k-means聚类算法
2016-06-20 14:09
363 查看
算法简介
K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。基本思想
首先确定聚类的类别数K,并任意选择待聚类的数据中k个数据作为初始聚类中心(初始化方法: Forgy),然后计算所有数据点到初始聚类中心的距离,把各个数据点分配到离它最近的聚类中心,形成簇,最后求出各个簇的数学平均作为新的聚类中心,重复上述步骤直到误差函数取最小,使得聚类中心不再变化为止。具体步骤
从所有样本中随机选取k个样本,作为初始聚类中心;对任意一样本,求其到k个中心的欧式距离,将该样本归到距离最短的中心所在的类;
利用均值方法更新各类中心;
迭代2,3步直到聚类中心值小于指定的阈值(保持不变)或达到最大迭代次数,算法结束。
Matlab代码实现
clear all;
close all;
clc;
str1 = {'聚类中心数:','最大迭代次数:'};
T = inputdlg(str1,'输入对话框 ');
K = str2double(T{1,1});
ite = str2double(T{2,1});
%鼠标随机取点
grid on;
axis([0 50 0 50]);
hold on
N = zeros(20000,2);%存储样本
L = 0;%存储样本个数
buttle = 1;
while buttle == 1
[x,y,buttle] = ginput(1);
plot(x,y,'mo');
L = L+1;
N(L,:) = [x,y];
end
%从样本中随机选择k个样本点,作为初始聚类中心
R = randperm(L);%将1至L随机数打乱
k = zeros(K,2);
for i = 1:K
k(i,:) = N(R(i),:);
end
disp( '初始聚类中心为:');
disp( num2str(k));
%开始迭代
for D = 1:ite
%求样本到每个聚类中心的距离
d = zeros(L,K);
for i = 1:L
for j = 1:K
d(i,j) = norm(N(i,:) - k(j,:))2;%欧氏距离
end
end
%按最短距离归类
dn = zeros(L,1);
for i = 1:L
[m ,n] = min(d(i,:));%m为最短距离,n为所在位置
dn(i,1) = n;%归类
end
%设置颜色
colour = zeros(K,3);
for i = 1:K
colour(i,:) = rand(1,3);
end
%利用均值法更新各类中心
k1 = zeros(K,2);
for i = 1:K
v = find(dn == i);%位置
u = length(v);%个数
M = zeros(u,2);%用来存储所属同一类的点
for j = 1:u
M(j,:) = N(v(j),:);
end
P = plot(M(:,1),M(:,2),'o');
set(P,'color',colour(i,:));
k1(i,:) = mean(M);
end
clear P;
if abs(sum(sum(k1-k))) <= 0.0001 && D <= ite
disp( '聚类中心数为:');
disp( num2str(K));
disp( '最终的聚类中心为:');
disp( num2str(k1));
break
else
k = k1;
end
end
%显示距离中心
for i = 1:K
plot(k1(i,1),k1(i,2),'kp ');
end结果
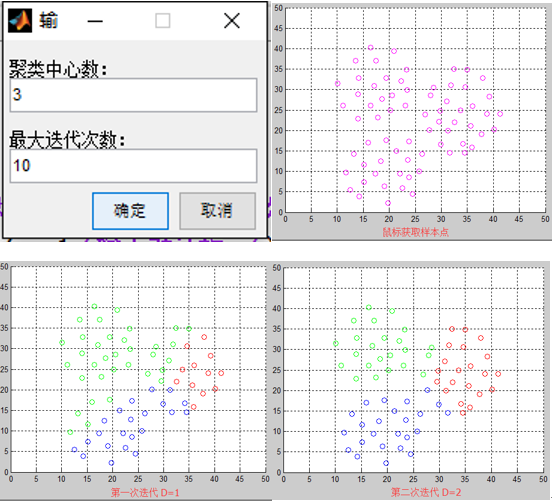


相关文章推荐
- 书评:《算法之美( Algorithms to Live By )》
- 动易2006序列号破解算法公布
- C#递归算法之分而治之策略
- Ruby实现的矩阵连乘算法
- C#插入法排序算法实例分析
- C#算法之大牛生小牛的问题高效解决方法
- C#算法函数:获取一个字符串中的最大长度的数字
- 超大数据量存储常用数据库分表分库算法总结
- C#数据结构与算法揭秘二
- C#冒泡法排序算法实例分析
- 算法练习之从String.indexOf的模拟实现开始
- C#算法之关于大牛生小牛的问题
- C#实现的算24点游戏算法实例分析
- 经典排序算法之冒泡排序(Bubble sort)代码
- c语言实现的带通配符匹配算法
- 浅析STL中的常用算法
- 算法之排列算法与组合算法详解
- C++实现一维向量旋转算法
- Ruby实现的合并排序算法
- C#折半插入排序算法实现方法