solr的分词器
2016-06-21 00:00
351 查看
摘要: solr的分词器
配置:
浏览器页面

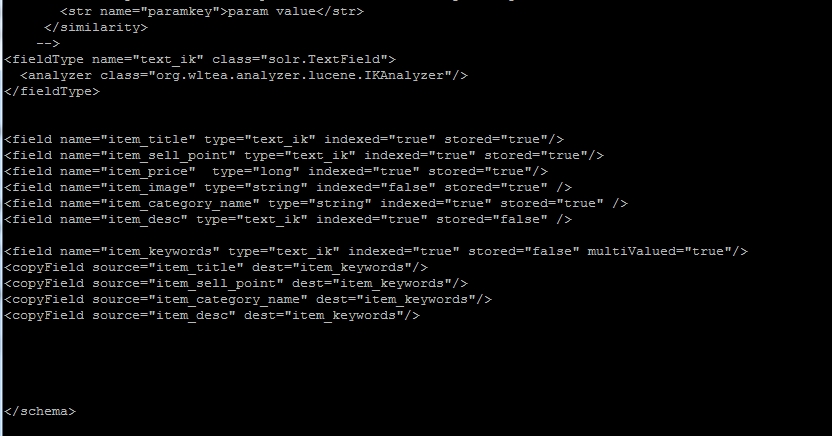
[code=language-java]1.将IKAnalyzer2012FF_u1.jar包拷贝到 /usr/local/devTools/solr/apache-tomcat-7.0.47/webapps/solr/WEB-INF/lib文件夹下面 2.将IKAnalyzer.cfg.xml,ext_stopword.dic,mydict.dic拷贝到/usr/local/devTools/solr/apache-tomcat-7.0.47/webapps/solr/WEB-INF/classes,classpath下面 注意扩展词典,和停用词词典必须是UTF-8 3.配置filedType,在solrhome/collection1/conf/schema.xml末尾中配置如下信息 <fieldType name="text_ik" class="solr.TextField"> <analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType> 4.配置业务字段, 业务字段判断标准, 1.该字段是否在搜索时是否需要在字段上收索, 2.后续操作是否需要用到该字段 用到的字段 商品id,商品title,商品买点,价格,商品img,商品分类名称,商品描述 1.id===>商品id ... ... 在solrhome/collection1/conf/schema.xml文件末尾配置如下 <field name="item_title" type="text_ik" indexed="true" stored="true"/> <field name="item_sell_point" type="text_ik" indexed="true" stored="true"/> <field name="item_price" type="long" indexed="true" stored="true"/> <field name="item_image" type="string" indexed="false" stored="true" /> <field name="item_category_name" type="string" indexed="true" stored="true" /> <field name="item_desc" type="text_ik" indexed="true" stored="false" /> <field name="item_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/> <copyField source="item_title" dest="item_keywords"/> <copyField source="item_sell_point" dest="item_keywords"/> <copyField source="item_category_name" dest="item_keywords"/> <copyField source="item_desc" dest="item_keywords"/> item_keywords:搜索域 5.从新启动tomcat
配置:
浏览器页面

相关文章推荐
- postfix邮箱服务器安装和配置
- Visual Studio找不到adb.exe错误解决
- linux unzip 乱码
- 2015年12月最新苹果开发者企业账号注册流程图解
- 闪迪(SanDisk)U盘防伪查询(官方网站)
- Ant远程部署到Tomcat
- 如何选择 class有空格的元素
- Jquery 相关
- postgresql 登录使用GSS方式验证的实现原理分析
- linux c的线程池
- Android 混淆 ProGuard
- Android SeekBar的使用(待续)
- 1、直接插入排序(Straight Insertion Sort)
- 项目打包去掉调试时的NSLog、print
- swift项目中极光推送
- 使用英文网站模板建站,修改为中文时不显示的解决方法。
- 考研复习第6弹
- 静态工厂方法的优缺点分析
- Linux配置文件路径大全
- 软件工程 结对项目总结