grep、egrep以及正则表达式的使用
2016-06-14 19:02
295 查看
正则表达式是linux学习里面很重要的一部分内容,也算是一个难点,元字符多,组合方法也各种各样,每个人学习理解方法不一样,其中遇到的问题也各不相同,
学习正则表达式首先要会的是grep以及egrep命令的使用。
grep 是Globalsearch Regular expression an Print out the line的缩写,是一种文本搜索的工具,可以根据用户指定的“模式(pattern)”对目标文本进行搜索过滤,显示出被“模式”匹配到的行。这里要说的一点是,grep匹配到的是符合模式的一整行,例如一行中有2位数同时有3位数,模式中匹配的是2位数,这一行是会被匹配到的,
这只是一些常用的选项,具体使用过程中遇到,可以使用man命令查看
这仅仅是grep的简单用法,要想充分利用grep需要配合正则表达式。
正则表达式分为两类:
基本正则表达式
扩展正则表达式
基本正则表达式由能够实现不同功能的元字符组成,下面按照元字符不同的作用分别说明, 为了方便看出匹配到的内容,我们先给grep一个别名,就是用上面的--color选项,能够高亮显示出匹配到的内容,匹配到的内容会以紫色显示。
字符匹配:用来对文本中的字符进行匹配的元字符
其中[]有几个特殊的表示方法
. : 匹配任意单个字符

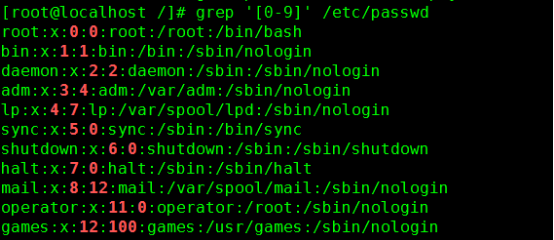
搜索/etc/passwd中含有“rt中间有一个任意字符”的行
[ ]: 匹配指定集合中的任意单个字符;
[[:digit:]], [0-9] :匹配符合搜索范围的数字;
[[:lower:]], [a-z] :匹配符合搜索范围的小写字母;

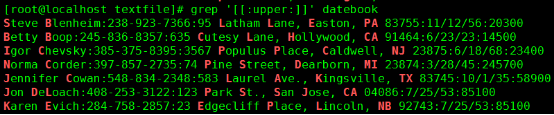
[[:upper:]], [A-Z] :匹配符合搜索范围的大写字母;
[[:alpha:]], [a-zA-Z] :匹配符合搜索范围的大小写字母;

[[:alnum:]], [0-9a-zA-Z] :匹配符合搜索范围的数字字母, 两个都可以实现这个功能;

[[:space:]] :匹配单个空格,这一行因为有个空白字符,所以被匹配出来了,因为是空白字符,就不能高亮显示了;

[[:punct:]] :即标点符号;

[^]: 匹配指定集合外的任意单个字符,匹配任意非数字字母的字符,:和/字符被匹配到了;

次数 匹配,用于对前面紧邻的单个字符所能够出现的次数做出限定;
* :匹配其前面的字符任一次,即表示0次、1次或多次;
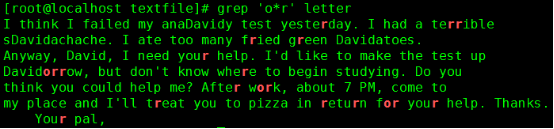
*前面的字符o出现0次或者多次,而且其后紧跟字符r,所以r,rr,or,oor 等都可以匹配到,ont就不能匹配到,因为o与t之间不是相邻的。
\? :匹配其前面的字符0次或者一次,这里要注意只有红色的部分匹配到了,虽然前面有很多个a,但是因为an匹配到了,所以整行显示出来了。

\+: 匹配其前面的字符出现至少1次;

\{m\}: 匹配其前面的字符m次,这是准确到多少次;

\{m,n\} :匹配其前面的字符至少m次,至多n次;

那么“.*”代表什么呢?很明显,匹配任意单个字符,所有的字符都被匹配到了;

位置锚定:
^: 行首锚定,写在模式的最左侧, ^lo’ 即为匹配以l开头的后面跟了o的字符;

$: 行尾锚定,写在模式的最右侧, ve$’ 即为以e结尾前面有v的字符;

^$: 空白行,这个很容易理解,行首遇到了行尾,那就是什么都没有了,即空白行;

\<: 词首锚定, \b,出现在要查找的单词模式的左侧;
“\<the” 只有作为一个单词的词首的the才能被匹配上 ;

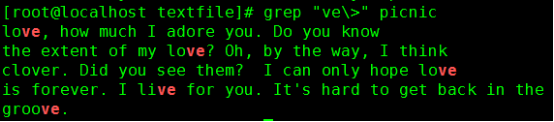
\> :词尾锚定, \b,出现在要查找的单词模式的右侧;
“ve\>” 只有作为一个单词的词尾的ve才能匹配上 ;
\<pattern\>: 匹配单词;
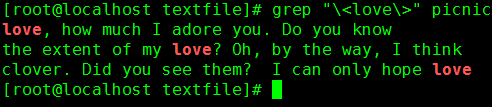
如:\<love\>,即匹配单词love,因为以l为词首以e为词尾中间是ov的只能是单词love
分组:\(需要分组的内容\),分组是为了后面可以引用前面模式匹配到的内容,这里就要介绍下后向引用的概念了。
后向引用:模式中,如果使用实现了分组,在某行文本的检查中,如果\(\)中的模式匹配到了
某 内容,此内容后面的模式中可以被引用;
\1,\2, \3
模式自左而右,引用第#个左括号以及与其匹配右括号之间的模式匹配到的内容;
如:“ \(j.n\) .*\1”: \(\) 中匹配到的内容会被引用到后面的\1的位置,前面匹配到了什么内容,后面也必须是这个内容;
johnaaabcjohn ,前面匹配到了john那后面也必须是john。

egrep 及扩展的正则表达式
扩展正则表达式有两种使用方法
扩展正则表达式的元字符:
字符匹配:
扩展正则表达式的字符匹配是和正则表达式的一样的
次数 匹配 :
从这我们可以发现,扩展正则表达式只是将正则表达式的\号去掉了而已,其他的用法都是一样的,\在模式中起到了一个转译的作用,而在扩展正则表达式中则默认转译了,不需要在加转译符号
位置锚定:
扩展正则表达式的位置锚定也是和正则表达式一样的,这里的\不能省略。
分组:
() :同样不需要转译符\,也和正则表达式一样支持后向引用\1,\2\3,…
或者:
a|b: a 或者b
ab|cd :ab或者cd
这是扩展正则表达式所独有的元字符,表示“或者”,需要注意的是“|”符号左右两边是一个整体。
最后介绍一下fgrep
fgrep [option] 'string' file...
fgrep 不支持正则表达式,只支持字符串的搜索,即string为什么匹配到的就是什么,是一种快速搜索文本的命令。
从上面可以看出扩展的正则表达式要比正则表达式简洁,而且还能实现更多的功能,所以我们要多多使用扩展正则表达式
学习正则表达式首先要会的是grep以及egrep命令的使用。
grep 是Globalsearch Regular expression an Print out the line的缩写,是一种文本搜索的工具,可以根据用户指定的“模式(pattern)”对目标文本进行搜索过滤,显示出被“模式”匹配到的行。这里要说的一点是,grep匹配到的是符合模式的一整行,例如一行中有2位数同时有3位数,模式中匹配的是2位数,这一行是会被匹配到的,
| 1 | grep [OPTIONS] PATTERN [FILE...] |
| option | 作用 |
| -i | 匹配时忽略字符大小写 |
| -o | 仅显示匹配到的内容 |
| -v | 取反,显示没有匹配到的行 |
| --color | 高亮显示匹配到的内容 |
| -A# | 显示出匹配的行之后的下文#行 |
| -B # | 显示出匹配的行之前的上文#行 |
| -C # | 显示 出匹配的行前后的#行 |
| -E | 使用扩展的正则表达式,后面会有介绍 |
这仅仅是grep的简单用法,要想充分利用grep需要配合正则表达式。
正则表达式分为两类:
基本正则表达式
扩展正则表达式
基本正则表达式由能够实现不同功能的元字符组成,下面按照元字符不同的作用分别说明, 为了方便看出匹配到的内容,我们先给grep一个别名,就是用上面的--color选项,能够高亮显示出匹配到的内容,匹配到的内容会以紫色显示。
字符匹配:用来对文本中的字符进行匹配的元字符
| . | 匹配任意单个字符 |
| [] | 匹配集合内的任意单个字符 |
| [^] | 匹配集合外的任意单个字符 |
| [0-9],[[:digit:]] | 集合内的任意单个数字 |
| [a-z],[[:lower:]] | 集合内的任意单个小写字母 |
| [A-Z],[[:upper:]] | 集合内的任意单个大写字母 |
| [a-zA-Z],[[:alpha:]] | 集合内的任意单个字母 |
| [[:space:]] | 单个空白字符 |
| [a-zA-Z0-9],[[:alnum:]]] | 集合内的任意单个字母数字 |
| [[:punct:]] | 集合内的任意单个特殊字符 |
搜索/etc/passwd中含有“rt中间有一个任意字符”的行
[ ]: 匹配指定集合中的任意单个字符;
[[:digit:]], [0-9] :匹配符合搜索范围的数字;
[[:lower:]], [a-z] :匹配符合搜索范围的小写字母;
[[:upper:]], [A-Z] :匹配符合搜索范围的大写字母;
[[:alpha:]], [a-zA-Z] :匹配符合搜索范围的大小写字母;
[[:alnum:]], [0-9a-zA-Z] :匹配符合搜索范围的数字字母, 两个都可以实现这个功能;
[[:space:]] :匹配单个空格,这一行因为有个空白字符,所以被匹配出来了,因为是空白字符,就不能高亮显示了;
[[:punct:]] :即标点符号;
[^]: 匹配指定集合外的任意单个字符,匹配任意非数字字母的字符,:和/字符被匹配到了;
次数 匹配,用于对前面紧邻的单个字符所能够出现的次数做出限定;
| * | 匹配其前面的字符任一次,即表示0次、1次或多次 |
| \? | 匹配其前面的字符0次或者一次 |
| \+ | 匹配其前面的字符出现至少1次 |
| \{m\} | 匹配其前面的字符m次,这是准确到多少次的 |
| \{m,n\} | 匹配其前面的字符至少m次,至多n次 |
*前面的字符o出现0次或者多次,而且其后紧跟字符r,所以r,rr,or,oor 等都可以匹配到,ont就不能匹配到,因为o与t之间不是相邻的。
\? :匹配其前面的字符0次或者一次,这里要注意只有红色的部分匹配到了,虽然前面有很多个a,但是因为an匹配到了,所以整行显示出来了。
\+: 匹配其前面的字符出现至少1次;
\{m\}: 匹配其前面的字符m次,这是准确到多少次;
\{m,n\} :匹配其前面的字符至少m次,至多n次;
那么“.*”代表什么呢?很明显,匹配任意单个字符,所有的字符都被匹配到了;
位置锚定:
| ^ | 行首锚定,出现在模式的最左侧 |
| $ | 行尾锚定,出现在模式的最右侧 |
| \<或者\b | 词首锚定,出现在要查找的单词模式的最左侧 |
| \>或者\b | 词尾锚定,出现在要查找的单词模式的最右侧 |
$: 行尾锚定,写在模式的最右侧, ve$’ 即为以e结尾前面有v的字符;
^$: 空白行,这个很容易理解,行首遇到了行尾,那就是什么都没有了,即空白行;
\<: 词首锚定, \b,出现在要查找的单词模式的左侧;
“\<the” 只有作为一个单词的词首的the才能被匹配上 ;
\> :词尾锚定, \b,出现在要查找的单词模式的右侧;
“ve\>” 只有作为一个单词的词尾的ve才能匹配上 ;
\<pattern\>: 匹配单词;
如:\<love\>,即匹配单词love,因为以l为词首以e为词尾中间是ov的只能是单词love
分组:\(需要分组的内容\),分组是为了后面可以引用前面模式匹配到的内容,这里就要介绍下后向引用的概念了。
后向引用:模式中,如果使用实现了分组,在某行文本的检查中,如果\(\)中的模式匹配到了
某 内容,此内容后面的模式中可以被引用;
\1,\2, \3
模式自左而右,引用第#个左括号以及与其匹配右括号之间的模式匹配到的内容;
如:“ \(j.n\) .*\1”: \(\) 中匹配到的内容会被引用到后面的\1的位置,前面匹配到了什么内容,后面也必须是这个内容;
johnaaabcjohn ,前面匹配到了john那后面也必须是john。
egrep 及扩展的正则表达式
扩展正则表达式有两种使用方法
| 1 | # grep -E 'pattern' file... |
| 1 | # egrep 'pattern' file... |
字符匹配:
| . | 匹配单个字符 |
| [] | 匹配集合中的单个字符 |
| [^] | 匹配集合之外的单个字符 |
次数 匹配 :
| * | 匹配其前面的字符任一次 |
| ? | 匹配其前面字符0次或1次 |
| + | 匹配其前面的字符至少1次 |
| {m} | 匹配其前面的字符m次 |
| {m,n} | 匹配其前面的字符m-n次 |
| {m ,} | 匹配其前面的字符至少m次 |
| {0 ,n} | 匹配其前面的字符0-n次 |
位置锚定:
| ^ | 行首锚定 |
| $ | 行尾锚定 |
| \<或者 \b | 词首 锚定 |
| \>或者 \b | 词尾锚定 |
分组:
() :同样不需要转译符\,也和正则表达式一样支持后向引用\1,\2\3,…
或者:
a|b: a 或者b
ab|cd :ab或者cd
这是扩展正则表达式所独有的元字符,表示“或者”,需要注意的是“|”符号左右两边是一个整体。
最后介绍一下fgrep
fgrep [option] 'string' file...
fgrep 不支持正则表达式,只支持字符串的搜索,即string为什么匹配到的就是什么,是一种快速搜索文本的命令。
从上面可以看出扩展的正则表达式要比正则表达式简洁,而且还能实现更多的功能,所以我们要多多使用扩展正则表达式

相关文章推荐
- linux文本处理工具之grep
- 浅析jquery数组删除指定元素的方法:grep()
- jquery遍历数组与筛选数组的方法
- shell grep 查找进程的小技巧
- hadoop实现grep示例分享
- 一天一个shell命令 linux文本内容操作系列-grep命令详解
- Shell正则表达式之grep、sed、awk实操笔记
- ls --color的使用
- grep,awk,sed实例
- [Linux学习笔记] Linux常用命令 - 文件搜索命令
- 一天一个shell命令 linux文本内容操作系列-grep命令详解
- 总结Linux中用于文本处理的awk、sed、grep命令用法
- grep 命令系列:从文件中搜索并显示文件名
- grep 命令系列:如何在 UNIX 中根据文件内容查找文件
- grep 命令系列:使用 grep 命令来搜索多个单词
- grep 命令系列:用 grep 命令统计匹配字符串的行数
- grep 命令系列:grep 中的正则表达式
- grep 命令系列:如何在 Linux/UNIX 中使用 grep 命令
- 浅析jquery数组删除指定元素的方法:grep()
- 14 个 Linux grep 命令的例子