nn.Linear(120, 84)) net:add(nn.ReLU()) -- non-linearity net:add(nn.Linear(84, 10)) -- 10 is the number of outputs of the network (in this case, 10 digits) net:add(nn.LogSoftMax()) -- converts the output to a log-probability. Useful for classification problems
定义损失函数
criterion = nn.ClassNLLCriterion()
训练网络
trainer = nn.StochasticGradient(net, criterion) trainer.learningRate = 0.001 trainer.maxIteration = 5 -- just do 5 epochs of training. trainer:train(trainset)
测试数据
testset.data = testset.data:double() -- convert from Byte tensor to Double tensorfor i=1,3 do -- over each image channel
testset.data[{ {}, {i}, {}, {} }]:add(-mean[i]) -- mean subtraction
testset.data[{ {}, {i}, {}, {} }]:div(stdv[i]) -- std scaling
end
在GPU上用CUDA训练做的改动
如何安装cuda这里就不详说了,网上一堆一堆教程。包。require ‘cunn’;
网络。net=net:cuda()
标准。criterion = criterion:cuda()
数据。trainset.data = trainset.data:cuda()
trainset.label = trainset.label:cuda()
训练代码倒没什么改变:
trainer = nn.StochasticGradient(net, criterion) trainer.learningRate = 0.001 trainer.maxIteration = 5 -- just do 5 epochs of training.
因为上面例子的迭代次数较少,结果并不是特别好。自己可以试试。

相关文章推荐
- CUDA搭建
- 稀疏自动编码器 (Sparse Autoencoder)
- 白化(Whitening):PCA vs. ZCA
- softmax回归
- 卷积神经网络初探
- TensorFlow人工智能引擎入门教程之九 RNN/LSTM循环神经网络长短期记忆网络使用
- TensorFlow人工智能引擎入门教程之十 最强网络 RSNN深度残差网络 平均准确率96-99%
- TensorFlow人工智能入门教程之十一 最强网络DLSTM 双向长短期记忆网络(阿里小AI实现)
- TensorFlow人工智能入门教程之十四 自动编码机AutoEncoder 网络
- TensorFlow人工智能引擎入门教程所有目录
- 如何用70行代码实现深度神经网络算法
- 近200篇机器学习&深度学习资料分享(含各种文档,视频,源码等)
- 安装caffe过程记录
- DIGITS的安装与使用记录
- 图像识别和图像搜索
- 卷积神经网络
- 深度学习札记
- ubuntu14.04安装 资料
- ImageNet classification with deep convolutional neural network
- 智慧石文章分享