外排序
2016-06-19 13:41
1326 查看
外排序
2013-09-15 21:57 2448人阅读 评论(0) 收藏 举报分类:
算法(604)
数据结构(202)
目录(?)[+]
外排序[编辑]
4、最佳归并树:如果在进行多路归并的时候,各初始顺串的长度不同,对外存扫描的次数,即执行时间会产生影响。把所有初始顺串的块数作为树的叶结点的权值,如果是K路归并则建立起一棵K-叉Huffman树。这样的一棵Huffman树就是最佳归并树。通过最佳归并树进行多路归并可以使对外存的I/O降到最少,提高归并执行效率。外排序(External sorting)是指能够处理极大量数据的排序算法。通常来说,外排序处理的数据不能一次装入内存,只能放在读写较慢的外存储器(通常是硬盘)上。外排序通常采用的是一种“排序-归并”的策略。在排序阶段,先读入能放在内存中的数据量,将其排序输出到一个临时文件,依此进行,将待排序数据组织为多个有序的临时文件。尔后在归并阶段将这些临时文件组合为一个大的有序文件,也即排序结果。
目录
[隐藏] 1 外归并排序
1.1 附加的步骤
1.2 优化性能
2 其他算法
3 外部链接
4 参考
外归并排序[编辑]
外排序的一个例子是外归并排序(External merge sort),它读入一些能放在内存内的数据量,在内存中排序后输出为一个顺串(即是内部数据有序的临时文件),处理完所有的数据后再进行归并。[1][2]比如,要对900 MB 的数据进行排序,但机器上只有 100 MB 的可用内存时,外归并排序按如下方法操作:
读入 100 MB 的数据至内存中,用某种常规方式(如快速排序、堆排序、归并排序等方法)在内存中完成排序。
将排序完成的数据写入磁盘。
重复步骤 1 和 2 直到所有的数据都存入了不同的 100 MB 的块(临时文件)中。在这个例子中,有 900 MB 数据,单个临时文件大小为 100 MB,所以会产生 9 个临时文件。
读入每个临时文件(顺串)的前 10 MB ( = 100 MB / (9 块 + 1))的数据放入内存中的输入缓冲区,最后的
10 MB 作为输出缓冲区。(实践中,将输入缓冲适当调小,而适当增大输出缓冲区能获得更好的效果。)
执行九路归并算法,将结果输出到输出缓冲区。一旦输出缓冲区满,将缓冲区中的数据写出至目标文件,清空缓冲区。一旦9个输入缓冲区中的一个变空,就从这个缓冲区关联的文件,读入下一个10M数据,除非这个文件已读完。这是“外归并排序”能在主存外完成排序的关键步骤
-- 因为“归并算法”(merge algorithm)对每一个大块只是顺序地做一轮访问(进行归并),每个大块不用完全载入主存。
为了增加每一个有序的临时文件的长度,可以采用置换选择排序(Replacement
selection sorting)。它可以产生大于内存大小的顺串。具体方法是在内存中使用一个最小堆进行排序,设该最小堆的大小为
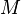
。算法描述如下:
初始时将输入文件读入内存,建立最小堆。
将堆顶元素输出至输出缓冲区。然后读入下一个记录:
若该元素的关键码值不小于刚输出的关键码值,将其作为堆顶元素并调整堆,使之满足堆的性质;
否则将新元素放入堆底位置,将堆的大小减 1。
重复第 2 步,直至堆大小变为 0。
此时一个顺串已经产生。将堆中的所有元素建堆,开始生成下一个顺串。[3]
此方法能生成平均长度为

的顺串,可以进一步减少访问外部存储器的次数,节约时间,提高算法效率。
附加的步骤[编辑]
上述例子的外排序有两个步骤:排序和归并。我们用一次多路归并就完成了所有临时文件的归并,而并非按内存中的二路归并那样,一次归并两个子串,耗费
次归并。外排序中不适用上述方法的原因在于每次读写都需要对硬盘进行读写,而这时非常缓慢的。所以应该尽可能减小磁盘的读写次数。
不过,在上述方法中也存在权衡。当临时文件(顺串)的数量继续增大时,归并时每次可从顺串中读入的数据减少了。比如说,50 GB 的数据量,100 MB 的可用内存,这种情况下用一趟多路归并就显得不划算。读入很多的顺串花费的时间占据了排序时间的大部分。这时,我们可以用多次(比如两次)归并来解决这个问题。
这时排序算法变为下述这样:
第一步不变。
将小的顺串合并为大一些的顺串,适当减小顺串的数目。
将剩余的大一些的顺串归并为最终结果。
和内排序一样,高效的外排序所耗的时间依然是

。若利用好现在计算机上
GB 的内存,可使时间复杂度中的对数项增长比较缓慢。
优化性能[编辑]
计算机科学家吉姆·格雷的 SortBenchmark 网站用不同的硬件、软件环境测试了实现方法不同的多种外排序算法的效率。效率较高的算法具有以下的特征:
并行计算
用多个磁盘驱动器并行处理数据,可以加速顺序磁盘读写。[4]
在计算机上使用多线程,可在多核心的计算机上得到优化。
使用异步输入输出,可以同时排序和归并,同时读写。
使用多台计算机用高速网络连接,分担计算任务。[5]
提高硬件速度
增大内存,减小磁盘读写次数,减小归并次数。
使用快速的外存设备,比如 15000 RPM 的硬盘或固态硬盘。
使用性能更优良个各种设备,比如使用多核心 CPU 和延迟时间更短的内存。
提高软件速度
对于某些特殊数据,在第一阶段的排序中使用基数排序。
压缩输入输出文件和临时文件。
其他算法[编辑]
外归并排序法并不是唯一的外排序算法。另外还有外分配排序,其原理类似于内排序中的桶排序。在归并排序和桶排序之间存在数学上的某种对偶性。[6] 此外还有一些不耗费附加磁盘空间的原地排序算法。
外部链接[编辑]
STXXL, 一个包含外归并排序的代码包外归并排序示例
多路归并实现
Java 语言外归并排序
参考[编辑]
^ DonaldKnuth, The Art of Computer Programming, Volume 3: Sorting and Searching, Second Edition. Addison-Wesley, 1998,ISBN
0-201-89685-0, Section 5.4: External Sorting, pp.248–379.
^ * Ellis
Horowitz and Sartaj Sahni, Fundamentals
of Data Structures, H. Freeman & Co., ISBN
0-7167-8042-9.
^ 张铭、王腾蛟、赵海燕.
数据结构与算法. 北京: 高等教育出版社. 2008: pp.246–248. ISBN 978-7-04-023961-4.
^ Nikolas
Askitis, OzSort 2.0: Sorting up to 252GB for a Penny
^ Rasmussen
et al., TritonSort
^ J.
S. Vitter, Algorithms and Data Structures for
External Memory, Series on Foundations and Trends in Theoretical Computer Science, now Publishers, Hanover, MA, 2008, ISBN
978-1-60198-106-6.
置换-选择排序
(2012-09-26
18:45:13)
转载▼
标签:
|
(其中k为归并路数,n为归并段的个数)。增加k和减小n都可以达到减小归并趟数的目的。置换-选择排序就是一种减小n的、在外部排序中创建初始归并段时用到的算法。它可以让初始归并段的长度增减,从而减小初始归并段的段数(因为总的记录数是一定的)。
置换-选择排序是在树形选择排序的基础上得来的,它的特点是:在整个排序(得到初始归并段)的过程中,选择最小(或最大)关键值和输入、输出交叉或并行进行。它的主要思路是:用败者树从已经传递到内存中的记录中找到关键值最小(或最大)的记录,然后将此记录写入外存,再将外存中一个没有排序过的记录传递到内存(因为之前那个记录写入外存后已经给它空出内存),然后再用败者树的一次调整过程找到最小关键值记录(这个调整过程中需要注意:比已经写入本初始归并段的记录关键值小的记录不能参见筛选,它要等到本初始段结束,下一个初始段中才可以进行筛选),再将此最小关键值记录调出,再调入新的记录.......依此进行指导所有记录已经排序过。内存中的记录就是所用败者树的叶子节点。
假设初始待排序文件为FI,初始归并段文件为输出文件FO,内存工作区为WA,FO与WA的初始状态为空,并假设内存工作去WA的容量可容纳w个记录,则置换-选择排序的操作的过程为:
(1)、从FI输入w个记录到工作区WA。
(2)、从WA中选出其中关键字最小的记录,记为MINIMAX记录。
(3)、将MINIMAX记录输出到FO中去。
(4)、若FI不为空,则从FI输入下一个记录到WA中。
(5)、从WA中所有关键字比MINIMAX记录关键字大的记录中选出最小关键字记录,作为新的MINIMAX记录。
(6)、重复(3)~(5),直至WA中选不出新的MINIMAX记录为止,由此得到一个初始归并段,输出一个归并段的结束标记到FO中去。
(7)、重复(2)~(6),直至WA为空。由此得到全部归并段。
在WA中选择MINIMAX记录的过程利用“败者树”来实现。就置换-排序中败者树的实现细节这里加以说明。(1)、内存空间中的记录做为败者树的外部节点,而败者树中根节点的双亲节点指示工作区中关键字最小的记录。(2)、为了便于选择MINIMAX记录,为每个记录附设一个所在归并段的序号,在进行关键字的比较时,先比较段号,段号小的为胜者;段号相同的则关键字小的为胜者;(3)、败者树的建立可以从设工作区中所有记录的段号为0开始,让后从FI逐个输入w个记录到工作区时,自下而上调整败者树,由于这些记录的段号为1,则他们对于0段的记录来说均为败者,从而逐个填充到败者树的各节点中去。
下面是几个置换排序中用到的函数(伪代码):
typedef struct
{
RcdType rec; //记录
KetType key; //从记录中抽取的关键字
int rnum; //所属归并段的段号
}RcNode,WorkArea[w]; //内存工作区,容量为w
typedef int LoserTree[w];
//在败者树ls和内存工作区wa上用置换-选择排序求初始归并段,fi为输入文件指针,fo为输出文件指针,
//两个文件均已打开
void Replace_Selection(LoserTree &ls,WorkArea &wa,FILE* fi,FILE* fo)
{
Construct_loser(ls,wa); //初建败者树
rc=rmax=1; //rc指示当前生成的初始归并段的段号,rmax指示wa中关键字所属归初始归并段的最大
//段号,在此过程中,rmax比rc最多大1
while(rc<=rmax) //rc=rmax+1标志着输入文件的置换-选择排序已经完成
{
get_run(ls,wa); //求得一个初始归并段
fwrite(&RUNEND_SYMBOL,sizeof(struct RcdType),1,fo);//将段结束标记写入输出文件
rc=wa[ls[0]].rnum;
}
}
//求得一个初始归并段,fi为输入文件指针,fo为输出文件指针
void get_run(LoserTree &ls,WorkArea &wa)
{
while(wa[ls[0]].rnum==rc)
{
q=ls[0];//选得的MINIMAX记录属当前段时,q指示MINIMAX记录在wa中的记录
minimax=wa[q].key;
fwrite(&wa[q].rec,sizeof(RcdType),1,fo);
if(feof(fi)) //若输入文件结束,虚设记录(属rmax+1段)
{
wa[q].rnum=rmax+1;
wa[q].key=MAXKEY;
}
else
{
fread(&wa[q].rec,sizeof(RcdType),1,fi);
wa[q].key=wa[q].rec.key; //提取关键字
if(wa[q].key<minimax) //新读入的记录属于下一段
{
rmax=rc+1;
wa[q].rnum=rmax;
}
else //新都如的记录属于当前段
wa[q].rnum=rc;
}
Select_MiniMax(ls,wa,q); //选择新的MINIMAX记录
}
}
//从wa[q]起到败者树的根比较选择MINIMAX记录,并有q指示它所在的归并段
void Select_MiniMax(LoserTree &ls,WorkArea wa,int q)
{
for(t=(w+q)/2,p=ls[t];t>0;t=t/2,p=ls[t])
if(wa[p].rnum<wa[q].rnum||wa[p].rnum==wa[q].rnum&&wa[p].key<wa[q].key)
{
int temp=ls[t];
ls[t]=q;
q=temp; //q指示新的胜利者
}
ls[0]=q;
}
//输入w个记录到内存工作区wa,建得败者树ls,选出关键字最小的记录并由s指示器在wa中的位置
void Construct_Loser(LoserTree &ls,WorkArea &wa)
{
for(i=0;i<w;++i)
wa[i].rnum=wa[i].key=ls[i]=0; //工作区初始化
for(i=w-1;i>=0;--i)
{
fread(&wa[i].rec,sizeof(RcdType),1,fi); //输入一个记录
wa[i].key=wa[i].rec.key; //提取关键字
wa[i].rnum=1; //其段号为1
Select_MiniMax(ls,wa,i); //调整败者
}
}
第十一章 外部排序
一、内容提要
1、外部排序指待排序文件较大,内存一次存放不下,尚需存放在外部介质的文件的排序。
2、为减少平衡归并中外存读写次数所采取的方法:增大归并路数和减少归并段个数。
3、利用败者树增大归并路数。
4、利用置换—选择排序增大归并段长度来减少归并段个数。
5、由长度不等的归并段,进行多路平衡归并,需要构造最佳归并树。
6、磁带的多步归并排序。
二、学习要点
1、熟悉外部排序的两个阶段,归并过程。
2、掌握外部排序过程中进行外存读/写次数的计算方法。
3、“胜者树”增大归并路数不能减少外存读写次数,”败者树”可以胜任。掌握败者树建立及归并算法。
4、 熟悉置换—选择排序的过程,理解它能得到平均长度为工作区两倍的初始归并段的道理。
5、 熟练掌握最佳归并树的构造方法,及该过程中对外存读/写次数的计算方法。
6、 了解磁带多步归并的特点,熟悉归并过程及设置虚假的方法,及归并过程所需外存读/写次数的计算方法。
三、习题解析
1.“败者树“中“败者“者指的是什么?若利用败者树求k的个数中的最大者,若在比较中有a>b,谁是败者。
【解答】
所谓”败者树”,就是在比赛(选择)树中,每个双亲结点存放两个子女结点中的”败者”,而让“胜者”参加高一层的比赛。在根结点之上,再加一个结点O,表示全局比赛获胜者。
这里用败者树求k个数中最大者,若a>b, a 是胜者,b小则是败者。
2.”败者树”与“堆”有何区别。
【解答】”败者树”是由参加比赛的n个元素作叶子结点所形成的完全二叉树。而”堆”则是n个元素的序列,且具有如下性质:
Ki<=K2i 或: Ki>=K2i
且 Ki<=K2i+1 且 Ki>=K2i+1 (0<=i<=n DIV 2)
由于堆的这个性质中,下标i与2i及2i+1的关系,恰与完全二叉树第i个结点和它的子树结点序号关系完全一致,故堆可看成是含n个结点的完全二叉树。
3.设有12个归并段,其长度分别为30,44,8,6,3,20,60,18,9,62,68,85。现欲作4路外部归并排序,试华出表示归并过程的最佳归并树,并计算WPL。
【解答】
因(12-1)MOD (4-1)=2,所以的第一次归并路数为2+1=3路,所以最佳归并树如下: ____________(
413) __________
╱ ╱ ╲ ╲
______(64) _____ (68) (85) ______(196)_____
╱ ╱ ╲ ╲ ╱ ╱ ╲ ╲
(9 ) (17) (18) ( 20) (30) (44) ( 60) (62)
╱ | ╲
(3) (6) (8)
WPL=(3+6+8)*3+(9+18+20+30+44+60+62)*2+(68+85)*1
=51+243*2+153*1
=690
最优归并模式——自己实现的霍夫曼树
分类: 算法与数据结构2011-01-1221:10 252人阅读 评论(0) 收藏 举报
nullclassinclude
[cpp] view
plaincopy
#include "stdafx.h"
#include<iostream>
#include<queue>
#include <cassert>
#include<functional>
using namespace std;
//霍夫曼数结点
class HuffManNode
{
friend class HuffManTree;
public:
HuffManNode(){}
HuffManNode(int element, HuffManNode *lchild = NULL, HuffManNode *rchild = NULL);
int GetWeight() const;
private:
int weight;//结点的权值
HuffManNode *left;//左孩子
HuffManNode *right;//右孩子
};
//函数对象
class Greater
{
public:
bool operator() (const HuffManNode* left, const HuffManNode* right)
{
return left->GetWeight() > right->GetWeight();
}
};
// 霍夫曼树
class HuffManTree
{
public:
HuffManTree()
{
root = NULL;
}
void Initialize(int arr[], int n);
void MakeHuffManTree();
int GetTotalWeight() const;
void MiddleOrderOutPut(HuffManNode *node);
HuffManNode* GetRoot() const;
private:
priority_queue<HuffManNode*, vector<HuffManNode*>, Greater> d;
HuffManNode* root;
};
int main()
{
int arr[] = {5, 10, 20 ,30, 30};
int n = sizeof(arr) / sizeof(int);
HuffManTree tree;
tree.Initialize(arr, n);
tree.MakeHuffManTree();
cout<<"Total Wright = "<<tree.GetTotalWeight()<<endl;
cout<<"中序输出:";
tree.MiddleOrderOutPut(tree.GetRoot());
cout<<endl;
return 0;
}
//函数功能:构造函数
HuffManNode::HuffManNode(int element, HuffManNode *lchild, HuffManNode *rchild)
{
weight = element;
left = lchild;
right = rchild;
}
//函数功能:初始化
void HuffManTree::Initialize(int arr[], int n)
{
HuffManNode *node;
for (int i=0; i<n; ++i)
{
node = new HuffManNode(arr[i]);
d.push(node);
}
}
//函数功能:构造霍夫曼树
void HuffManTree::MakeHuffManTree()
{
do
{
HuffManNode *min1 = d.top();
d.pop();
HuffManNode *min2 = d.top();
d.pop();
HuffManNode *sum = new HuffManNode(min1->GetWeight() + min2->GetWeight());
d.push(sum);
root = sum;
root->left = min1;
root->right = min2;
} while (d.size() > 1);
}
//函数功能:得到HuffManNode结点的权值
inline int HuffManNode::GetWeight() const
{
return weight;
}
//函数功能:得到树总的权值
inline int HuffManTree::GetTotalWeight() const
{
assert(root != NULL);
return root->GetWeight();
}
//函数功能:中序输出
void HuffManTree::MiddleOrderOutPut(HuffManNode *node)
{
HuffManNode *temp = node;
if(temp != NULL)
{
MiddleOrderOutPut(temp->left);
cout<<temp->weight<<" ";
MiddleOrderOutPut(temp->right);
}
}
//函数功能:得到树根
HuffManNode* HuffManTree::GetRoot() const
{
return root;
}
算法连载(3)--生成最优归并树
分类: 开发/管理2005-04-1322:10 1048人阅读 评论(0) 收藏 举报
算法treestructclassjoin
1.问题描述:把N个已分类的文件通过成对地重复归并已分类的文件归并在一个文件中。例如,假定X1,X2,X3,X4是要归并的文件,则可以首先把X1,X2归并成Y1,然后Y1和X3归并成Y2,最后Y2和X4归并,从而得到要的分类文件。运用最优二路归并方法,归并出来的结果都有想对应的最小权带外部路径的二元树,所以把问题转换为由N棵根结点带权值的树组成的森林,归并成为一棵二元树。
2.设计思想与分析:
基本思路:(1)假设给定的一组权值{W1,W2,……,Wn},由此可以产生出由N棵二元树组成的森林F={T1,T2,……,Tn},其中每棵树都有一个权值为Wi的根结点;(2)在森林F中选出两棵树根结点的权值最小的树,作为一棵新树的左右子树且置新树的根结点的权值为其左右子树的根结点的权值之和;(3)从森林F中删去分别做为左右子树的这两棵树,同时将新树加入到集合F中;(4)对新的森林重复2,3步骤,直到F中只剩一棵二元树时为止,这就是所要的树了。
#include "iostream.h"
struct HuffmanNode
{
int weight;
int parent;
int lchild,rchild;
};////////////////////////////////structure of node
///////////////////////////////////////////////////class HuffmanTree
{
public:
HuffmanNode *Node;public: Tree(int weightnum);
};////////////////////////////////huaffmantree class ////////////////////////////////////////////////////
HuffmanTree::Tree(int weightnum)
{
int i , j, pos1,pos2;
int min1,min2;
Node=new struct HuffmanNode [2*weightnum-1];
for (i=0;i<weightnum;i++)
{
cout<<"请输入第"<<i+1<<"个字符的权值:";
cin>>Node[i].weight;
Node[i].parent=-1;
Node[i].lchild=-1;
Node[i].rchild=-1;
}
/////////////////////*join and creat tree*///////////////
for (i=weightnum; i<2*weightnum-1; i++) {
pos1=-1; pos2=-1;
min1=min2=32762;
j=0;
while(j<=i-1)
{
if (Node[j].parent==-1)
{
if(Node[j].weight<=min1)
{ min2=min1; min1=Node[j].weight;
pos2=pos1; pos1=j; }
else
if(Node[j].weight<min2)
{ min2=Node[j].weight; pos2=j; }
}
j++;
}//while
Node[pos1].parent=i;
Node[pos2].parent=i;
Node[i].lchild=pos1;
Node[i].rchild=pos2;
Node[i].parent=-1;
Node[i].weight=Node[pos1].weight+Node[pos2].weight;
}//for
j=2*weightnum-2;
int l,r;while(Node[j].lchild!=-1||Node[j].rchild!=-1)
{
cout<<"root is:"<<Node[j].weight<<" ";
l=Node[j].lchild;
r=Node[j].rchild;
cout<<"lchild is:"<<Node[l].weight<<" ";
cout<<"rchild is:"<<Node[r].weight<<" ";
cout<<endl;
j--;
}} //////////////////////////////////creat a Btree ///////////////////////////////////////////////
void main()
{ cout<<"|--------生成最优的二元归并树---------|"<<endl;
cout<<"|---power by zhanjiantao(028054115)---|"<<endl;
cout<<"|-------------------------------------|"<<endl;
int i;
while(i)
{
int weightnum;
cout<<"请输入权值的个数: ";
cin>>weightnum;
HuffmanTree t;
t.Tree(weightnum);
cout<<"Press<1> to run again"<<endl;
cout<<"Press<0> to exit"<<endl;
cin>>i;
}
}
