黑洞数
2016-06-18 12:18
260 查看
程序地址:http://www.cheemoedu.com/exercise/15
问题描述:
黑洞数又称陷阱数,是类具有奇特转换特性的整数。任何一个数字不全相同的整数,经有限“重排求差”操作,总会得到某一个或一些数,这些数即为黑洞数。“重排求差”操作即把组成该数的数字重排后得到的最大数减去重排后得到的最小数。
举个例子,3位数的黑洞数为495.
简易推导过程:随便找个数,如297,3个位上的数从小到大和从大到小各排一次,为972和279,相减得693。按上面做法再做一次,得到594,再做一次,得到495,之后反复都得到495。
验证3位数的黑洞数为495。
(已经做过一次6174了,这次做495的/article/11857579.html)
我的代码:
代码分析:
示例代码写的很简洁,也容易懂,大致流程是:将整型数据转换为列表形式(如[1,2,3])存到a中,然后a.sort()排序得到最小值列表,而最大值就是a[::-1]了,下面是用reduce函数将对应的最值列表转换为相应的整数(如123),然后再判断两值之差是否为495,是的话就直接返回,否则接着传入函数计算;
总结:
1.reduce函数
格式:reduce(function, sequence[, initial]) -> value
用传给reduce中的函数 func()(必须是一个二元操作函数)先对sequence中的第1,2个数据进行操作(第一次时为init的元素,如没有init则为seq的第一个元素),得到的结果再与第三个数据用func()函数运算......
简单来说,可以用这样一个形象化的式子来说明:
reduce( func, [1, 2,3] ) = func( func(1, 2), 3)
reduce函数的工作流程:
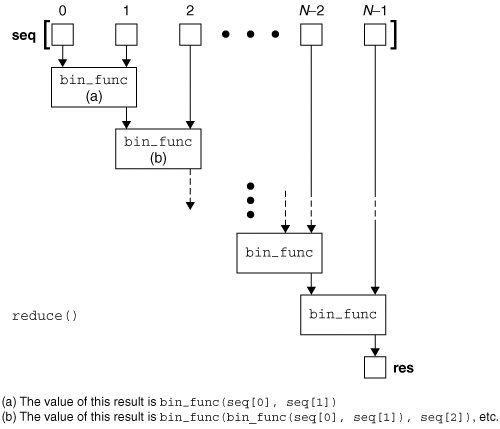
例如:
def sums(x,y):
return x+y
sum=reduce(sums,(1,2,3,4))
print sum
10
当然,也可以用lambda方法,更为简单:
>>> sum=reduce(lambda x,y:x+y,(1,2,3,4))
>>> sum
10
2.匿名函数lambda
格式:lambda [arguments]: expression
匿名是因为不需要以def的方式来声明,而def创建的方法是有名称的,这种语句的目的是由于性能的原因,在调用时绕过函数的栈分配,它们主要有2个地方不一样:
lambda表达式返回可调用的函数对象.但不会把这个函数对象赋给一个标识符,而def则会把函数对象赋值给一个变量;
lambda只是一个表达式,而def是一个语句,对于一些抽象的,不会别的地方再复用的函数,有时候给函数起个名字也是个难题,使用lambda不需要考虑命名的问题;
另外lambda函数可以很好和python中内建的filter(),map(),reduce()函数结合起来,因为它们都带了一个可执行的函数对象;
例如:
>>> def sums1(x,y):
return x+y
>>> sums1(1,2)
3
>>> sums2=lambda x,y : x+y
>>> sums2(1,2)
3
>>> sums3=lambda x,y=2:x+y
>>> sums3(1)
3
问题描述:
黑洞数又称陷阱数,是类具有奇特转换特性的整数。任何一个数字不全相同的整数,经有限“重排求差”操作,总会得到某一个或一些数,这些数即为黑洞数。“重排求差”操作即把组成该数的数字重排后得到的最大数减去重排后得到的最小数。
举个例子,3位数的黑洞数为495.
简易推导过程:随便找个数,如297,3个位上的数从小到大和从大到小各排一次,为972和279,相减得693。按上面做法再做一次,得到594,再做一次,得到495,之后反复都得到495。
验证3位数的黑洞数为495。
(已经做过一次6174了,这次做495的/article/11857579.html)
我的代码:
def minnb(n):
mi=[]
n.sort()
for i in range(len(n)):
mi.append(int(n[i]))
return mi
def maxnb(n):
ma=[]
n.sort(reverse=True)
for i in range(len(n)):
ma.append(int(n[i]))
return ma
def fun(ma,mi):
t=(ma[0]*100+ma[1]*10+ma[2])-(mi[0]*100+mi[1]*10+mi[2])
return t
def lists(s):
return list(str(s))
n=list(raw_input("input a number: "))
while True:
a=maxnb(n)
b=minnb(n)
c=fun(a,b)
if c==495:
print "It is OK..."
break
else:
n=lists(c)示例代码(已更改):def fun(n): a = [int(c) for c in str(n)] a.sort() s1 = reduce(lambda x, y: 10 * x + y, a[::-1]) s2 = reduce(lambda x, y: 10 * x + y, a) return 495 if s1 - s2 == 495 else fun(s1-s2) res = fun(123) print 'res : ', res
代码分析:
示例代码写的很简洁,也容易懂,大致流程是:将整型数据转换为列表形式(如[1,2,3])存到a中,然后a.sort()排序得到最小值列表,而最大值就是a[::-1]了,下面是用reduce函数将对应的最值列表转换为相应的整数(如123),然后再判断两值之差是否为495,是的话就直接返回,否则接着传入函数计算;
总结:
1.reduce函数
格式:reduce(function, sequence[, initial]) -> value
用传给reduce中的函数 func()(必须是一个二元操作函数)先对sequence中的第1,2个数据进行操作(第一次时为init的元素,如没有init则为seq的第一个元素),得到的结果再与第三个数据用func()函数运算......
简单来说,可以用这样一个形象化的式子来说明:
reduce( func, [1, 2,3] ) = func( func(1, 2), 3)
reduce函数的工作流程:
例如:
def sums(x,y):
return x+y
sum=reduce(sums,(1,2,3,4))
print sum
10
当然,也可以用lambda方法,更为简单:
>>> sum=reduce(lambda x,y:x+y,(1,2,3,4))
>>> sum
10
2.匿名函数lambda
格式:lambda [arguments]: expression
匿名是因为不需要以def的方式来声明,而def创建的方法是有名称的,这种语句的目的是由于性能的原因,在调用时绕过函数的栈分配,它们主要有2个地方不一样:
lambda表达式返回可调用的函数对象.但不会把这个函数对象赋给一个标识符,而def则会把函数对象赋值给一个变量;
lambda只是一个表达式,而def是一个语句,对于一些抽象的,不会别的地方再复用的函数,有时候给函数起个名字也是个难题,使用lambda不需要考虑命名的问题;
另外lambda函数可以很好和python中内建的filter(),map(),reduce()函数结合起来,因为它们都带了一个可执行的函数对象;
例如:
>>> def sums1(x,y):
return x+y
>>> sums1(1,2)
3
>>> sums2=lambda x,y : x+y
>>> sums2(1,2)
3
>>> sums3=lambda x,y=2:x+y
>>> sums3(1)
3

相关文章推荐
- eclipse中解决65536
- RxJava
- 215. Kth Largest Element in an Array
- faster_rcnn c++版本的 caffe 封装,动态库(2)
- 3ds max 渲染清晰面片的边缘
- JQuery_Validation_plugin
- 第一个博客 属于自己的
- C程序编译过程浅析
- scikit-learn : 线性回归
- MongoDB的性能监控
- faster_rcnn c++版本的 caffe 封装(1)
- 第十三周项目1(1)
- memcache对hash一致性算法和取模算法详解
- 1018. 锤子剪刀布 (20)
- 论文阅读笔记:You Only Look Once: Unified, Real-Time Object Detection
- openwrt启动脚本分析
- html5中file对象
- 最小二乘与梯度下降的关联与区别
- 最小二乘与梯度下降的关联与区别
- 最小二乘与梯度下降的关联与区别