多进程单线程模型与单进程多线程模型之争
2016-06-17 12:12
288 查看
服务器,事件
多进程单线程模型典型代表:nginx单进程多线程模型典型代表:memcached
另外redis, mongodb也可以说是走的“多进程单线程模”模型(集群),只不过作为数据库服务器,需要进行写保护,只提供了读同步。
原因很简单,因为服务器的发展大部分都是归功于Linux Unix,而不是Windows。
Linux内核提供的epoll为开发服务器提供了很大的便利,libevent和libev都是对epoll的封装,nginx自己实现了对epoll的封装。
libevent和libev都是知名的Linux系统C事件驱动编程框架。
我没说错的话,nodejs是建立在libev基础上。
memcached也依赖libevent。
所以,nginx在Windows上不像Linux快是有很大原因的。
模型,模型,多进程单线程 单进程多线程
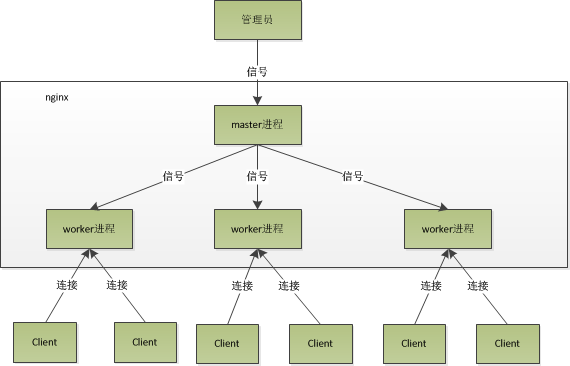
多进程单线程master进程管理worker进程:
接收来自外界的信号
向各worker进程发送信号
监控woker进程的运行状态
当woker进程退出后(异常情况下),会自动重新启动新的woker进程
友情提示:nodejs属于这一种好不好,不是只能单核
单进程多线程
单进程多线程
主线程负责监听客户端的连接请求,workers线程负责处理已经建立好的连接的读写等事件

单进程多线程
单进程多线程肯定比多进程单线程快一些
多进程单线程与单进程多线程的目的都是想尽可能的利用CPU,减少CPU的空闲时间,特别是多核环境。他们在实际运行中,所利用的CPU工作数应该都是相同的。也就是说,你有4核,在某个时刻要么是CPU同时在4个进程做任务(多进程单线程),要么是CPU同时在4个线程上做任务(单进程多线程)。
不过,单进程多线程肯定比多进程单线程快一些。
这是因为,多进程单线程的CPU切换,是从一个进程到另一个进程,而单进程多线程的CPU切换则只在一个进程内,每个进程|线程都有自己的上下文堆栈保存,进程间的切换消耗更大一些。
这就好比是,多进程单线程是在4个函数中切换,各自拥有自己的变量;单进程多线程在1个函数中的4个子函数切换,拥有相同的全局变量。
但是,没有你想象的“快几倍”。
副作用,副作用,单进程多线程肯定有其不利的一面
我一直提过副作用。如果你仔细看多进程单线程的图,就应该明白,这种模型提供了一种保护机制。
当其中一个进程内部读取错误,master可以让ta重启。这使得你的服务器在表面上并没有感到“曾经崩溃”。
对于master,完全不涉及服务器的业务,使得ta能被安全隔离。
再来看单进程多线程。
问题很明显,只有一个进程,一旦其中出现一个错误,整个进程都有可能挂掉。你当然可以为ta编写一个“守护程序”来重启,但是重启期间,你的服务器是真的“挂掉了”。
另外,编写单进程多线程这样的服务器,在代码上非常容易出错,而且难以控制代码的稳定性,有很多你难以琢磨的bug在等着你,因为有太多的锁,太多的全局变量需要处理,这也是函数式“纯函数”所反对的。
nodejs不能CPU密集处理?
你觉得ruby,python,php就能密集处理?有人说:java, c#。
拜托,如果你真的想要密集处理,请使用C C++。(我个人只会用C)你见过哪个数据库服务器是java c#写的?
而现在,我觉得Rust lang是一个好的方向:
面向操作系统编程
从语言层面上提供并发
自诩C++的替代者
将会重写firefox
Mozilla开发
Javascript的作者Brendan Eich是编写者之一
类似javascript的语法和编写体验
而且我已经开始憧憬未来使用nodejs + Rust开发服务器体验的场景。
原文链接:http://www.jianshu.com/p/c61a7746d139

相关文章推荐
- Python3写爬虫(四)多线程实现数据爬取
- C#实现多线程的同步方法实例分析
- C#线程间不能调用剪切板的解决方法
- 浅谈chuck-lua中的多线程
- C#简单多线程同步和优先权用法实例
- C#多线程学习之(四)使用线程池进行多线程的自动管理
- C#多线程编程中的锁系统(三)
- C#线程同步的三类情景分析
- C#获取进程或线程相关信息的方法
- 简单对比C#程序中的单线程与多线程设计
- C#停止线程的方法
- 解析C#多线程编程中异步多线程的实现及线程池的使用
- C#子线程更新UI控件的方法实例总结
- C#多线程学习之(六)互斥对象用法实例
- C#线程队列用法实例分析
- 基于一个应用程序多线程误用的分析详解
- C#多线程学习之(三)生产者和消费者用法分析
- C#多线程学习之(一)多线程的相关概念分析
- C#多线程之Thread中Thread.IsAlive属性用法分析
- 分享我在工作中遇到的多线程下导致RCW无法释放的问题