开题报告提纲
2016-06-14 09:08
323 查看
无人机自主导航及降落,
三种情况(Landing phase)1. GPS available. (空旷的地方)
Multi-Sensor Fusion, Sensor Self-Calibration, Visual-Inertial Navigation.
2. GPS not available.(室内,建筑密集区。 这样的地方的特点是人造的场景多,纹理十分规则明显。可以使用其中的结构特点恢复结构。)
- Camera pose estimation.
- visual odometer.
3. 合作目标可见的场景。
- runway detection.
- Image registration(runway image match)
- (color )marker (UAV Attitude and Position Estimation by n salient points detection and tracking it to estimate the location and orientation UAV).
- Ground Control Station aided.(two cameras capture image of the UAV, then get matched point to estimate the location of UAV and landing).
- land marker tracking.
相机姿态的测量
现有方法:1. 使用已知形状的平面目标,已知内参数,PnP。
缺陷是这种方法仅适用于规则目标,无法适用于自然场景。
2. horizontal line(varnishing line)
For images where you see lines corresponding to 3 orthogonal directions you
can compute the camera matrix K as well as rotation matrix R.
- Detect lines in an image.
- Find all intersections of lines.
- Vote for each intersection
- Solve: vp,vp2,vp3=argmaxortho(p,q,r)(vote(p)+vote(q)+vote(r))
- refer
- Greedy: Lee et al., NIPS’10,Hedau et al., ICCV’09 code
- Exact (when K known): Bazin et al., CVPR’12

[net2net](a ccelerating l earning via k nowledge t ransfer)
3. Thinking inside the box
- Inference
- Object is a box, aligned with the (Manhattan) room
- Assume the camera is distance h above ground
- Place a point on the floor,assume box of known physical height
- Score each face in fronto-parallel coordinates
- Score a box by summing the scores of the visible faces score(box)=∑ivi⋅maxf∈N(fi)sc(fi)∑ivi
- Training:
- Train each face independently using SVM
4. Deform models for 3d object detection.
- Relocalizes the box more precisely via several cues:
Edge-based features (line segments) on the cuboid edges
Corner-based features (Harris cornerness measure) on cuboid corners
“Peg” detector
- global image matching
5. 计算整张图像和一个关键帧组成的集合的相似度,该方法常用于SLAM.
6. sparse feature matching.
计算图像中的关键点(特征点),构造描述子,匹配的时候使用描述子进行匹配(ORB-SLAM)。这些方法聚焦于于提高算法的效率,学习的描述子,匹配等。
7. appearance-based localization
通过对场景的分类,类别数量为有限个离散的位置,这种方法只能得到位姿的粗略估计。(SIFT features in a bag of words)
8. CNN-3dObject, 该方法提出了一种描述子可以同时描述以及他们的3D姿势,使用欧拉距离计算描述子之间的相似度,该描述子使用CNN网络学习得到。但是训练数据需要RGB-D数据。[1][2]
9. 使用已知3D模型的目标作为训练数据,对于实际场景训练。建立一个包含精确对齐可匹配的3D模型的的一系列常用物体的数据库,使用局部关键点检测器(HOG)找到可能的位姿,并队每个可能的位姿进行全局配准。
训练集和测试集差异性性较大,有效性较差,得到(离散)的位姿角度。
9. Scene Coordinate Regression Forests
RGB-D数据集,利用回归森林推断实际坐标系中的每个像素对应的3D坐标,进而可以推测相机的姿态。位姿估计方法使用一种计量估计器结果和给定位姿假设一致的像素的数量的能量函数,然后使用RANSAC算法得到相机的位姿。
10. posenet 预训练的CNN参数,结合修改的CNN模型(最后一层sfotmax层修改为回归层,设置损失为loss(I)=∥x^−x∥+β∥∥q^−q∥q∥∥∥),数据的标签来自于SFM(Structure from motion), 结合SLAM, 可以做为SLAM 的lication 部分.
优点:适用于各种自然场景,得到连续的6 DOF位姿信息。
缺点:需要预训练的模型(大规模分类图像数据-ImageNet预训练的结果)参数作为初始迭代点,数据的标签很难获得。
拟研究的内容
结合posenet和matchnet,使用autoencoder的方法(
),降低网络的层数,减小网络的训练难度。
结合特征学习和sparse subspace selection方法,选取key frame 来加快位姿估计器训练过程。
IMU-Camera data fusion
Kalman Filter需要尺度信息,尺度信息从已知尺寸的特征标识(Feature Pattern)。
Extended Kalman Filter or EKF-SLAM
无需特定的目标,但是需要固定的特征,标定时首先估计特定特征得到尺度信息,对于有m个特征的图像,理论上其算法复杂度为O(m2)。直接将图像的特征输入至EKF,同IMU数据融合得到位姿,位置等信息
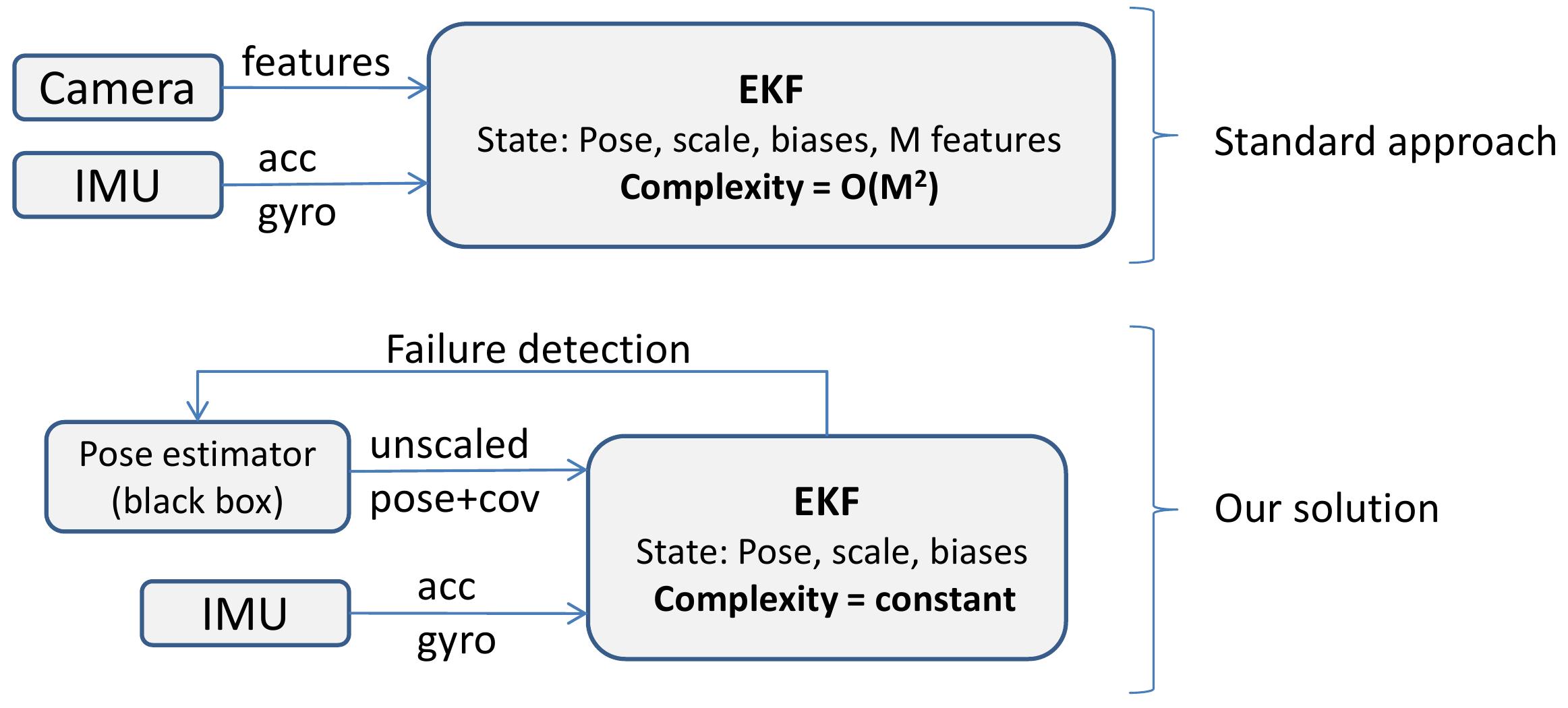
输入为图像测得位姿和位置同IMU数据融合,因此需要一个基于图像的位姿估计器(SLAM,PnP等),对于有m个特征的图像,理论上其算法复杂度为O(m)。
- MSF-EKF(multi-sensor-fusion ekf)
拟研究方向
角度1. 将IMU数据和图像直接融合,在图像处理中重点研究如何学习特征,结合IMU数据的特点提高图像测位姿的精度。角度2. 融合器的输入改为图像,在EKF处理图像数据之间使用基于CNN框架的位姿估计器,之后该估计器的训练过程中可以使用IMU数据辅助对特征的学习等。

appendix
GPS
GPS信号只有在开阔的空间内才能给出比较好的测量值,因为GPS接收机需要从天上的卫星获得信号,这些信号要从太空传入大气层,这么远的距离,信号已经相对来说很微弱,所以必须要求接收机和卫星之间的连线上没有遮挡,一旦有建筑甚至是树木的遮挡,卫星发下来的信号就有噪声,GPS接收机就不能给出很好的位置和速度观测。在室内环境中,GPS甚至完全不能使用。传感器的数量、功能和特性
| 传感器 | 是否参与该状态的测量 | |||
|---|---|---|---|---|
| 传感器类型 | 使用场景 | 三维位置 | 三维速度 | 三维加速度 |
| GPS | 室外 | 是 | 是 | |
| IMU | 室内室外 | 是 | 是 | |
| 气压计 | 室内室外 | 仅一维位置 | 仅一维速度 | 仅一维加速度 |
| 罗盘 | 室内室外 | 辅助GPS | ||
| 超声波 | 室内室外 | 仅一维位置 | 仅一维速度 | |
| vision | 光照条件 | 是 | 是 |
无人机平台
| 模块 | 选型 | specification & parameters |
|---|---|---|
| 飞控 | pxihawk | with INS |
| GPS | ||
| 轴距 | 650mm | |
| - | – | |
| 电调 | 乐天 | 40A |
| 桨叶 | 1555 | |
| 电池 | 酷点 | 6000mAh |
| 遥控 | futuba | d10 |
| 电机 | 飓风 | 4110 |
| parameters | value |
|---|---|
| frame重量 | 612g |
| 起飞重量 | 2.3kg |
| 负载 | 1-2kg |
| 飞行时间 | 20min |
pixhawk

Microprocessor:
32-bit STM32F427 Cortex M4 core with FPU
168 MHz/256 KB RAM/2 MB Flash
32 bit STM32F103 failsafe co-processor
Sensors:
ST Micro L3GD20 3-axis 16-bit gyroscope
ST Micro LSM303D 3-axis 14-bit accelerometer / magnetometer
Invensense MPU 6000 3-axis accelerometer/gyroscope
MEAS MS5611 barometer
Reference
[1] X. Pan, D. q. Ma, L. l. Jin, and Z. s. Jiang, “Vision-based approach angle and height estimation for uav landing,” in Image and Signal Processing, 2008. CISP ’08. Congress on, vol. 3, May 2008, pp. 801–805.[2] A. Miller, M. Shah, and D. Harper, “Landing a uav on a runway using image registration,” in Robotics and Automation, 2008. ICRA 2008. IEEE International Conference on, May 2008, pp. 182–187.
[3] L. Burlion and H. de Plinval, “Keeping a ground point in the camera field of view of a landing uav,” in Robotics and Automation (ICRA), 2013 IEEE International Conference on, May 2013, pp. 5763–5768.
[4] C. Pan, T. Hu, and L. Shen, “Brisk based target localization for fixed-wing uav’s vision-based autonomous landing,” in Information and Automation, 2015 IEEE International Conference on, Aug 2015, pp. 2499–2503.
[5] M. Sereewattana, M. Ruchanurucks, S. Thainimit, S. Kongkaew, S. Siddhichai, and S. Hasegawa, “Color marker detection with various imaging
conditions and occlusion for uav automatic landing control,” in Defence
Technology (ACDT), 2015 Asian Conference on, April 2015, pp. 138–142.
[6] D. Tang, F. Li, N. Shen, and S. Guo, “Uav attitude and position estimationfor vision-based landing,” in Electronic and Mechanical Engineering
and Information Technology (EMEIT), 2011 International Conference on, vol. 9, Aug 2011, pp. 4446–4450.
[7] K. Abu-Jbara, W. Alheadary, G. Sundaramorthi, and C. Claudel, “A robustvision-based runway detection and tracking algorithm for automatic uav
landing,” in Unmanned Aircraft Systems (ICUAS), 2015 International Conference on, June 2015, pp. 1148–1157.
[8] D. Tang, T. Hu, L. Shen, D. Zhang, and D. Zhou, “Chan-vese modelbased binocular visual object extraction for uav autonomous take-off and
landing,” in 2015 5th International Conference on Information Science and Technology (ICIST), April 2015, pp. 67–73.
[9] S. Hinterstoisser, S. Benhimane, , V. Lepetit, and N. Navab, “Simulta-neous recognition and homography extraction of local patches with a
simple linear classifier,” 2008.
[10] P. Wohlhart and V. Lepetit, “Learning descriptors for object recognitionand 3d pose estimation,” in Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition, 2015.
[11] N. Sunderhauf, S. Shirazi, F. Dayoub, B. Upcroft, and M. Milford, “Onthe performance of convnet features for place recognition,” in Intelligent
Robots and Systems (IROS), 2015 IEEE/RSJ International Conferenceon. IEEE, 2015, pp. 4297–4304.
[12] J. Shotton, B. Glocker, C. Zach, S. Izadi, A. Criminisi, and A. Fitzgib-bon, “Scene coordinate regression forests for camera relocalization in
rgb-d images,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2013, pp. 2930–2937.
[13] C. Brooks, “C++ implementation of score forests for camera relocaliza-tion,” https://github.com/isue/relocforests, 2016.
[14] J. J. Lim, H. Pirsiavash, and A. Torralba, “Parsing IKEA Objects: FinePose Estimation,” ICCV, 2013.

相关文章推荐
- cell上按钮的点击事件
- iOS 走进Facebook POP的世界
- OD_我的疑问
- QT5打包发布程序的方法
- Oracle SQL PLUS 执行SQL脚本文件是否执行后续SQL
- exec和source
- 工程师精神一定程度上就是精益求精的工匠精神
- com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
- Android中的“再按一次返回键退出程序”功能实现
- phpcms v9如何给父级单页栏目添加内容?
- SlidingMenu的学习
- git的学习笔记
- 常用的一些linux命令
- Android studio开发环境搭建教程与软件安装教程(从零开始学android)
- python3里使用selenium webdriver自动化测试
- python3里使用selenium webdriver自动化测试
- BZOJ 1086 王室联邦
- c#之双色球
- 分数类的运算符重载
- window7 已经分好区的硬盘如何再次分区?