pthread的各种同步机制
2016-06-17 12:05
218 查看
转载自:http://blog.csdn.net/liutianshx2012/article/details/45743333
pthread是POSIX标准的多线程库,UNIX、Linux上广泛使用,windows上也有对应的实现,所有的函数都是pthread打头,也就一百多个函数,不是很复杂。然而多线程编程被普遍认为复杂,主要是因为多线程给程序引入了一定的不可预知性,要控制这些不可预知性,就需要使用各种锁各种同步机制,不同的情况就应该使用不同的锁不同的机制。什么事情一旦放到多线程环境,要考虑的问题立刻就上升了好几个量级。多线程编程就像潘多拉魔盒,带来的好处不可胜数,然而工程师只要一不小心,就很容易让你的程序失去控制,所以你得用各种锁各种机制管住它。要解决好这些问题,工程师们就要充分了解这些锁机制,分析不同的场景,选择合适的解决方案。
MUTual-EXclude Lock,互斥锁。 它是理解最容易,使用最广泛的一种同步机制。顾名思义,被这个锁保护的临界区就只允许一个线程进入,其它线程如果没有获得锁权限,那就只能在外面等着。
它使用得非常广泛,以至于大多数人谈到锁就是mutex。mutex是互斥锁,pthread里面还有很多锁,mutex只是其中一种。
mutex的初始化分两种,一种是用宏(PTHREAD_MUTEX_INITIALIZER),一种是用函数(pthread_mutex_init)。 如果没有特殊的配置要求的话,使用宏比较好,因为它比较快。只有真的需要配置的时候,才需要用函数。也就是说,凡是
但是业界有另一种说法是:早年的POSIX只支持在static变量上使用
基本上所有的问题都可以用互斥的方案去解决,大不了就是慢点儿,但不要不管什么情况都用互斥,都能采用这种方案不代表都适合采用这种方案。而且这里所说的慢不是说mutex的实现方案比较慢,而是互斥方案影响的面比较大,本来不需要通过互斥就能让线程进入临界区,但用了互斥方案之后,就使这样的线程不得不等待互斥锁的释放,所以就慢了。甚至有些场合用互斥就很蛋疼,比如多资源分配,线程步调通知等。 如果是读多写少的场合,就比较适合读写锁(reader/writter lock),如果临界区比较短,就适合空转锁(pin lock)...这些我在后面都会说的,你可以翻到下面去看。
提到这个的原因是:大多数人学pthread学到mutex就结束了,然后不管什么都用mutex。那是不对的!!!
如果要进入一段临界区需要多个mutex锁,那么就很容易导致死锁,单个mutex锁是不会引发死锁的。要解决这个问题也很简单,只要申请锁的时候按照固定顺序,或者及时释放不需要的mutex锁就可以。这就对我们的代码有一定的要求,尤其是全局mutex锁的时候,更需要遵守一个约定。
如果是全局mutex锁,我习惯将它们写在同一个头文件里。一个模块的文件再多,都必须要有两个umbrella header file。一个是整个模块的伞,外界使用你的模块的时候,只要include这个头文件即可。另一个用于给模块的所有子模块去include,然后这个头文件里面就放一些公用的宏啊,配置啊啥的,全局mutex放在这里就最合适了。这两个文件不能是同一个,否则容易出循环include的问题。如果有人写模块不喜欢写这样的头文件的,那现在就要改了。
然后我的mutex锁的命名规则就是:
如果是属于某个struct内部的mutex锁,那么也一样,只不过序号可以不必跟全局锁挂钩,也可以从1开始数。
还有另一种方案也非常有效,就是用
当然也可以使用
这两种方案我更多会使用第一种,原因如下:
一般情况下进入临界区需要加的锁数量不会太多,第一种方案能够hold住。如果多于2个,你就要考虑一下是否有些锁是可以合并的了。
第一种方案适合锁比较少的情况,因为这不会导致非常大的阻塞延时。但是当你要加的锁非常多,ABCDE,你加到D的时候阻塞了,然而其他线程可能只需要AB就可以运行,就也会因为AB已经被锁住而阻塞,这时候才会采用第二种方案。如果要加的锁本身就不多,只有AB两个,那么阻塞一下也还可以。
第二种方案在面临阻塞的时候,要操作的事情太多。
当你把所有的锁都释放以后,你的当前线程的处理策略就会导致你的代码复杂度上升:当前线程总不能就此退出吧,你得找个地方把它放起来,让它去等待一段时间之后再去申请锁,如果有多个线程出现了这样的情况,你就需要一个线程池来存放这些等待解锁的线程。如果临界区是嵌套的,你在把这个线程挂起的时候,最好还要把外面的锁也释放掉,要不然也会容易导致死锁,这就需要你在一个地方记录当前线程使用锁的情况。这里要做的事情太多,复杂度比较大,容易出错。
所以总而言之,设计的时候尽量减少同一临界区所需要mutex锁的数量,然后采用第一种方案。如果确实有需求导致那么多mutex锁,那么就只能采用第二种方案了,然后老老实实写好周边代码。但是!umbrella header file和按照序号命名mutex锁是个非常好的习惯,可以允许你随着软件的发展而灵活采取第一第二种方案。
但是到了semaphore情况下的死锁处理方案时,上面两种方案就都不顶用了,后面我会说。另外,还有一种死锁是自己把自己锁死了,这个我在后面也会说。
前面mutex锁有个缺点,就是只要锁住了,不管其他线程要干什么,都不允许进入临界区。设想这样一种情况:临界区foo变量在被bar1线程读着,加了个mutex锁,bar2线程如果也要读foo变量,因为被bar1加了个互斥锁,那就不能读了。但事实情况是,读取数据不影响数据内容本身,所以即便被1个线程读着,另外一个线程也应该允许他去读。除非另外一个线程是写操作,为了避免数据不一致的问题,写线程就需要等读线程都结束了再写。
因此诞生了Reader-Writter Lock,有的地方也叫Shared-Exclusive Lock,共享锁。
Reader-Writter Lock的特性是这样的,当一个线程加了读锁访问临界区,另外一个线程也想访问临界区读取数据的时候,也可以加一个读锁,这样另外一个线程就能够成功进入临界区进行读操作了。此时读锁线程有两个。当第三个线程需要进行写操作时,它需要加一个写锁,这个写锁只有在读锁的拥有者为0时才有效。也就是等前两个读线程都释放读锁之后,第三个线程就能进去写了。总结一下就是,读写锁里,读锁能允许多个线程同时去读,但是写锁在同一时刻只允许一个线程去写。
这样更精细的控制,就能减少mutex导致的阻塞延迟时间。虽然用mutex也能起作用,但这种场合,明显读写锁更好嘛!
跟上面提到的写muetx锁的约定一样,操作,类别,序号最好都要有。比如
由于读写锁的性质,在默认情况下是很容易出现写线程饥饿的。因为它必须要等到所有读锁都释放之后,才能成功申请写锁。不过不同系统的实现版本对写线程的优先级实现不同。Solaris下面就是写线程优先,其他系统默认读线程优先。
比如在写线程阻塞的时候,有很多读线程是可以一个接一个地在那儿插队的(在默认情况下,只要有读锁在,写锁就无法申请,然而读锁可以一直申请成功,就导致所谓的插队现象),那么写线程就不知道什么时候才能申请成功写锁了,然后它就饿死了。
为了控制写线程饥饿,必须要在创建读写锁的时候设置
总的来说,这样的锁建立之后一定要设置优先级,不然就容易出现写线程饥饿。而且读写锁适合读多写少的情况,如果读、写一样多,那这时候还是用mutex锁比较合理。
上面在给出mutex锁的实现代码的时候提到了这个spin lock,空转锁。它是互斥锁、读写锁的基础。在其它同步机制里condition variable、barrier等都有它的身影。
我先说一下其他锁申请加锁的过程,你就知道什么是spin lock了。
互斥锁和读写锁在申请加锁的时候,会使得线程阻塞,阻塞的过程又分两个阶段,第一阶段是会先空转,可以理解成跑一个while循环,不断地去申请锁,在空转一定时间之后,线程会进入waiting状态(对的,跟进程一样,线程也分很多状态),此时线程就不占用CPU资源了,等锁可用的时候,这个线程会被唤醒。
为什么会有这两个阶段呢?主要还是出于效率因素。
如果单纯在申请锁失败之后,立刻将线程状态挂起,会带来context切换的开销,但挂起之后就可以不占用CPU资源了,原属于这个线程的CPU时间就可以拿去做更加有意义的事情。假设锁在第一次申请失败之后就又可用了,那么短时间内进行context切换的开销就显得很没效率。
如果单纯在申请锁失败之后,不断轮询申请加锁,那么可以在第一时间申请加锁成功,同时避免了context切换的开销,但是浪费了宝贵的CPU时间。假设锁在第一次申请失败之后,很久很久才能可用,那么CPU在这么长时间里都被这个线程拿来轮询了,也显得很没效率。
于是就出现了两种方案结合的情况:在第一次申请加锁失败的时候,先不着急切换context,空转一段时间。如果锁在短时间内又可用了,那么就避免了context切换的开销,CPU浪费的时间也不多。空转一段时间之后发现还是不能申请加锁成功,那么就有很大概率在将来的不短的一段时间里面加锁也不成功,那么就把线程挂起,把轮询用的CPU时间释放出来给别的地方用。
所以spin lock就是这样的一个锁:
这里是spin lock申请加锁的实现:
我没在man里面找到spin lock相关的函数,但事实上外面还是能够使用的,下面是我在源代码里面挖到的原型:
了解了空转锁的特性,我们就发现这个锁其实非常适合临界区非常短的场合,或者实时性要求比较高的场合。
由于临界区短,线程需要等待的时间也短,即便轮询浪费CPU资源,也浪费不了多少,还省了context切换的开销。 由于实时性要求比较高,来不及等待context切换的时间,那就只能浪费CPU资源在那儿轮询了。
不过说实话,大部分情况你都不会直接用到空转锁,其他锁在申请不到加锁时也是会空转一定时间的,如果连这段时间都无法满足你的请求,那要么就是你扔的线程太多,或者你的临界区没你想象的那么短。
场景:B线程和A线程之间有合作关系,当A线程完成某件事情之前,B线程会等待。当A线程完成某件事情之后,需要让B线程知道,然后B线程从等待状态中被唤醒,然后继续做自己要做的事情。
如果不用条件变量的话,也行。那就是搞个volatile变量,然后让其他线程不断轮询,一旦这个变量到了某个值,你就可以让线程继续了。如果有多个线程需要修改这个变量,那就再加个互斥锁或者读写锁。
但是!!!这做法太特么愚蠢了,还特别浪费CPU时间,所以还在用volatile变量标记线程状态的你们也真是够了!!!
大致的实现原理是:一个条件变量背后有一个池子,所有需要wait这个变量的线程都会进入这个池子。当有线程扔出这个条件变量的signal,系统就会把这个池子里面的线程挨个唤醒。
补充一下,原则上
另外,在调用
下面我先给一个条件变量的使用例子,然后再讲需要注意的点。
这样行不行?当然不行。为什么不行?
这里涉及一个非常精巧的情况:在
这样行不行?当然不行。为什么不行?
比如
这样行不行?大多数情况行,但是用while更加安全。
如果有别人写一个线程去把这个done搞成0了,期间没有申请mutex锁。
那么这时用if去判断的话,由于线程已经从wait状态唤醒,它会直接做下面的事情,而全然不知done的值已经变了。
如果这时用while去判断的话,在
不过这解决不了根本问题哈,如果那个不长眼的线程在while的第二次判断之后改了done,那还是要悲剧。根本方案还是要在改done的时候加mutex锁。
总而言之,用if也可以,毕竟不太容易出现不长眼的线程改done变量不申请加mutex锁的。用while的话就多了一次判断,安全了一点,即便有不长眼的线程干了这么龌龊的事情,也还能hold住。
这样行不行?当然不行。为什么不行?《Advanced Programming in the UNIX Enviroment 3 Edtion》这本书里也把扔信号的事儿放在临界区外面了呢。
插播:
(此处张扬同学指出《APUE》在这里有一段论述,在这里我把这段摘下来)
《APUE》中关于这个问题是这么描述的:
When we put a message on the work queue, we need to hold the mutex, but we don’t need to hold the mutex when we signal the waiting threads. As long as it is okay for a thread to pull the message off the queue before
we call cond_signal, we can do this after releasing the mutex.
在临界区外扔signal这种做法需要满足一些前提,这种做法不属于一种普适做法。所以我认为在制定编程规范的时候,应该禁止这种做法。在这份资料的第5页也对这个问题有一段小的论证。它的建议也是
上面提到的资料的原文如下:
插播结束
不行就是不行,哪怕是圣经上这么写,也不行。哼。
就应该永远都在临界区里面扔条件信号,我画了一个高清图来解释这个事情,图比较大,可能要加载一段时间:
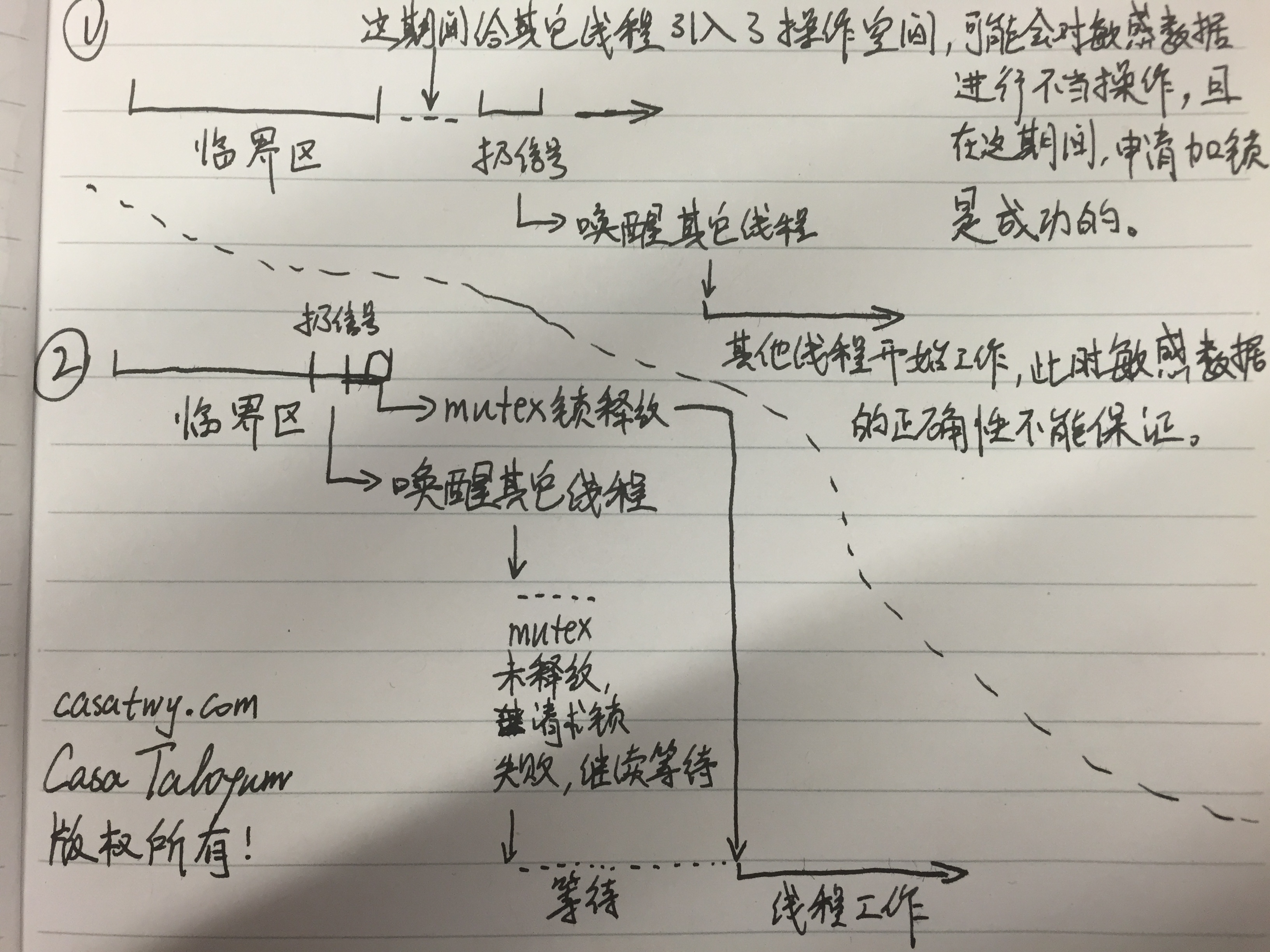
看到了吧,1的情况就是在临界区外扔信号的坏处。由于在临界区外,其他线程要申请加mutex锁是可以成功的,然后这个线程要是改了你的敏感数据,你就只能去哭了...
简述
pthread是POSIX标准的多线程库,UNIX、Linux上广泛使用,windows上也有对应的实现,所有的函数都是pthread打头,也就一百多个函数,不是很复杂。然而多线程编程被普遍认为复杂,主要是因为多线程给程序引入了一定的不可预知性,要控制这些不可预知性,就需要使用各种锁各种同步机制,不同的情况就应该使用不同的锁不同的机制。什么事情一旦放到多线程环境,要考虑的问题立刻就上升了好几个量级。多线程编程就像潘多拉魔盒,带来的好处不可胜数,然而工程师只要一不小心,就很容易让你的程序失去控制,所以你得用各种锁各种机制管住它。要解决好这些问题,工程师们就要充分了解这些锁机制,分析不同的场景,选择合适的解决方案。
Mutex Lock 互斥锁
MUTual-EXclude Lock,互斥锁。 它是理解最容易,使用最广泛的一种同步机制。顾名思义,被这个锁保护的临界区就只允许一个线程进入,其它线程如果没有获得锁权限,那就只能在外面等着。它使用得非常广泛,以至于大多数人谈到锁就是mutex。mutex是互斥锁,pthread里面还有很多锁,mutex只是其中一种。
相关宏和函数
PTHREAD_MUTEX_INITIALIZER // 用于静态的mutex的初始化,采用默认的attr。比如: static pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER; int pthread_mutex_init(pthread_mutex_t *restrict mutex, const pthread_mutexattr_t *restrict attr); // 用于动态的初始化 int pthread_mutex_destroy(pthread_mutex_t *mutex); // 把mutex锁干掉,并且释放所有它所占有的资源 int pthread_mutex_lock(pthread_mutex_t *mutex); // 请求锁,如果当前mutex已经被锁,那么这个线程就会卡在这儿,直到mutex被释放 int pthread_mutex_unlock(pthread_mutex_t *mutex); // 解锁 int pthread_mutex_trylock(pthread_mutex_t *mutex); // 尝试请求锁,如果当前mutex已经被锁或者不可用,这个函数就直接return了,不会把线程卡住
要注意的地方
关于mutex的初始化
mutex的初始化分两种,一种是用宏(PTHREAD_MUTEX_INITIALIZER),一种是用函数(pthread_mutex_init)。 如果没有特殊的配置要求的话,使用宏比较好,因为它比较快。只有真的需要配置的时候,才需要用函数。也就是说,凡是pthread_mutex_init(&mutex, NULL)的地方都可以使用
PTHREAD_MUTEX_INITIALIZER,因为在
pthread_mutex_init这个函数里的实现其实也是用了
PTHREAD_MUTEX_INITIALIZER:
///////////////////// pthread_src/include/pthread/pthread.h
#define PTHREAD_MUTEX_INITIALIZER __PTHREAD_MUTEX_INITIALIZER
///////////////////// pthread_src/sysdeps/generic/bits/mutex.h
# define __PTHREAD_MUTEX_INITIALIZER \
{ __PTHREAD_SPIN_LOCK_INITIALIZER, __PTHREAD_SPIN_LOCK_INITIALIZER, 0, 0, 0, 0, 0, 0 } // mutex锁本质上是一个spin lock,空转锁,关于空转锁的东西在下面会提到。
///////////////////// pthread_src/sysdeps/generic/pt-mutex-init.c
int
_pthread_mutex_init (pthread_mutex_t *mutex,
const pthread_mutexattr_t *attr)
{
*mutex = (pthread_mutex_t) __PTHREAD_MUTEX_INITIALIZER; // 你看,这里其实用的也是宏。就这一句是初始化,下面都是在设置属性。
if (! attr
|| memcmp (attr, &__pthread_default_mutexattr, sizeof (*attr) == 0))
/* The default attributes. */
return 0;
if (! mutex->attr
|| mutex->attr == __PTHREAD_ERRORCHECK_MUTEXATTR
|| mutex->attr == __PTHREAD_RECURSIVE_MUTEXATTR)
mutex->attr = malloc (sizeof *attr); //pthread_mutex_destroy释放的就是这里的资源
if (! mutex->attr)
return ENOMEM;
*mutex->attr = *attr;
return 0;
}但是业界有另一种说法是:早年的POSIX只支持在static变量上使用
PTHREAD_MUTEX_INITIALIZER,所以
PTHREAD_MUTEX_INITIALIZER尽量不要到处都用,所以使用的时候你得搞清楚你的pthread的实现版本是不是比较老的。
mutex锁不是万能灵药
基本上所有的问题都可以用互斥的方案去解决,大不了就是慢点儿,但不要不管什么情况都用互斥,都能采用这种方案不代表都适合采用这种方案。而且这里所说的慢不是说mutex的实现方案比较慢,而是互斥方案影响的面比较大,本来不需要通过互斥就能让线程进入临界区,但用了互斥方案之后,就使这样的线程不得不等待互斥锁的释放,所以就慢了。甚至有些场合用互斥就很蛋疼,比如多资源分配,线程步调通知等。 如果是读多写少的场合,就比较适合读写锁(reader/writter lock),如果临界区比较短,就适合空转锁(pin lock)...这些我在后面都会说的,你可以翻到下面去看。提到这个的原因是:大多数人学pthread学到mutex就结束了,然后不管什么都用mutex。那是不对的!!!
预防死锁
如果要进入一段临界区需要多个mutex锁,那么就很容易导致死锁,单个mutex锁是不会引发死锁的。要解决这个问题也很简单,只要申请锁的时候按照固定顺序,或者及时释放不需要的mutex锁就可以。这就对我们的代码有一定的要求,尤其是全局mutex锁的时候,更需要遵守一个约定。如果是全局mutex锁,我习惯将它们写在同一个头文件里。一个模块的文件再多,都必须要有两个umbrella header file。一个是整个模块的伞,外界使用你的模块的时候,只要include这个头文件即可。另一个用于给模块的所有子模块去include,然后这个头文件里面就放一些公用的宏啊,配置啊啥的,全局mutex放在这里就最合适了。这两个文件不能是同一个,否则容易出循环include的问题。如果有人写模块不喜欢写这样的头文件的,那现在就要改了。
然后我的mutex锁的命名规则就是:
作用_mutex_序号,比如
LinkListMutex_mutex_1,
OperationQueue_mutex_2,后面的序号在每次有新锁的时候,就都加一个1。如果有哪个临界区进入的时候需要获得多个mutex锁的,我就按照序号的顺序去进行加锁操作(pthread_mutex_lock),这样就能够保证不会出现死锁了。
如果是属于某个struct内部的mutex锁,那么也一样,只不过序号可以不必跟全局锁挂钩,也可以从1开始数。
还有另一种方案也非常有效,就是用
pthread_mutex_trylock函数来申请加锁,这个函数在mutex锁不可用时,不像
pthread_mutex_lock那样会等待。
pthread_mutex_trylock在申请加锁失败时立刻就会返回错误:
EBUSY(锁尚未解除)或者
EINVAL(锁变量不可用)。一旦在trylock的时候有错误返回,那就把前面已经拿到的锁全部释放,然后过一段时间再来一遍。
当然也可以使用
pthread_mutex_timedlock这个函数来申请加锁,这个函数跟
pthread_mutex_trylock类似,不同的是,你可以传入一个时间参数,在申请加锁失败之后会阻塞一段时间等解锁,超时之后才返回错误。
这两种方案我更多会使用第一种,原因如下:
一般情况下进入临界区需要加的锁数量不会太多,第一种方案能够hold住。如果多于2个,你就要考虑一下是否有些锁是可以合并的了。
第一种方案适合锁比较少的情况,因为这不会导致非常大的阻塞延时。但是当你要加的锁非常多,ABCDE,你加到D的时候阻塞了,然而其他线程可能只需要AB就可以运行,就也会因为AB已经被锁住而阻塞,这时候才会采用第二种方案。如果要加的锁本身就不多,只有AB两个,那么阻塞一下也还可以。
第二种方案在面临阻塞的时候,要操作的事情太多。
当你把所有的锁都释放以后,你的当前线程的处理策略就会导致你的代码复杂度上升:当前线程总不能就此退出吧,你得找个地方把它放起来,让它去等待一段时间之后再去申请锁,如果有多个线程出现了这样的情况,你就需要一个线程池来存放这些等待解锁的线程。如果临界区是嵌套的,你在把这个线程挂起的时候,最好还要把外面的锁也释放掉,要不然也会容易导致死锁,这就需要你在一个地方记录当前线程使用锁的情况。这里要做的事情太多,复杂度比较大,容易出错。
所以总而言之,设计的时候尽量减少同一临界区所需要mutex锁的数量,然后采用第一种方案。如果确实有需求导致那么多mutex锁,那么就只能采用第二种方案了,然后老老实实写好周边代码。但是!umbrella header file和按照序号命名mutex锁是个非常好的习惯,可以允许你随着软件的发展而灵活采取第一第二种方案。
但是到了semaphore情况下的死锁处理方案时,上面两种方案就都不顶用了,后面我会说。另外,还有一种死锁是自己把自己锁死了,这个我在后面也会说。
Reader-Writter Lock 读写锁
前面mutex锁有个缺点,就是只要锁住了,不管其他线程要干什么,都不允许进入临界区。设想这样一种情况:临界区foo变量在被bar1线程读着,加了个mutex锁,bar2线程如果也要读foo变量,因为被bar1加了个互斥锁,那就不能读了。但事实情况是,读取数据不影响数据内容本身,所以即便被1个线程读着,另外一个线程也应该允许他去读。除非另外一个线程是写操作,为了避免数据不一致的问题,写线程就需要等读线程都结束了再写。因此诞生了Reader-Writter Lock,有的地方也叫Shared-Exclusive Lock,共享锁。
Reader-Writter Lock的特性是这样的,当一个线程加了读锁访问临界区,另外一个线程也想访问临界区读取数据的时候,也可以加一个读锁,这样另外一个线程就能够成功进入临界区进行读操作了。此时读锁线程有两个。当第三个线程需要进行写操作时,它需要加一个写锁,这个写锁只有在读锁的拥有者为0时才有效。也就是等前两个读线程都释放读锁之后,第三个线程就能进去写了。总结一下就是,读写锁里,读锁能允许多个线程同时去读,但是写锁在同一时刻只允许一个线程去写。
这样更精细的控制,就能减少mutex导致的阻塞延迟时间。虽然用mutex也能起作用,但这种场合,明显读写锁更好嘛!
相关宏和函数
PTHREAD_RWLOCK_INITIALIZER int pthread_rwlock_init(pthread_rwlock_t *restrict rwlock, const pthread_rwlockattr_t *restrict attr); int pthread_rwlock_destroy(pthread_rwlock_t *rwlock); int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock); int pthread_rwlock_tryrdlock(pthread_rwlock_t *rwlock); int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock); int pthread_rwlock_trywrlock(pthread_rwlock_t *rwlock); int pthread_rwlock_unlock(pthread_rwlock_t *rwlock); int pthread_rwlock_timedrdlock_np(pthread_rwlock_t *rwlock, const struct timespec *deltatime); // 这个函数在Linux和Mac的man文档里都没有,新版的pthread.h里面也没有,旧版的能找到 int pthread_rwlock_timedwrlock_np(pthread_rwlock_t *rwlock, const struct timespec *deltatime); // 同上
要注意的地方
命名
跟上面提到的写muetx锁的约定一样,操作,类别,序号最好都要有。比如OperationQueue_rwlock_1。
认真区分使用场合,记得避免写线程饥饿
由于读写锁的性质,在默认情况下是很容易出现写线程饥饿的。因为它必须要等到所有读锁都释放之后,才能成功申请写锁。不过不同系统的实现版本对写线程的优先级实现不同。Solaris下面就是写线程优先,其他系统默认读线程优先。比如在写线程阻塞的时候,有很多读线程是可以一个接一个地在那儿插队的(在默认情况下,只要有读锁在,写锁就无法申请,然而读锁可以一直申请成功,就导致所谓的插队现象),那么写线程就不知道什么时候才能申请成功写锁了,然后它就饿死了。
为了控制写线程饥饿,必须要在创建读写锁的时候设置
PTHREAD_RWLOCK_PREFER_WRITER_NONRECURSIVE,不要用
PTHREAD_RWLOCK_PREFER_WRITER_NP啊,这个似乎没什么用,感觉应该是个bug,不要问我是怎么知道的。。。
////////////////////////////// /usr/include/pthread.h
/* Read-write lock types. */
#if defined __USE_UNIX98 || defined __USE_XOPEN2K
enum
{
PTHREAD_RWLOCK_PREFER_READER_NP,
PTHREAD_RWLOCK_PREFER_WRITER_NP, // 妈蛋,没用,一样reader优先
PTHREAD_RWLOCK_PREFER_WRITER_NONRECURSIVE_NP,
PTHREAD_RWLOCK_DEFAULT_NP = PTHREAD_RWLOCK_PREFER_READER_NP
};总的来说,这样的锁建立之后一定要设置优先级,不然就容易出现写线程饥饿。而且读写锁适合读多写少的情况,如果读、写一样多,那这时候还是用mutex锁比较合理。
spin lock 空转锁
上面在给出mutex锁的实现代码的时候提到了这个spin lock,空转锁。它是互斥锁、读写锁的基础。在其它同步机制里condition variable、barrier等都有它的身影。我先说一下其他锁申请加锁的过程,你就知道什么是spin lock了。
互斥锁和读写锁在申请加锁的时候,会使得线程阻塞,阻塞的过程又分两个阶段,第一阶段是会先空转,可以理解成跑一个while循环,不断地去申请锁,在空转一定时间之后,线程会进入waiting状态(对的,跟进程一样,线程也分很多状态),此时线程就不占用CPU资源了,等锁可用的时候,这个线程会被唤醒。
为什么会有这两个阶段呢?主要还是出于效率因素。
如果单纯在申请锁失败之后,立刻将线程状态挂起,会带来context切换的开销,但挂起之后就可以不占用CPU资源了,原属于这个线程的CPU时间就可以拿去做更加有意义的事情。假设锁在第一次申请失败之后就又可用了,那么短时间内进行context切换的开销就显得很没效率。
如果单纯在申请锁失败之后,不断轮询申请加锁,那么可以在第一时间申请加锁成功,同时避免了context切换的开销,但是浪费了宝贵的CPU时间。假设锁在第一次申请失败之后,很久很久才能可用,那么CPU在这么长时间里都被这个线程拿来轮询了,也显得很没效率。
于是就出现了两种方案结合的情况:在第一次申请加锁失败的时候,先不着急切换context,空转一段时间。如果锁在短时间内又可用了,那么就避免了context切换的开销,CPU浪费的时间也不多。空转一段时间之后发现还是不能申请加锁成功,那么就有很大概率在将来的不短的一段时间里面加锁也不成功,那么就把线程挂起,把轮询用的CPU时间释放出来给别的地方用。
所以spin lock就是这样的一个锁:
它在第一次申请加锁失败的时候,会不断轮询,直到申请加锁成功为止,期间不会进行线程context的切换。,《APUE》中原文是这样:
A spin lock is like a mutex, except that instead of blocking a process by sleeping, the process is blocked by busy-waiting (spinning) until the lock can be acquired.互斥锁和读写锁基于spin lock又多做了超时检查和切换context的操作,如此而已。事实上,spin lock在实现的时候,有一个
__pthread_spin_count限制,如果空转次数超过这个限制,线程依旧会挂起(
__shed_yield)。
这里是spin lock申请加锁的实现:
/////////////////////////////pthread_src/sysdeps/posix/pt-spin.c
/* Lock the spin lock object LOCK. If the lock is held by another
thread spin until it becomes available. */
int
_pthread_spin_lock (__pthread_spinlock_t *lock)
{
int i;
while (1)
{
for (i = 0; i < __pthread_spin_count; i++)
{
if (__pthread_spin_trylock (lock) == 0)
return 0;
}
__sched_yield ();
}
}
相关宏和函数
我没在man里面找到spin lock相关的函数,但事实上外面还是能够使用的,下面是我在源代码里面挖到的原型:////////////////////////////////pthread_src/pthread/pt-spin-inlines.c /* Weak aliases for the spin lock functions. Note that pthread_spin_lock is left out deliberately. We already provide an implementation for it in pt-spin.c. */ weak_alias (__pthread_spin_destroy, pthread_spin_destroy); weak_alias (__pthread_spin_init, pthread_spin_init); weak_alias (__pthread_spin_trylock, pthread_spin_trylock); weak_alias (__pthread_spin_unlock, pthread_spin_unlock); /////////////////////////////////pthread_src/sysdeps/posix/pt-spin.c weak_alias (_pthread_spin_lock, pthread_spin_lock); /*-------------------------------------------------*/ PTHREAD_SPINLOCK_INITIALIZER int pthread_spin_init (__pthread_spinlock_t *__lock, int __pshared); int pthread_spin_destroy (__pthread_spinlock_t *__lock); int pthread_spin_trylock (__pthread_spinlock_t *__lock); int pthread_spin_unlock (__pthread_spinlock_t *__lock); int pthread_spin_lock (__pthread_spinlock_t *__lock); /*-------------------------------------------------*/
注意事项
还是要分清楚使用场合
了解了空转锁的特性,我们就发现这个锁其实非常适合临界区非常短的场合,或者实时性要求比较高的场合。由于临界区短,线程需要等待的时间也短,即便轮询浪费CPU资源,也浪费不了多少,还省了context切换的开销。 由于实时性要求比较高,来不及等待context切换的时间,那就只能浪费CPU资源在那儿轮询了。
不过说实话,大部分情况你都不会直接用到空转锁,其他锁在申请不到加锁时也是会空转一定时间的,如果连这段时间都无法满足你的请求,那要么就是你扔的线程太多,或者你的临界区没你想象的那么短。
Condition Variables 条件变量
pthread_join解决的是多个线程等待同一个线程的结束。条件变量能在合适的时候唤醒正在等待的线程。具体什么时候合适由你自己决定。它必须要跟互斥锁联合起来用。原因我会在注意事项里面讲。
场景:B线程和A线程之间有合作关系,当A线程完成某件事情之前,B线程会等待。当A线程完成某件事情之后,需要让B线程知道,然后B线程从等待状态中被唤醒,然后继续做自己要做的事情。
如果不用条件变量的话,也行。那就是搞个volatile变量,然后让其他线程不断轮询,一旦这个变量到了某个值,你就可以让线程继续了。如果有多个线程需要修改这个变量,那就再加个互斥锁或者读写锁。
但是!!!这做法太特么愚蠢了,还特别浪费CPU时间,所以还在用volatile变量标记线程状态的你们也真是够了!!!
大致的实现原理是:一个条件变量背后有一个池子,所有需要wait这个变量的线程都会进入这个池子。当有线程扔出这个条件变量的signal,系统就会把这个池子里面的线程挨个唤醒。
相关宏和函数
PTHREAD_COND_INITIALIZER int pthread_cond_init(pthread_cond_t *restrict cond, const pthread_condattr_t *restrict attr); int pthread_cond_destroy(pthread_cond_t *cond); int pthread_cond_signal(pthread_cond_t *cond); int pthread_cond_broadcast(pthread_cond_t *cond); int pthread_cond_wait(pthread_cond_t *restrict cond, pthread_mutex_t *restrict mutex); int pthread_cond_timedwait(pthread_cond_t *restrict cond, pthread_mutex_t *restrict mutex, const struct timespec *restrict abstime);
补充一下,原则上
pthread_cond_signal是只通知一个线程,
pthread_cond_broadcast是用于通知很多线程。但POSIX标准也允许让
pthread_cond_signal用于通知多个线程,不强制要求只允许通知一个线程。具体看各系统的实现。一般我都是用
pthread_cond_broadcast。
另外,在调用
pthread_cond_wait之前,必须要申请互斥锁,当线程通过
pthread_cond_wait进入waiting状态时,会释放传入的互斥锁。
下面我先给一个条件变量的使用例子,然后再讲需要注意的点。
void thread_waiting_for_condition_signal ()
{
pthread_mutex_lock(&mutex);
while (operation_queue == NULL) {
pthread_cond_wait(&condition_variable_signal, &mutex);
}
/*********************************/
/* 做一些关于operation_queue的事 */
/*********************************/
pthread_mutex_unlock(&mutex);
}
void thread_prepare_queue ()
{
pthread_mutex_lock(&mutex);
/*********************************/
/* 做一些关于operation_queue的事 */
/*********************************/
pthread_cond_signal(&condition_variable_signal); // 事情做完了之后要扔信号给等待的线程告诉他们做完了
pthread_mutex_unlock(&mutex);
/**************************/
/* 这里可以做一些别的事情 */
/**************************/
...
pthread_exit((void *) 0);
}
要注意的地方
一定要跟mutex配合使用
void thread_function_1 ()
{
done = 1;
pthread_cond_signal(&condition_variable_signal);
}
void thread_function_2 ()
{
while (done == 0) {
pthread_cond_wait(&condition_variable_signal, NULL);
}
}这样行不行?当然不行。为什么不行?
这里涉及一个非常精巧的情况:在
thread_function_2发现done=0的时候,准备要进行下一步的wait操作。在具体开始下一步的wait操作之前,
thread_function_1一口气完成了设置done,发送信号的事情。嗯,
thread_function_2还没来得及waiting呢,
thread_function_1就把信号发出去了,也没人接收这信号,
thread_function_2继续执行waiting之后,就只能等待多戈了。
一定要检测你要操作的内容
void thread_function_1 ()
{
pthread_mutex_lock(&mutex);
...
operation_queue = create_operation_queue();
...
pthread_cond_signal(&condition_variable_signal);
pthread_mutex_unlock(&mutex);
}
void thread_function_2 ()
{
pthread_mutex_lock(&mutex);
...
pthread_cond_wait(&condition_variable_signal, &mutex);
...
pthread_mutex_unlock(&mutex);
}这样行不行?当然不行。为什么不行?
比如
thread_function_1一下子就跑完了,operation_queue也初始化好了,信号也扔出去了。这时候
thread_function_2刚刚启动,由于它没有去先看一下operation_queue是否可用,直接就进入waiting状态。然而事实是operation_queue早已搞定,再也不会有人扔
我已经搞定operation_queue啦的信号,
thread_function_2也不知道operation_queue已经好了,就只能一直在那儿等待多戈了...
一定要用while来检测你要操作的内容而不是if
void thread_function_1 ()
{
pthread_mutex_lock(&mutex);
done = 1;
pthread_cond_signal(&condition_variable_signal);
pthread_mutex_unlock(&mutex);
}
void thread_function_2 ()
{
pthread_mutex_lock(&mutex);
if (done == 0) {
pthread_cond_wait(&condition_variable_signal, &mutex);
}
pthread_mutex_unlock(&mutex);
}这样行不行?大多数情况行,但是用while更加安全。
如果有别人写一个线程去把这个done搞成0了,期间没有申请mutex锁。
那么这时用if去判断的话,由于线程已经从wait状态唤醒,它会直接做下面的事情,而全然不知done的值已经变了。
如果这时用while去判断的话,在
pthread_cond_wait解除wait状态之后,会再去while那边判断一次done的值,只有这次done的值对了,才不会进入wait。如果这期间done被别的不长眼的线程给改了,while补充的那一次判断就帮了你一把,能继续进入waiting。
不过这解决不了根本问题哈,如果那个不长眼的线程在while的第二次判断之后改了done,那还是要悲剧。根本方案还是要在改done的时候加mutex锁。
总而言之,用if也可以,毕竟不太容易出现不长眼的线程改done变量不申请加mutex锁的。用while的话就多了一次判断,安全了一点,即便有不长眼的线程干了这么龌龊的事情,也还能hold住。
扔信号的时候,在临界区里面扔,不要在临界区外扔
void thread_function_1 ()
{
pthread_mutex_lock(&mutex);
done = 1;
pthread_mutex_unlock(&mutex);
pthread_cond_signal(&condition_variable_signal);
}
void thread_function_2 ()
{
pthread_mutex_lock(&mutex);
if (done == 0) {
pthread_cond_wait(&condition_variable_signal, &mutex);
}
pthread_mutex_unlock(&mutex);
}这样行不行?当然不行。为什么不行?《Advanced Programming in the UNIX Enviroment 3 Edtion》这本书里也把扔信号的事儿放在临界区外面了呢。
插播:
(此处张扬同学指出《APUE》在这里有一段论述,在这里我把这段摘下来)
《APUE》中关于这个问题是这么描述的:
When we put a message on the work queue, we need to hold the mutex, but we don’t need to hold the mutex when we signal the waiting threads. As long as it is okay for a thread to pull the message off the queue before
we call cond_signal, we can do this after releasing the mutex.
在临界区外扔signal这种做法需要满足一些前提,这种做法不属于一种普适做法。所以我认为在制定编程规范的时候,应该禁止这种做法。在这份资料的第5页也对这个问题有一段小的论证。它的建议也是
ALWAYS HOLD THE LOCK WHILE SIGNALING。
上面提到的资料的原文如下:
TIP: ALWAYS HOLD THE LOCK WHILE SIGNALING Although it is strictly not necessary in all cases, it is likely simplest and best to hold the lock while signaling when using condition variables. The example above shows a case where you must hold the lock for correctness; however, there are some other cases where it is likely OK not to, but probably is something you should avoid. Thus, for simplicity, hold the lock when calling signal. The converse of this tip, i.e., hold the lock when calling wait, is not just a tip, but rather mandated by the semantics of wait, because wait always (a) assumes the lock is held when you call it, (b) releases said lock when putting the caller to sleep, and (c) re-acquires the lock just before returning. Thus, the generalization of this tip is correct: hold the lock when calling signal or wait, and you will always be in good shape.
插播结束
不行就是不行,哪怕是圣经上这么写,也不行。哼。
就应该永远都在临界区里面扔条件信号,我画了一个高清图来解释这个事情,图比较大,可能要加载一段时间:
看到了吧,1的情况就是在临界区外扔信号的坏处。由于在临界区外,其他线程要申请加mutex锁是可以成功的,然后这个线程要是改了你的敏感数据,你就只能去哭了...

相关文章推荐
- Python3写爬虫(四)多线程实现数据爬取
- C#实现多线程的同步方法实例分析
- 浅谈chuck-lua中的多线程
- C#简单多线程同步和优先权用法实例
- C#多线程学习之(四)使用线程池进行多线程的自动管理
- C#多线程编程中的锁系统(三)
- 解析C#多线程编程中异步多线程的实现及线程池的使用
- C#多线程学习之(六)互斥对象用法实例
- 基于一个应用程序多线程误用的分析详解
- C#多线程学习之(三)生产者和消费者用法分析
- C#多线程学习之(一)多线程的相关概念分析
- C#多线程之Thread中Thread.IsAlive属性用法分析
- 分享我在工作中遇到的多线程下导致RCW无法释放的问题
- C#多线程编程之使用ReaderWriterLock类实现多用户读与单用户写同步的方法
- C#多线程传递参数及任务用法示例
- C#控制台下测试多线程的方法
- 21天学习android开发教程之SurfaceView与多线程的混搭
- Ruby 多线程的潜力和弱点分析
- C#中WPF使用多线程调用窗体组件的方法
- C#如何对多线程、多任务管理(demo)