CUDA并行算法系列之规约
2016-06-15 19:34
369 查看
CUDA并行算法系列之规约
前言
规约是一类并行算法,对传入的N个数据,使用一个二元的符合结合律的操作符⊕,生成1个结果。这类操作包括取最小、取最大、求和、平方和、逻辑与/或、向量点积。规约也是其他高级算法中重要的基础算法。除非操作符⊕的求解代价极高,否则规约倾向于带宽受限型任务(bandwidthbound)。本文将介绍几种规约算法的实现,从两遍规约、block的线程数必须为2的幂,一步一步优化到单遍规约、任意线程数的规约实现,还将讨论讨论基于C++模板的优化。
规约
对于N个输入数据和操作符+,规约可表示为: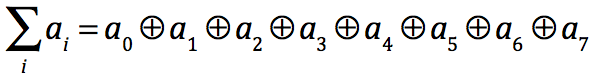
下图展示了一些处理8个元素规约操作的实现:
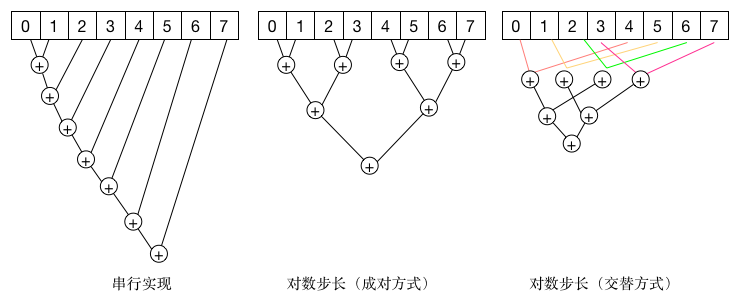
从图中可以看到,不同的实现其时间复杂度也是不一样的,其中串行实现完成计算需要7步,性能比较差。成对的方式是典型的分治思想,只需要lgN步来计算结果,由于不能合并内存事务,这种实现在CUDA中性能较差。
在CUDA中,无论是对全局内存还是共享内存,基于交替策略效果更好。对于全局内存,使用blockDim.x*gridDim.x的倍数作为交替因子有良好的性能,因为所有的内存事务将被合并。对于共享内存,最好的性能是按照所确定的交错因子来累计部分结果,以避免存储片冲突,并保持线程块的相邻线程处于活跃状态。
两遍规约
该算法包含两个阶段,并且两个阶段调用同一个内核。第一阶段内核执行NumBlocks个并行规约,其中NumBlocks是指线程块数,得到一个中间结果数组。第二个阶段通过调用一个线程块对这个中间数组进行规约,从而得到最终结果。改算法的执行如下图所示: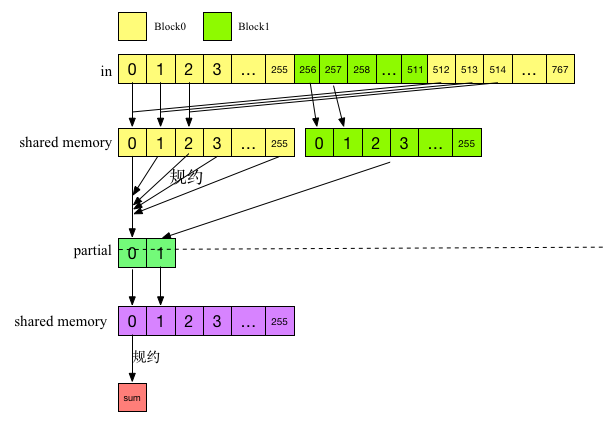
假设有对768个输入数据进行规约,NumBlocks=256,第一阶段使用2个Block进行规约,此时内核执行两个并行规约,并把结果保存在中间数组
partial中,其中
partial的大小为2,partial[0]保存线程块0的规约结果,partial1保存线程块1的结果。第二阶段对parital进行规约,此时内核值启动一个Block,因此,最终得到一个规约结果,这个结果就是对输入数据的规约结果。
规约算法采用了交替策略,两遍规约的代码如下:
// 两遍规约
__global__ void reduction1_kernel(int *out, const int *in, size_t N)
{
// lenght = threads (BlockDim.x)
extern __shared__ int sPartials[];
int sum = 0;
const int tid = threadIdx.x;
for (size_t i = blockIdx.x * blockDim.x + tid; i < N; i += blockDim.x * gridDim.x)
{
sum += in[i];
}
sPartials[tid] = sum;
__syncthreads();
for (int activeTrheads = blockDim.x / 2; activeTrheads > 0; activeTrheads /= 2)
{
if (tid < activeTrheads)
{
sPartials[tid] += sPartials[tid + activeTrheads];
}
__syncthreads();
}
if (tid == 0)
{
out[blockIdx.x] = sPartials[0];
}
}
void reduction1(int *answer, int *partial, const int *in, const size_t N, const int numBlocks, int numThreads)
{
unsigned int sharedSize = numThreads * sizeof(int);
// kernel execution
reduction1_kernel<<<numBlocks, numThreads, sharedSize>>>(partial, in, N);
reduction1_kernel<<<1, numThreads, sharedSize>>>(answer, partial, numBlocks);
}共享内存的大小等于线程块的线程数量,在启动的时候指定。同时要注意,该内核块的线程数量必须是2的幂次,在下文,将介绍如何使用任意大小的数据。
CUDA会把线程组成线程束warp(目前是32个线程),warp的执行由SIMD硬件完成,每个线程块中的线程束是按照锁步方式(lockstep)执行每条指令的,因此当线程块中活动线程数低于硬件线程束的大小时,可以无须再调用__syncthreads()来同步。不过需要注意,编写线程束同步代码时,必须对共享内存的指针使用volatile关键字修饰,否则可能会由于编译器的优化行为改变内存的操作顺序从而使结果不正确。采用线程束优化的代码如下:
// 两遍规约
__global__ void reduction1_kernel(int *out, const int *in, size_t N)
{
// lenght = threads (BlockDim.x)
extern __shared__ int sPartials[];
int sum = 0;
const int tid = threadIdx.x;
for (size_t i = blockIdx.x * blockDim.x + tid; i < N; i += blockDim.x * gridDim.x)
{
sum += in[i];
}
sPartials[tid] = sum;
__syncthreads();
for (int activeTrheads = blockDim.x / 2; activeTrheads > 32; activeTrheads /= 2)
{
if (tid < activeTrheads)
{
sPartials[tid] += sPartials[tid + activeTrheads];
}
__syncthreads();
}
// 线程束同步
if (tid < 32)
{
volatile int *wsSum = sPartials;
if (blockDim.x > 32)
{
wsSum[tid] += wsSum[tid + 32];
}
wsSum[tid] += wsSum[tid + 16];
wsSum[tid] += wsSum[tid + 8];
wsSum[tid] += wsSum[tid + 4];
wsSum[tid] += wsSum[tid + 2];
wsSum[tid] += wsSum[tid + 1];
if (tid == 0)
{
out[blockIdx.x] = wsSum[0];
}
}
}通过把线程数变成一个模板参数,还可以把for循环展开进一步优化,展开后的代码如下:
// 两遍规约
template<unsigned int numThreads>
__global__ void reduction1_kernel(int *out, const int *in, size_t N)
{
// lenght = threads (BlockDim.x)
extern __shared__ int sPartials[];
int sum = 0;
const int tid = threadIdx.x;
for (size_t i = blockIdx.x * numThreads+ tid; i < N; i += numThreads * gridDim.x)
{
sum += in[i];
}
sPartials[tid] = sum;
__syncthreads();
if (numThreads >= 1024)
{
if (tid < 512) sPartials[tid] += sPartials[tid + 512];
__syncthreads();
}
if (numThreads >= 512)
{
if (tid < 256) sPartials[tid] += sPartials[tid + 256];
__syncthreads();
}
if (numThreads >= 256)
{
if (tid < 128) sPartials[tid] += sPartials[tid + 128];
__syncthreads();
}
if (numThreads >= 128)
{
if (tid < 64) sPartials[tid] += sPartials[tid + 64];
__syncthreads();
}
if (tid < 32)
{
volatile int *wsSum = sPartials;
if (numThreads >= 64) wsSum[tid] += wsSum[tid + 32];
if (numThreads >= 32) wsSum[tid] += wsSum[tid + 16];
if (numThreads >= 16) wsSum[tid] += wsSum[tid + 8];
if (numThreads >= 8) wsSum[tid] += wsSum[tid + 4];
if (numThreads >= 4) wsSum[tid] += wsSum[tid + 2];
if (numThreads >= 2) wsSum[tid] += wsSum[tid + 1];
if (tid == 0)
{
out[blockIdx.x] = wsSum[0];
}
}
}为了实例化模板,需要另外一个函数来调用:
template<unsigned int numThreads>
void reduction1_template(int *answer, int *partial, const int *in, const size_t N, const int numBlocks)
{
unsigned int sharedSize = numThreads * sizeof(int);
// kernel execution
reduction1_kernel<numThreads><<<numBlocks, numThreads, sharedSize>>>(partial, in, N);
reduction1_kernel<numThreads><<<1, numThreads, sharedSize>>>(answer, partial, numBlocks);
}
void reduction1t(int *answer, int *partial, const int *in, const size_t N, const int numBlocks, int numThreads)
{
switch (numThreads)
{
case 1: reduction1_template<1>(answer, partial, in, N, numBlocks); break;
case 2: reduction1_template<2>(answer, partial, in, N, numBlocks); break;
case 4: reduction1_template<4>(answer, partial, in, N, numBlocks); break;
case 8: reduction1_template<8>(answer, partial, in, N, numBlocks); break;
case 16: reduction1_template<16>(answer, partial, in, N, numBlocks); break;
case 32: reduction1_template<32>(answer, partial, in, N, numBlocks); break;
case 64: reduction1_template<64>(answer, partial, in, N, numBlocks); break;
case 128: reduction1_template<128>(answer, partial, in, N, numBlocks); break;
case 256: reduction1_template<256>(answer, partial, in, N, numBlocks); break;
case 512: reduction1_template<512>(answer, partial, in, N, numBlocks); break;
case 1024: reduction1_template<1024>(answer, partial, in, N, numBlocks); break;
}
}任意线程块大小的规约
前面的内核块的线程数量必须是2的幂次,否则计算结果是不正确的,下面把它修改成适应任意大小的数据。其实只需在循环之前把待规约的数组(shared memory 中的sPartials)调整成2的幂次即可,如下图所示: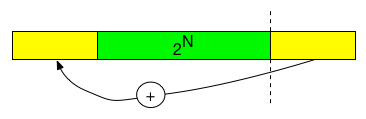
类似于向下取整,对于非
2^n长度的数组(L),取小于L的最大的
2^n的数(floorPow2),把后面的是数据使用⊕操作把中间结果保存在
index-floorPow2中,其中index是数据原来的索引。
当
N & (N - 1)=0时,N为2的幂词,否则继续计算
N &= (N - 1),知道
N & (N - 1)=0,此时N即为floorPow2。
修改后的两遍规约代码如下:
// 两遍规约
__global__ void reduction1_kernel(int *out, const int *in, size_t N)
{
// lenght = threads (BlockDim.x)
extern __shared__ int sPartials[];
int sum = 0;
const int tid = threadIdx.x;
for (size_t i = blockIdx.x * blockDim.x + tid; i < N; i += blockDim.x * gridDim.x)
{
sum += in[i];
}
sPartials[tid] = sum;
__syncthreads();
// 调整为2^n
unsigned int floowPow2 = blockDim.x;
if (floowPow2 & (floowPow2 - 1))
{
while(floowPow2 & (floowPow2 - 1))
{
floowPow2 &= (floowPow2 - 1);
}
if (tid >= floowPow2)
{
sPartials[tid - floowPow2] += sPartials[tid];
}
__syncthreads();
}
for (int activeTrheads = floowPow2 / 2; activeTrheads > 32; activeTrheads /= 2)
{
if (tid < activeTrheads)
{
sPartials[tid] += sPartials[tid + activeTrheads];
}
__syncthreads();
}
if (tid < 32)
{
volatile int *wsSum = sPartials;
if (floowPow2 > 32)
{
wsSum[tid] += wsSum[tid + 32];
}
if (floowPow2 > 16) wsSum[tid] += wsSum[tid + 16];
if (floowPow2 > 8) wsSum[tid] += wsSum[tid + 8];
if (floowPow2 > 4) wsSum[tid] += wsSum[tid + 4];
if (floowPow2 > 2) wsSum[tid] += wsSum[tid + 2];
if (floowPow2 > 1) wsSum[tid] += wsSum[tid + 1];
if (tid == 0)
{
volatile int *wsSum = sPartials;
out[blockIdx.x] = wsSum[0];
}
}
}
void reduction1(int *answer, int *partial, const int *in, const size_t N, const int numBlocks, int numThreads)
{
unsigned int sharedSize = numThreads * sizeof(int);
// kernel execution
reduction1_kernel<<<numBlocks, numThreads, sharedSize>>>(partial, in, N);
reduction1_kernel<<<1, numThreads, sharedSize>>>(answer, partial, numBlocks);
}当然,对于循环展开的代码也是一样的:
template<unsigned int numThreads>
__global__ void reduction1_kernel(int *out, const int *in, size_t N)
{
// lenght = threads (BlockDim.x)
extern __shared__ int sPartials[];
int sum = 0;
const int tid = threadIdx.x;
for (size_t i = blockIdx.x * numThreads+ tid; i < N; i += numThreads * gridDim.x)
{
sum += in[i];
}
sPartials[tid] = sum;
__syncthreads();
// 调整为2^n
unsigned int floorPow2 = blockDim.x;
if (floorPow2 & (floorPow2 - 1))
{
while(floorPow2 & (floorPow2 - 1))
{
floorPow2 &= (floorPow2 - 1);
}
if (tid >= floorPow2)
{
sPartials[tid - floorPow2] += sPartials[tid];
}
__syncthreads();
}
if (floorPow2 >= 1024)
{
if (tid < 512) sPartials[tid] += sPartials[tid + 512];
__syncthreads();
}
if (floorPow2 >= 512)
{
if (tid < 256) sPartials[tid] += sPartials[tid + 256];
__syncthreads();
}
if (floorPow2 >= 256)
{
if (tid < 128) sPartials[tid] += sPartials[tid + 128];
__syncthreads();
}
if (floorPow2 >= 128)
{
if (tid < 64) sPartials[tid] += sPartials[tid + 64];
__syncthreads();
}
if (tid < 32)
{
volatile int *wsSum = sPartials;
if (floorPow2 >= 64) wsSum[tid] += wsSum[tid + 32];
if (floorPow2 >= 32) wsSum[tid] += wsSum[tid + 16];
if (floorPow2 >= 16) wsSum[tid] += wsSum[tid + 8];
if (floorPow2 >= 8) wsSum[tid] += wsSum[tid + 4];
if (floorPow2 >= 4) wsSum[tid] += wsSum[tid + 2];
if (floorPow2 >= 2) wsSum[tid] += wsSum[tid + 1];
if (tid == 0)
{
volatile int *wsSum = sPartials;
out[blockIdx.x] = wsSum[0];
}
}
}基于原子操作的单遍规约
上面的代码需要启动两次内核,当然,由于CPU和GPU是异步执行,其实效率也是很高的。下面来介绍单遍规约,两遍规约的做法主要针对CUDA线程块无法同步这一问题的解决方法,使用原子操作和共享内存的组合可以避免第二个内核的调用。如果硬件支持操作符⊕的原子操作,那么单遍规约操作就可以变得很简单,比如对于加法操作,只需调用atomicAdd()把块中的部分结果加到全局内存中即可,代码如下:
__global__ void reduction2_kernel(int *out, const int *in, size_t N)
{
extern __shared__ int sPartials[];
int sum = 0;
const int tid = threadIdx.x;
for (size_t i = blockIdx.x * blockDim.x + tid; i < N; i += blockDim.x * gridDim.x)
{
sum += in[i];
}
atomicAdd(out, sum);
}
void reduction2(int *answer, int *partial, const int *in, const size_t N, const int numBlocks, int numThreads)
{
unsigned int sharedSize = numThreads * sizeof(int);
cudaMemset(answer, 0, sizeof(int));
reduction2_kernel<<<numBlocks, numThreads, sharedSize>>>(answer, in, N);
}当然,为了减少全局内存的写操作和原子操作的竞争,可以进行一些优化,在块中先进行规约操作得到部分结果,再把这个部分结果使用原子操作加到全局内存中,这样每个块只需一次全局内存写操作和原子操作,内核代码如下:
__global__ void reduction2_kernel(int *out, const int *in, size_t N)
{
extern __shared__ int sPartials[];
int sum = 0;
const int tid = threadIdx.x;
for (size_t i = blockIdx.x * blockDim.x + tid; i < N; i += blockDim.x * gridDim.x)
{
sum += in[i];
}
sPartials[tid] = sum;
__syncthreads();
unsigned int floorPow2 = blockDim.x;
if (floorPow2 & (floorPow2 - 1))
{
while(floorPow2 & (floorPow2 - 1))
{
floorPow2 &= (floorPow2 - 1);
}
if (tid >= floorPow2)
{
sPartials[tid - floorPow2] += sPartials[tid];
}
__syncthreads();
}
for (int activeTrheads = floorPow2 / 2; activeTrheads > 32; activeTrheads /= 2)
{
if (tid < activeTrheads)
{
sPartials[tid] += sPartials[tid + activeTrheads];
}
__syncthreads();
}
if (tid < 32)
{
volatile int *wsSum = sPartials;
if (floorPow2 > 32) wsSum[tid] += wsSum[tid + 32];
if (floorPow2 > 16) wsSum[tid] += wsSum[tid + 16];
if (floorPow2 > 8) wsSum[tid] += wsSum[tid + 8];
if (floorPow2 > 4) wsSum[tid] += wsSum[tid + 4];
if (floorPow2 > 2) wsSum[tid] += wsSum[tid + 2];
if (floorPow2 > 1) wsSum[tid] += wsSum[tid + 1];
if (tid == 0)
{
atomicAdd(out, wsSum[0]);
}
}
}非原子操作的单遍规约
对于不支持原子操作的单遍规约就要复杂一些,需要使用一个设备内存(全局内存)位置跟踪哪个线程块已经写完了自己的部分,一旦所有的块都完成后,使用一个快进行最后的规约,将结果写回。由于需要多次执行对共享内存的数据进行规约,因此把上面的规约代码单独提取出来作为一个设备函数,以便重用。reduction3_logStepShared()函数,对来自共享内存的sPartials执行规约操作,规约结果写会由out指定的内存,代码如下(这段代码也可以使用模板展开for循环):
__device__ void reduction3_logStepShared(int *out, volatile int *sPartials)
{
const int tid = threadIdx.x;
int floorPow2 = blockDim.x;
if (floorPow2 & (floorPow2 - 1))
{
while (floorPow2 & (floorPow2 - 1))
{
floorPow2 &= (floorPow2 - 1);
}
if (tid >= floorPow2)
{
sPartials[tid - floorPow2] += sPartials[tid];
}
__syncthreads();
}
for (int activeTrheads = floorPow2 / 2; activeTrheads > 32; activeTrheads /= 2)
{
if (tid < activeTrheads)
{
sPartials[tid] += sPartials[tid + activeTrheads];
}
__syncthreads();
}
if (tid < 32)
{
if (floorPow2 > 32) sPartials[tid] += sPartials[tid + 32];
if (floorPow2 > 16) sPartials[tid] += sPartials[tid + 16];
if (floorPow2 > 8) sPartials[tid] += sPartials[8];
if (floorPow2 > 4) sPartials[tid] += sPartials[4];
if (floorPow2 > 2) sPartials[tid] += sPartials[2];
if (floorPow2 > 1) sPartials[tid] += sPartials[1];
if (tid == 0)
{
*out = sPartials[0];
}
}
}单遍规约的代码如下:
__device__ unsigned int retirementCount = 0;
__global__ void reduction3_kernel(int *out, int *partial, const int *in, size_t N)
{
extern __shared__ int sPartials[];
const int tid = threadIdx.x;
int sum = 0;
for (size_t i = blockIdx.x * blockDim.x + tid; i < N; i += blockDim.x * gridDim.x)
{
sum += in[i];
}
sPartials[tid] = sum;
__syncthreads();
if (gridDim.x == 1)
{
reduction3_logStepShared(out, sPartials);
return;
}
reduction3_logStepShared(&partial[blockIdx.x], sPartials);
__shared__ bool lastBlock;
__threadfence();
if (tid == 0)
{
unsigned int ticket = atomicAdd(&retirementCount, 1);
lastBlock = (ticket == gridDim.x - 1);
}
__syncthreads();
if (lastBlock)
{
sum = 0;
for (size_t i = tid; i < gridDim.x; i += blockDim.x)
{
sum += partial[i];
}
sPartials[tid] = sum;
__syncthreads();
reduction3_logStepShared(out, sPartials);
retirementCount_1 = 0;
}
}
void reduction3(int *answer, int *partial, const int *in, const size_t N, const int numBlocks, int numThreads)
{
unsigned int sharedSize = numThreads * sizeof(int);
reduction3_kernel<<<numBlocks, numThreads, sharedSize>>>(answer, partial, in, N);
}和前面的规约代码类似,内核首先计算部分规约并将结果写入共享内存。一旦完成上述操作,接下来需要分两种情况讨论:1个Block和多个Block。
1个Block时不存在Block间同步的问题,直接调用reduction3_logStepShared()就得到了最终规约结果。
多个Block时情况要复杂,由于Block间无法直接通信,使用一个全局内存上的变量retirementCount来记录线程块的执行情况,每个Block的0号线程调用atomicAdd()函数对retirementCount进行加1操作,atomicAdd()会返回操作前的值,最后一个Block会把lastBlock设为真,在最后一个线程块中对所有块的部分规约结果再次规约,得到最终规约结果。
该内核代码调用了__threadfence()函数,该函数会导致所有的块都等待,直到任何挂起的内存事务已写回到设备内存。当__threadfence()执行时,写入全局内存的操作不仅仅可见于被调用线程或者线程块,而是所有线程。
测试
thrust就包含了规约操作,因此可以使用thrust来验证计算结果的正确性,同时使用事件来记录运行的时间,测试其性能,测试代码如下:cudaEvent_t start, stop;
checkCudaErrors( cudaEventCreate(&start) );
checkCudaErrors( cudaEventCreate(&stop) );
cudaEventRecord(start);
for (int i = 0; i < cIterations; ++i)
{
func(answer, partial, in, N, numBlocks, numThreads);
}
cudaEventRecord(stop);
checkCudaErrors( cudaThreadSynchronize() );
float time = 0;
cudaEventElapsedTime(&time, start, stop);完整的代码可以在GitHub上找到:algorithms-cuda。
测试结果
使用1024*1024的数据分别在一下两个测试环境中进行测试,每个内核执行100次,测试结果如下:测试环境1
| GPU | GeForce GT 750M |
|---|---|
| CUDA | v7.5 |
| OS | Mac OS 10.11.5 |
blocks: 1024 threads: 1024 simple loop time: 253.916ms host answer (1048576) = device answer (1048576) simple loop template time: 144.405ms host answer (1048576) = device answer (1048576) atomicAdd time: 132.541ms host answer (1048576) = device answer (1048576) atomicAdd template time: 115.428ms host answer (1048576) = device answer (1048576) single pass time: 1724.43ms host answer (1048576) = device answer (1048576) single pass template time: 1190.27ms host answer (1048576) = device answer (1048576)
测试环境2
| GPU | GeForce GTX 750 Ti |
|---|---|
| CUDA | v7.5 |
| OS | Ubuntu 14.04 |
blocks: 1024 threads: 1024 simple loop time: 28.8353ms host answer (1048576) = device answer (1048576) simple loop template time: 30.3201ms host answer (1048576) = device answer (1048576) atomicAdd time: 29.7131ms host answer (1048576) = device answer (1048576) atomicAdd template time: 29.4682ms host answer (1048576) = device answer (1048576) single pass time: 39.1131ms host answer (1048576) = device answer (1048576) single pass template time: 33.0042ms host answer (1048576) = device answer (1048576)
结语
本文介绍了基于CUDA的规约算法,分别实现了两遍规约、基于原子操作的单遍规约和非原子操作的单遍规约,同时也讨论了基于模板的循环展开和适应任意数据大小的方法。最后给出了测试代码并在两个测试环境中进行了测试。从测试结果了可以看出,基于模板的循环展开优化对于GT 750M具有较好的优化效果,而对于GTX 750 Ti的性能提升不大。受限于__threadfence()和原子操作的性能,单遍规约在这两款GPU下都没有得到性能提升,不过在GT 750M下,如果不执行__threadfence(),性能将得到极大的提升(从1724.43ms到143.424ms)。在高端GPU下,单遍规约应该会比两遍规约效率更高,目前没有设备测试,等测试后再更新。
本文的代码可以在GitHub上找到:algorithms-cuda。
参考文献
NICHOLAS WILT[美]. CUDA专家手册--GPU编程权威指南(高性能计算机系列丛书)[M]. 机械工业出版社, 2014.Kirk D B, Wen-mei W H. Programming massively parallel processors: a hands-on approach[M]. Newnes, 2012.
thrust. https://github.com/thrust/thrust/tree/master/thrust

相关文章推荐
- 多线程更新UI的常用方法
- 关于USB的8个问题
- APACHE默认模块功能说明
- iOS学习之UINavigationController详解与使用(一)添加UIBarButtonItem
- 飛飛(六十九)好玩好玩好玩
- 实现复数类中的运算符重载2
- malloc内存分配过程详解
- make menuconfig显示错误“Your display is too small to run Menuconfig!”
- 如何把一张照片用 Photoshop 做成动画背景效果?
- how to access and operate a binarry file ?
- 第十三周上机实践项目:定义日期变量,进行年、月、日的输入,计算该日期是本年中的第几天。
- HoloLens开发手记 - Unity之Persistence 场景保持
- C函数tolower,与toupper
- com.google.gson.JsonSyntaxException: java.lang.NumberFormatException: For input string:
- 实现复数类中的运算符重载
- 实现复数类中的运算符重载
- 学期末 软件工程课 总结
- jdk自带监控工具整理-jstack
- 《简历怎么写》视频总结
- ROS_Kinetic_17 使用V-Rep3.3.1(vrep_ros_bridge)