Bagging
2016-06-21 11:25
435 查看
同一个学习算法在来自同一分布的多个不同的训练数据集上训练得到的模型偏差可能较大,即模型的方差(variance)较大,为了解决这个问题,可以综合多个模型的输出结果,对于回归问题可以取平均值,对于分类问题可以采取多数投票的方法。这就是Bagging的核心思想。
Bagging(Bootstrap Aggregation)是常用的统计学习方法,其综合的基本学习器可以是各种弱学习器。
有放回的随机采样,同cross-validation一样,是一种resample技术。示例如下:
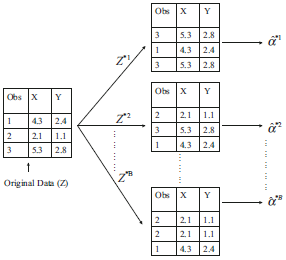
采用这样的方式解决了获取N个服从同一分布的原始数据集不现实的问题,而且在可接受程度上,可以认为Bootstrap 采样方式不影响到模型的准确性(以方差来衡量),即可以等价于使用N个不同的原始数据集,详见参考文献3中Bootstrap Sample部分。
然而有研究表明,有放回的随机采样,其实对模型的性能来说不是至关重要的,也可以用无放回的随机采样来取代。
- 平均,目的是降低方差。Z1,Z2,…,Zn的方差为σ2,Z¯¯¯的方差是σ2/n.采用Bagging策略明显减低模型方差(variance),如下图所示。
- Bootstrap采样。为了实现上述平均操作,我们需要多个训练数据集来训练模型,而在应用中找N个不同的训练集合不现实,所以对同一个训练集使用有放回的bootstrap采样获取N个训练集
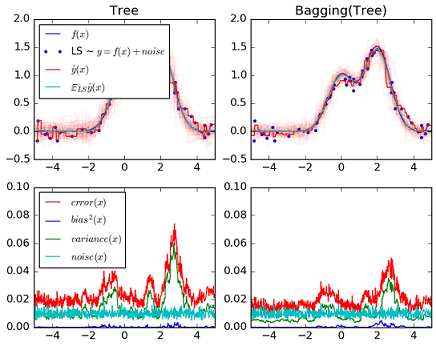
Bagging较单棵决策树来说,降低了方差,但由于将多棵决策树的结果进行了平均,这损失了模型的可解释性。
2.Maindonald J. Statistical Learning from a Regression Perspective[J]. Journal of Statistical Software, 2009, 29(1): 1-4.
3.Huang J Z. An Introduction to Statistical Learning: With Applications in R By Gareth James, Trevor Hastie, Robert Tibshirani, Daniela Witten[J]. Journal of Agricultural Biological and Environmental Statistics, 2014, 19(4): 556-557.
Bagging(Bootstrap Aggregation)是常用的统计学习方法,其综合的基本学习器可以是各种弱学习器。
Bootstrap Sample
要想综合N个弱分类器(决策树)的结果,我们需要采样N个训练数据集,在实际应用中获取N个训练数据集往往不现实,BootStrap 采样提供了一种有效的解决方法。有放回的随机采样,同cross-validation一样,是一种resample技术。示例如下:
采用这样的方式解决了获取N个服从同一分布的原始数据集不现实的问题,而且在可接受程度上,可以认为Bootstrap 采样方式不影响到模型的准确性(以方差来衡量),即可以等价于使用N个不同的原始数据集,详见参考文献3中Bootstrap Sample部分。
然而有研究表明,有放回的随机采样,其实对模型的性能来说不是至关重要的,也可以用无放回的随机采样来取代。
Bagging算法
将训练数据集进行N次Bootstrap采样得到N个训练数据子集,对每个子集使用相同的算法分别建立决策树,最终的分类(或回归)结果是N个决策树的结果的多数投票(或平均)。两个主要步骤
上述Bagging算法涉及两个主要步骤- 平均,目的是降低方差。Z1,Z2,…,Zn的方差为σ2,Z¯¯¯的方差是σ2/n.采用Bagging策略明显减低模型方差(variance),如下图所示。
- Bootstrap采样。为了实现上述平均操作,我们需要多个训练数据集来训练模型,而在应用中找N个不同的训练集合不现实,所以对同一个训练集使用有放回的bootstrap采样获取N个训练集
Bagging较单棵决策树来说,降低了方差,但由于将多棵决策树的结果进行了平均,这损失了模型的可解释性。
特征重要性
对于回归(或分类)树,可以利用每个特征使树的RSS(或Gini 指数)平均降低的量来度量特征的重要性。参考
1.http://scikit-learn.org/stable/auto_examples/ensemble/plot_bias_variance.html#id22.Maindonald J. Statistical Learning from a Regression Perspective[J]. Journal of Statistical Software, 2009, 29(1): 1-4.
3.Huang J Z. An Introduction to Statistical Learning: With Applications in R By Gareth James, Trevor Hastie, Robert Tibshirani, Daniela Witten[J]. Journal of Agricultural Biological and Environmental Statistics, 2014, 19(4): 556-557.

相关文章推荐
- bootstrap初试进度条
- Bootstrap 3.3.4 发布,Web 前端 UI 框架
- angular 指令简述
- 基于BootStrap Metronic开发框架经验小结【六】对话框及提示框的处理和优化
- Bootstrap教程JS插件弹出框学习笔记分享
- Bootstrap框架动态生成Web页面文章内目录的方法
- JS组件Bootstrap Table使用实例分享
- Bootstrap表单组件教程详解
- Bootstrap每天必学之前端开发框架
- Bootstrap 粘页脚效果
- bootstrap-wysiwyg结合ajax实现图片上传实时刷新功能
- JS组件中bootstrap multiselect两大组件较量
- Bootstrap模仿起筷首页效果
- 基于Bootstrap的网页设计实例
- Bootstrap表格和栅格分页实例详解
- 基于BootStrap Metronic开发框架经验小结【四】Bootstrap图标的提取和利用
- BootStrap实用代码片段之一
- JS组件Bootstrap dropdown组件扩展hover事件
- BootStrap智能表单实战系列(三)分块表单配置详解
- Bootstrap Paginator分页插件使用方法详解