CNN中的卷积操作
2016-06-15 16:43
260 查看
CNN中的卷积
很多文章都介绍过卷积的操作:用一个小的卷积核在图像上滑动,每次滑动计算出一个值,比如用3*3的卷积核卷积一个5*5的矩阵(不考虑扩展边缘),过程如下: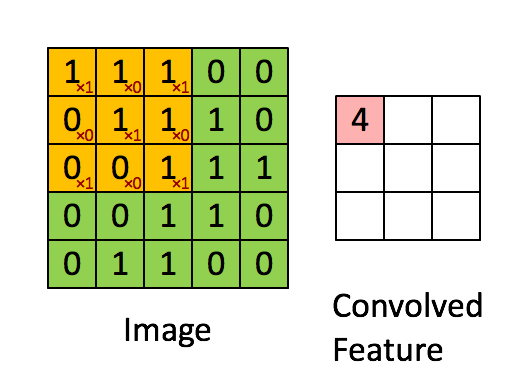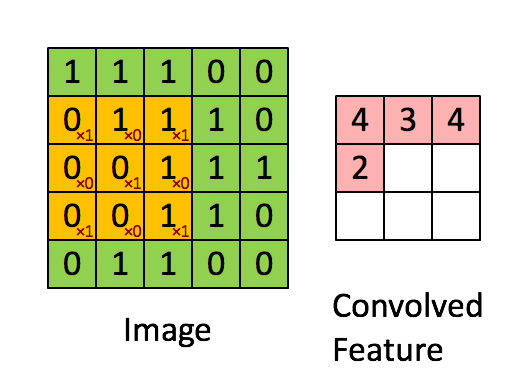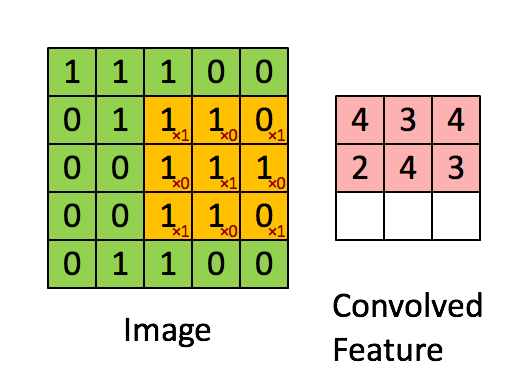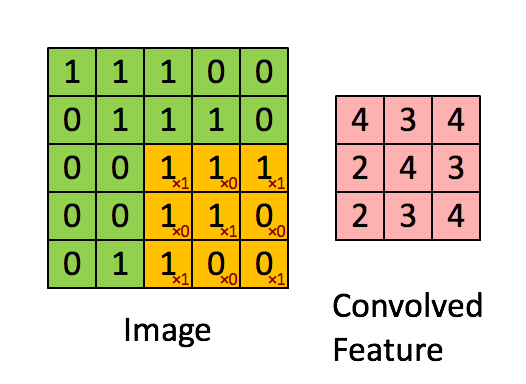
卷积操作在二维平面上很好理解,但是在CNN中,被卷积的矩阵是有深度的:

这个深度可以类比三通道的RGB图像想象。所以被卷积的矩阵的维度是
depth*height*width,那么针对这样的矩阵,卷积操作是如何进行的呢?一次卷积涉及到的参数量又是多少呢?
斯坦福的教程里说:
Every filter is small spatially (along width and height), but extends through the full depth of the input volume.
大致意思就是,每次卷积的操作是在“一小块儿面积,但是全部深度”上进行的。假如这一层输入的维度是32*32*3,卷积核的维度是5*5*3(这里,5*5两个维度可以随意设计,但是3是固定的,因为输入数据的第三维度的值是3),那么得到的输入应该是28*28*1的。问题来了,怎么把立体的卷积成平面了呢?
上边的操作只使用了一个卷积核,如果使用多个卷积核呢,比如12个?那得到的输入就是立体的了28*28*12。没错,CNN中就是这么操作的,但是请注意两个名词
局部连接和
权值共享,关于这两个词有很多解释,这里不再赘述。
然后来计算一下参数量
还是上边的例子:32*32*3的输入,5*5*3的卷积核,需要的参数个数是5*5*3=75.
该层使用12个卷积核的话,总参数个数(没有算偏置项)5*5*3*12=900.
可以看一下caffe中conv的源码:
template <typename Dtype>
void ConvolutionLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* weight = this->blobs_[0]->cpu_data();
for (int i = 0; i < bottom.size(); ++i) {
const Dtype* bottom_data = bottom[i]->cpu_data();
Dtype* top_data = top[i]->mutable_cpu_data();
for (int n = 0; n < this->num_; ++n) {
this->forward_cpu_gemm(bottom_data + n * this->bottom_dim_, weight,
top_data + n * this->top_dim_);
if (this->bias_term_) {
const Dtype* bias = this->blobs_[1]->cpu_data();
this->forward_cpu_bias(top_data + n * this->top_dim_, bias);
}
}
}
}上边调用的
forward_cpu_gemm也贴过来:
template <typename Dtype>
void BaseConvolutionLayer<Dtype>::forward_cpu_gemm(const Dtype* input,
const Dtype* weights, Dtype* output, bool skip_im2col) {
const Dtype* col_buff = input;
if (!is_1x1_) {
if (!skip_im2col) {
conv_im2col_cpu(input, col_buffer_.mutable_cpu_data());
}
col_buff = col_buffer_.cpu_data();
}
for (int g = 0; g < group_; ++g) {
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, conv_out_channels_ /
group_, conv_out_spatial_dim_, kernel_dim_ / group_,
(Dtype)1., weights + weight_offset_ * g, col_buff + col_offset_ * g,
(Dtype)0., output + output_offset_ * g);
}
}conv_im2col_cpu:贴过来:
template <typename Dtype>
void im2col_cpu(const Dtype* data_im, const int channels,
const int height, const int width, const int kernel_h, const int kernel_w,
const int pad_h, const int pad_w,
const int stride_h, const int stride_w,
Dtype* data_col) {
int height_col = (height + 2 * pad_h - kernel_h) / stride_h + 1;
int width_col = (width + 2 * pad_w - kernel_w) / stride_w + 1;
int channels_col = channels * kernel_h * kernel_w;
for (int c = 0; c < channels_col; ++c) {
int w_offset = c % kernel_w;
int h_offset = (c / kernel_w) % kernel_h;
int c_im = c / kernel_h / kernel_w;
for (int h = 0; h < height_col; ++h) {
for (int w = 0; w < width_col; ++w) {
int h_pad = h * stride_h - pad_h + h_offset;
int w_pad = w * stride_w - pad_w + w_offset;
if (h_pad >= 0 && h_pad < height && w_pad >= 0 && w_pad < width)
data_col[(c * height_col + h) * width_col + w] =
data_im[(c_im * height + h_pad) * width + w_pad];
else
data_col[(c * height_col + h) * width_col + w] = 0;
}
}
}
}`caffe_cpu_gemm“贴过来:
template<>
void caffe_cpu_gemm<double>(const CBLAS_TRANSPOSE TransA,
const CBLAS_TRANSPOSE TransB, const int M, const int N, const int K,
const double alpha, const double* A, const double* B, const double beta,
double* C) {
int lda = (TransA == CblasNoTrans) ? K : M;
int ldb = (TransB == CblasNoTrans) ? N : K;
cblas_dgemm(CblasRowMajor, TransA, TransB, M, N, K, alpha, A, lda, B,
ldb, beta, C, N);
}

相关文章推荐
- CUDA搭建
- 稀疏自动编码器 (Sparse Autoencoder)
- 白化(Whitening):PCA vs. ZCA
- softmax回归
- 卷积神经网络初探
- 深入理解CNN的细节
- TensorFlow人工智能引擎入门教程之九 RNN/LSTM循环神经网络长短期记忆网络使用
- TensorFlow人工智能引擎入门教程之十 最强网络 RSNN深度残差网络 平均准确率96-99%
- TensorFlow人工智能入门教程之十一 最强网络DLSTM 双向长短期记忆网络(阿里小AI实现)
- TensorFlow人工智能入门教程之十四 自动编码机AutoEncoder 网络
- TensorFlow人工智能引擎入门教程所有目录
- 如何用70行代码实现深度神经网络算法
- 近200篇机器学习&深度学习资料分享(含各种文档,视频,源码等)
- 安装caffe过程记录
- DIGITS的安装与使用记录
- 图像识别和图像搜索
- 卷积神经网络
- 深度学习札记
- 51CTO学院优质新课抢先体验-5折好课帮你技能提升、升职加薪