聚类算法之BIRCH(Java实现)转载
2016-06-15 14:56
966 查看
http://www.cnblogs.com/zhangchaoyang/articles/2200800.html
http://blog.csdn.net/qll125596718/article/details/6895291
BIRCH(Balanced Iterative Reducing and Clustering using Hierarchies)天生就是为处理超大规模(至少要让你的内存容不下)的数据集而设计的,它可以在任何给定的内存下运行。关于BIRCH的更多特点先不介绍,我先讲一下算法的完整实现细节,对算法的实现过程搞清楚后再去看别人对该算法的评价才会感受深刻。
你不需要具备B树的相关知识,我接下来会讲得很清楚。
BIRCH算法的过程就是要把待分类的数据插入一棵树中,并且原始数据都在叶子节点上。这棵树看起来是这个样子:

在这棵树中有3种类型的节点:Nonleaf、Leaf、MinCluster,Root可能是一种Nonleaf,也可能是一种Leaf。所有的Leaf放入一个双向链表中。每一个节点都包含一个CF值,CF是一个三元组

,其中data point instance的个数,

和

是与数据点同维度的向量,
是线性和,
是平方和。比如有一个MinCluster里包含3个数据点(1,2,3),(4,5,6),(7,8,9),则
N=3,
=(1+4+7,2+5+8,3+6+9)=(12,15,18),
=(1+16+49,4+25+64,9+36+81)。
就拿这个MinCluster为例,我们可以计算它的
簇中心

簇半径

簇直径

我们还可以计算两个簇之间的距离

,当然你也可以使用D0,D1,D3等等,不过在这里我们使用D2。
有意思的是簇中心、簇半径、簇直径以及两簇之间的距离D0到D3都可以由CF来计算,比如
簇直径

簇间距离

,这里的N,LS和SS是指两簇合并后大簇的N,LS和SS。所谓两簇合并只需要两个对应的CF相加那可
CF1 + CF2 = (N1 + N2 , LS1 + LS2, SS1 + SS2)
每个节点的CF值就是其所有孩子节点CF值之和,以每个节点为根节点的子树都可以看成 是一个簇。
Nonleaf、Leaf、MinCluster都是有大小限制的,Nonleaf的孩子节点不能超过B个,Leaf最多只能有L个MinCluster,而一个MinCluster的直径不能超过T。
算法起初,我们扫描数据库,拿到第一个data point instance--(1,2,3),我们创建一个空的Leaf和MinCluster,把点(1,2,3)的id值放入Mincluster,更新MinCluster的CF值为(1,(1,2,3),(1,4,9)),把MinCluster作为Leaf的一个孩子,更新Leaf的CF值为(1,(1,2,3),(1,4,9))。实际上只要往树中放入一个CF(这里我们用CF作为Nonleaf、Leaf、MinCluster的统称),就要更新从Root到该叶子节点的路径上所有节点的CF值。
当又有一个数据点要插入树中时,把这个点封装为一个MinCluster(这样它就有了一个CF值),把新到的数据点记为CF_new,我们拿到树的根节点的各个孩子节点的CF值,根据D2来找到CF_new与哪个节点最近,就把CF_new加入那个子树上面去。这是一个递归的过程。递归的终止点是要把CF_new加入到一个MinCluster中,如果加入之后MinCluster的直径没有超过T,则直接加入,否则譔CF_new要单独作为一个簇,成为MinCluster的兄弟结点。插入之后注意更新该节点及其所有祖先节点的CF值。
插入新节点后,可能有些节点的孩子数大于了B(或L),此时该节点要分裂。对于Leaf,它现在有L+1个MinCluster,我们要新创建一个Leaf,使它作为原Leaf的兄弟结点,同时注意每新创建一个Leaf都要把它插入到双向链表中。L+1个MinCluster要分到这两个Leaf中,怎么分呢?找出这L+1个MinCluster中距离最远的两个Cluster(根据D2),剩下的Cluster看离哪个近就跟谁站在一起。分好后更新两个Leaf的CF值,其祖先节点的CF值没有变化,不需要更新。这可能导致祖先节点的递归分裂,因为Leaf分裂后恰好其父节点的孩子数超过了B。Nonleaf的分裂方法与Leaf的相似,只不过产生新的Nonleaf后不需要把它放入一个双向链表中。如果是树的根节点要分裂,则树的高度加1。
CF.java
+ View Code
MinCluster.java
+ View Code
TreeNode.java
+ View Code?
NonleafNode.java
+ View Code
LeafNode.java
+ View Code
BIRCH.java
+ View Code
最后我们来总结一BIRCH的优势和劣势。
优点:
节省内在。叶子节点放在磁盘分区上,非叶子节点仅仅是存储了一个CF值,外加指向父节点和孩子节点的指针。
快。合并两个两簇只需要两个CF算术相加即可;计算两个簇的距离只需要用到(N,LS,SS)这三个值足矣。
一遍扫描数据库即可建立B树。
可识别噪声点。建立好B树后把那些包含数据点少的MinCluster当作outlier。
由于B树是高度平衡的,所以在树上进行插入或查找操作很快。
缺点:
结果依赖于数据点的插入顺序。本属于同一个簇的点可能由于插入顺序相差很远而分到不同的簇中,即使同一个点在不同的时刻被插入,也会被分到不同的簇中。
对非球状的簇聚类效果不好。这取决于簇直径和簇间距离的计算方法。
对高维数据聚类效果不好。
由于每个节点只能包含一定数目的子节点,最后得出来的簇可能和自然簇相差很大。
BIRCH适合于处理需要数十上百小时聚类的数据,但在整个过程中算法一旦中断,一切必须从头再来。
局部性也导致了BIRCH的聚类效果欠佳。当一个新点要插入B树时,它只跟很少一部分簇进行了相似性(通过计算簇间距离)比较,高的efficient导致低的effective。
首先解释一下什么是聚类,从统计学的观点来看,聚类就是给定一个包含N个数据点的数据集和一个距离度量函数F(例如计算簇内每两个数据点之间的平均距离的函数),要求将这个数据集划分为K个簇(或者不给出数量K,由算法自动发现最佳的簇数量),最后的结果是找到一种对于数据集的最佳划分,使得距离度量函数F的值最小。从机器学习的角度来看,聚类是一种非监督的学习算法,通过将数据集聚成n个簇,使得簇内点之间距离最小化,簇之间的距离最大化。
BIRCH算法特点:
(1)BIRCH试图利用可用的资源来生成最好的聚类结果,给定有限的主存,一个重要的考虑是最小化I/O时间。
(2)BIRCH采用了一种多阶段聚类技术:数据集的单边扫描产生了一个基本的聚类,一或多遍的额外扫描可以进一步改进聚类质量。
(3)BIRCH是一种增量的聚类方法,因为它对每一个数据点的聚类的决策都是基于当前已经处理过的数据点,而不是基于全局的数据点。
(4)如果簇不是球形的,BIRCH不能很好的工作,因为它用了半径或直径的概念来控制聚类的边界。
BIRCH算法中引入了两个概念:聚类特征和聚类特征树,以下分别介绍。
CF=(N,LS,SS)
其中,N是子类中节点的数目,LS是N个节点的线性和,SS是N个节点的平方和。
CF有个特性,即可以求和,具体说明如下:CF1=(n1,LS1,SS1),CF2=(n2,LS2,SS2),则CF1+CF2=(n1+n2, LS1+LS2, SS1+SS2)。
例如:
假设簇C1中有三个数据点:(2,3),(4,5),(5,6),则CF1={3,(2+4+5,3+5+6),(2^2+4^2+5^2,3^2+5^2+6^2)}={3,(11,14),(45,70)},同样的,簇C2的CF2={4,(40,42),(100,101)},那么,由簇C1和簇C2合并而来的簇C3的聚类特征CF3计算如下:
CF3={3+4,(11+40,14+42),(45+100,70+101)}={7,(51,56),(145,171)}
另外在介绍两个概念:簇的质心和簇的半径。假如一个簇中包含n个数据点:{Xi},i=1,2,3...n.,则质心C和半径R计算公式如下:
C=(X1+X2+...+Xn)/n,(这里X1+X2+...+Xn是向量加)
R=(|X1-C|^2+|X2-C|^2+...+|Xn-C|^2)/n
其中,簇半径表示簇中所有点到簇质心的平均距离。CF中存储的是簇中所有数据点的特性的统计和,所以当我们把一个数据点加入某个簇的时候,那么这个数据点的详细特征,例如属性值,就丢失了,由于这个特征,BIRCH聚类可以在很大程度上对数据集进行压缩。
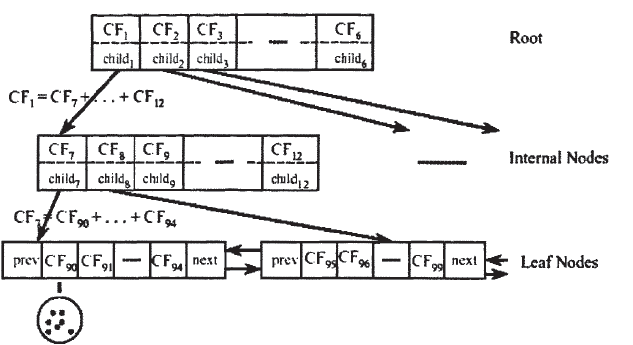
一棵CF树是一个数据集的压缩表示,叶子节点的每一个输入都代表一个簇C,簇C中包含若干个数据点,并且原始数据集中越密集的区域,簇C中包含的数据点越多,越稀疏的区域,簇C中包含的数据点越少,簇C的半径小于等于T。随着数据点的加入,CF树被动态的构建,插入过程有点类似于B-树。加入算法表示如下:
[cpp] view plain copy
(1)从根节点开始,自上而下选择最近的孩子节点
(2)到达叶子节点后,检查最近的元组CFi能否吸收此数据点
是,更新CF值
否,是否可以添加一个新的元组
是,添加一个新的元组
否则,分裂最远的一对元组,作为种子,按最近距离重新分配其它元组
(3)更新每个非叶节点的CF信息,如果分裂节点,在父节点中插入新的元组,检查分裂,直到root
计算节点之间的距离函数有多种选择,常见的有欧几里得距离函数和曼哈顿距离函数,具体公式如下:
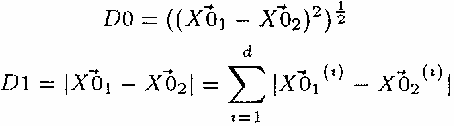
构建CF树的过程中,一个重要的参数是簇半径阈值T,因为它决定了CF tree的规模,从而让CF tree适应当前内存的大小。如果T太小,那么簇的数量将会非常的大,从而导致树节点数量也会增大,这样可能会导致所有数据点还没有扫描完之前内存就不够用了。
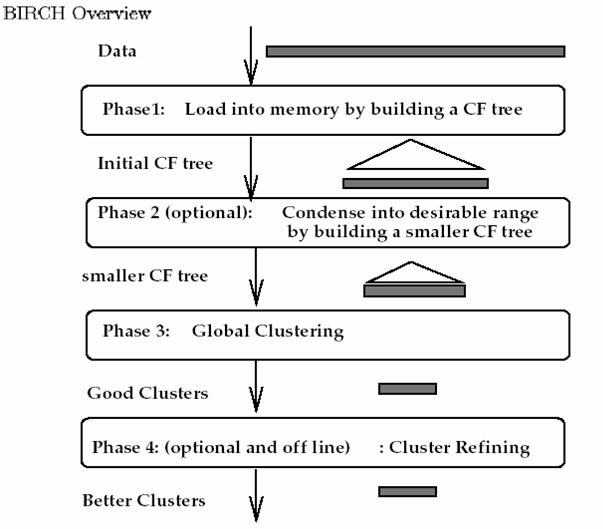
整个算法的实现分为四个阶段:
(1)扫描所有数据,建立初始化的CF树,把稠密数据分成簇,稀疏数据作为孤立点对待
(2)这个阶段是可选的,阶段3的全局或半全局聚类算法有着输入范围的要求,以达到速度与质量的要求,所以此阶段在阶段1的基础上,建立一个更小的CF树
(3)补救由于输入顺序和页面大小带来的分裂,使用全局/半全局算法对全部叶节点进行聚类
(4)这个阶段也是可选的,把阶段3的中心点作为种子,将数据点重新分配到最近的种子上,保证重复数据分到同一个簇中,同时添加簇标签
详细流程请参考文献1。
另外算法的实现也可参考:http://blog.sina.com.cn/s/blog_6e85bf420100om1i.html
参考文献:
1.BIRCH:An Efficient Data Clustering Method for Very Large Databases
http://blog.csdn.net/qll125596718/article/details/6895291
BIRCH(Balanced Iterative Reducing and Clustering using Hierarchies)天生就是为处理超大规模(至少要让你的内存容不下)的数据集而设计的,它可以在任何给定的内存下运行。关于BIRCH的更多特点先不介绍,我先讲一下算法的完整实现细节,对算法的实现过程搞清楚后再去看别人对该算法的评价才会感受深刻。
你不需要具备B树的相关知识,我接下来会讲得很清楚。
BIRCH算法的过程就是要把待分类的数据插入一棵树中,并且原始数据都在叶子节点上。这棵树看起来是这个样子:
在这棵树中有3种类型的节点:Nonleaf、Leaf、MinCluster,Root可能是一种Nonleaf,也可能是一种Leaf。所有的Leaf放入一个双向链表中。每一个节点都包含一个CF值,CF是一个三元组
,其中data point instance的个数,
和
是与数据点同维度的向量,
是线性和,
是平方和。比如有一个MinCluster里包含3个数据点(1,2,3),(4,5,6),(7,8,9),则
N=3,
=(1+4+7,2+5+8,3+6+9)=(12,15,18),
=(1+16+49,4+25+64,9+36+81)。
就拿这个MinCluster为例,我们可以计算它的
簇中心
簇半径
簇直径
我们还可以计算两个簇之间的距离
,当然你也可以使用D0,D1,D3等等,不过在这里我们使用D2。
有意思的是簇中心、簇半径、簇直径以及两簇之间的距离D0到D3都可以由CF来计算,比如
簇直径
簇间距离
,这里的N,LS和SS是指两簇合并后大簇的N,LS和SS。所谓两簇合并只需要两个对应的CF相加那可
CF1 + CF2 = (N1 + N2 , LS1 + LS2, SS1 + SS2)
每个节点的CF值就是其所有孩子节点CF值之和,以每个节点为根节点的子树都可以看成 是一个簇。
Nonleaf、Leaf、MinCluster都是有大小限制的,Nonleaf的孩子节点不能超过B个,Leaf最多只能有L个MinCluster,而一个MinCluster的直径不能超过T。
算法起初,我们扫描数据库,拿到第一个data point instance--(1,2,3),我们创建一个空的Leaf和MinCluster,把点(1,2,3)的id值放入Mincluster,更新MinCluster的CF值为(1,(1,2,3),(1,4,9)),把MinCluster作为Leaf的一个孩子,更新Leaf的CF值为(1,(1,2,3),(1,4,9))。实际上只要往树中放入一个CF(这里我们用CF作为Nonleaf、Leaf、MinCluster的统称),就要更新从Root到该叶子节点的路径上所有节点的CF值。
当又有一个数据点要插入树中时,把这个点封装为一个MinCluster(这样它就有了一个CF值),把新到的数据点记为CF_new,我们拿到树的根节点的各个孩子节点的CF值,根据D2来找到CF_new与哪个节点最近,就把CF_new加入那个子树上面去。这是一个递归的过程。递归的终止点是要把CF_new加入到一个MinCluster中,如果加入之后MinCluster的直径没有超过T,则直接加入,否则譔CF_new要单独作为一个簇,成为MinCluster的兄弟结点。插入之后注意更新该节点及其所有祖先节点的CF值。
插入新节点后,可能有些节点的孩子数大于了B(或L),此时该节点要分裂。对于Leaf,它现在有L+1个MinCluster,我们要新创建一个Leaf,使它作为原Leaf的兄弟结点,同时注意每新创建一个Leaf都要把它插入到双向链表中。L+1个MinCluster要分到这两个Leaf中,怎么分呢?找出这L+1个MinCluster中距离最远的两个Cluster(根据D2),剩下的Cluster看离哪个近就跟谁站在一起。分好后更新两个Leaf的CF值,其祖先节点的CF值没有变化,不需要更新。这可能导致祖先节点的递归分裂,因为Leaf分裂后恰好其父节点的孩子数超过了B。Nonleaf的分裂方法与Leaf的相似,只不过产生新的Nonleaf后不需要把它放入一个双向链表中。如果是树的根节点要分裂,则树的高度加1。
CF.java
+ View Code
+ View Code
+ View Code?
+ View Code
+ View Code
+ View Code
优点:
节省内在。叶子节点放在磁盘分区上,非叶子节点仅仅是存储了一个CF值,外加指向父节点和孩子节点的指针。
快。合并两个两簇只需要两个CF算术相加即可;计算两个簇的距离只需要用到(N,LS,SS)这三个值足矣。
一遍扫描数据库即可建立B树。
可识别噪声点。建立好B树后把那些包含数据点少的MinCluster当作outlier。
由于B树是高度平衡的,所以在树上进行插入或查找操作很快。
缺点:
结果依赖于数据点的插入顺序。本属于同一个簇的点可能由于插入顺序相差很远而分到不同的簇中,即使同一个点在不同的时刻被插入,也会被分到不同的簇中。
对非球状的簇聚类效果不好。这取决于簇直径和簇间距离的计算方法。
对高维数据聚类效果不好。
由于每个节点只能包含一定数目的子节点,最后得出来的簇可能和自然簇相差很大。
BIRCH适合于处理需要数十上百小时聚类的数据,但在整个过程中算法一旦中断,一切必须从头再来。
局部性也导致了BIRCH的聚类效果欠佳。当一个新点要插入B树时,它只跟很少一部分簇进行了相似性(通过计算簇间距离)比较,高的efficient导致低的effective。
1.BIRCH算法概念
BIRCH(Balanced Iterative Reducing and Clustering Using Hierarchies)全称是:利用层次方法的平衡迭代规约和聚类。BIRCH算法是1996年由Tian Zhang提出来的,参考文献1。首先,BIRCH是一种聚类算法,它最大的特点是能利用有限的内存资源完成对大数据集的高质量的聚类,同时通过单遍扫描数据集能最小化I/O代价。首先解释一下什么是聚类,从统计学的观点来看,聚类就是给定一个包含N个数据点的数据集和一个距离度量函数F(例如计算簇内每两个数据点之间的平均距离的函数),要求将这个数据集划分为K个簇(或者不给出数量K,由算法自动发现最佳的簇数量),最后的结果是找到一种对于数据集的最佳划分,使得距离度量函数F的值最小。从机器学习的角度来看,聚类是一种非监督的学习算法,通过将数据集聚成n个簇,使得簇内点之间距离最小化,簇之间的距离最大化。
BIRCH算法特点:
(1)BIRCH试图利用可用的资源来生成最好的聚类结果,给定有限的主存,一个重要的考虑是最小化I/O时间。
(2)BIRCH采用了一种多阶段聚类技术:数据集的单边扫描产生了一个基本的聚类,一或多遍的额外扫描可以进一步改进聚类质量。
(3)BIRCH是一种增量的聚类方法,因为它对每一个数据点的聚类的决策都是基于当前已经处理过的数据点,而不是基于全局的数据点。
(4)如果簇不是球形的,BIRCH不能很好的工作,因为它用了半径或直径的概念来控制聚类的边界。
BIRCH算法中引入了两个概念:聚类特征和聚类特征树,以下分别介绍。
1.1 聚类特征(CF)
CF是BIRCH增量聚类算法的核心,CF树中得节点都是由CF组成,一个CF是一个三元组,这个三元组就代表了簇的所有信息。给定N个d维的数据点{x1,x2,....,xn},CF定义如下:CF=(N,LS,SS)
其中,N是子类中节点的数目,LS是N个节点的线性和,SS是N个节点的平方和。
CF有个特性,即可以求和,具体说明如下:CF1=(n1,LS1,SS1),CF2=(n2,LS2,SS2),则CF1+CF2=(n1+n2, LS1+LS2, SS1+SS2)。
例如:
假设簇C1中有三个数据点:(2,3),(4,5),(5,6),则CF1={3,(2+4+5,3+5+6),(2^2+4^2+5^2,3^2+5^2+6^2)}={3,(11,14),(45,70)},同样的,簇C2的CF2={4,(40,42),(100,101)},那么,由簇C1和簇C2合并而来的簇C3的聚类特征CF3计算如下:
CF3={3+4,(11+40,14+42),(45+100,70+101)}={7,(51,56),(145,171)}
另外在介绍两个概念:簇的质心和簇的半径。假如一个簇中包含n个数据点:{Xi},i=1,2,3...n.,则质心C和半径R计算公式如下:
C=(X1+X2+...+Xn)/n,(这里X1+X2+...+Xn是向量加)
R=(|X1-C|^2+|X2-C|^2+...+|Xn-C|^2)/n
其中,簇半径表示簇中所有点到簇质心的平均距离。CF中存储的是簇中所有数据点的特性的统计和,所以当我们把一个数据点加入某个簇的时候,那么这个数据点的详细特征,例如属性值,就丢失了,由于这个特征,BIRCH聚类可以在很大程度上对数据集进行压缩。
1.2 聚类特征树(CF tree)
CF tree的结构类似于一棵B-树,它有两个参数:内部节点平衡因子B,叶节点平衡因子L,簇半径阈值T。树中每个节点最多包含B个孩子节点,记为(CFi,CHILDi),1<=i<=B,CFi是这个节点中的第i个聚类特征,CHILDi指向节点的第i个孩子节点,对应于这个节点的第i个聚类特征。例如,一棵高度为3,B为6,L为5的一棵CF树的例子如图所示:一棵CF树是一个数据集的压缩表示,叶子节点的每一个输入都代表一个簇C,簇C中包含若干个数据点,并且原始数据集中越密集的区域,簇C中包含的数据点越多,越稀疏的区域,簇C中包含的数据点越少,簇C的半径小于等于T。随着数据点的加入,CF树被动态的构建,插入过程有点类似于B-树。加入算法表示如下:
[cpp] view plain copy
(1)从根节点开始,自上而下选择最近的孩子节点
(2)到达叶子节点后,检查最近的元组CFi能否吸收此数据点
是,更新CF值
否,是否可以添加一个新的元组
是,添加一个新的元组
否则,分裂最远的一对元组,作为种子,按最近距离重新分配其它元组
(3)更新每个非叶节点的CF信息,如果分裂节点,在父节点中插入新的元组,检查分裂,直到root
计算节点之间的距离函数有多种选择,常见的有欧几里得距离函数和曼哈顿距离函数,具体公式如下:
构建CF树的过程中,一个重要的参数是簇半径阈值T,因为它决定了CF tree的规模,从而让CF tree适应当前内存的大小。如果T太小,那么簇的数量将会非常的大,从而导致树节点数量也会增大,这样可能会导致所有数据点还没有扫描完之前内存就不够用了。
2.算法流程
BIRCH算法流程如下图所示:整个算法的实现分为四个阶段:
(1)扫描所有数据,建立初始化的CF树,把稠密数据分成簇,稀疏数据作为孤立点对待
(2)这个阶段是可选的,阶段3的全局或半全局聚类算法有着输入范围的要求,以达到速度与质量的要求,所以此阶段在阶段1的基础上,建立一个更小的CF树
(3)补救由于输入顺序和页面大小带来的分裂,使用全局/半全局算法对全部叶节点进行聚类
(4)这个阶段也是可选的,把阶段3的中心点作为种子,将数据点重新分配到最近的种子上,保证重复数据分到同一个簇中,同时添加簇标签
详细流程请参考文献1。
3.算法实现
BIRCH算法的发明者于1996年完成了BIRCH算法的实现,是用c++语言实现的,已在solaris下编译通过。另外算法的实现也可参考:http://blog.sina.com.cn/s/blog_6e85bf420100om1i.html
参考文献:
1.BIRCH:An Efficient Data Clustering Method for Very Large Databases

相关文章推荐
- Thread Join()的用法--线程同步性
- 一个spring web的配置文件web.xml
- 实例解析Java中的synchronized关键字与线程安全问题
- Java源码打包成可运行JAR:Eclipse实现
- java 图片上传
- jenkins调整jdk版本不生效的解决办法
- eclipse中10个最有用的快捷键
- windows下双击可运行的Java软件打包方案
- spring ioc 源码解析(一)
- JAVA异常处理机制
- Spring 4.x官方参考文档中文版——第21章 Web MVC框架(12)
- Java关键字
- JavaWeb学习篇之----容器Response详解
- struts.xml
- JAVA书写规范、命名规范
- springMVC配置文件位置及名称
- Exception in thread "Thread-0" java.lang.NullPointerException
- SpringMVC工作原理
- Spring笔记
- 百无一用是代码 ---SOCKET JAVA CTISERVER