Elasticsearch学习(一)
2016-06-13 22:50
197 查看
Elasticsearch简介
Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎。无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。但是,Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
不过,Elasticsearch不仅仅是Lucene和全文搜索,我们还能这样去描述它:
- 分布式的实时文件存储,每个字段都被索引并可被搜索 - 分布式的实时分析搜索引擎 - 可以扩展到上百台服务器,处理PB级结构化或非结构化数据
而且,所有的这些功能被集成到一个服务里面,你的应用可以通过简单的RESTful API、各种语言的客户端甚至命令行与之交互。
安装
安装很简单:1.下载ElasticSearch_版本号.tar.gz,官网上有,下载好之后,直接进入bin目录启动2. Mac系统直接用brew命令安装。
./elasticsearch 启动
如果想后台运行,则执行 ./elasticsearch -d
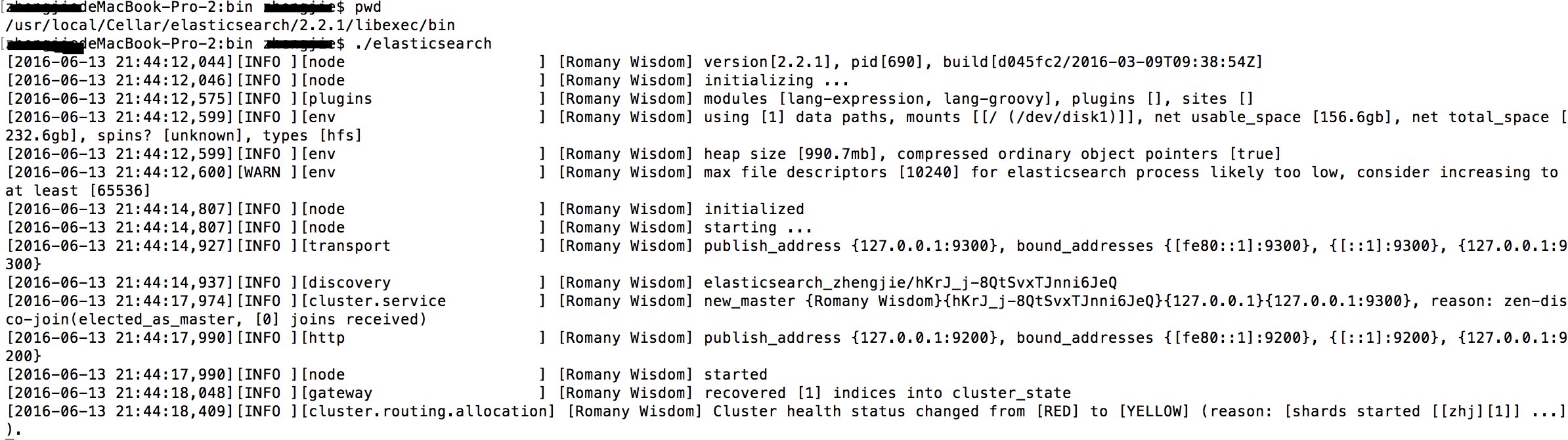
检查是否启动成功
lsof -i:9200
lsof -i:9300

RESTful API
ElasticSearch可以提供基于HTTP协议,以JSON为数据交互格式的RESTful API。通过9200端口的与Elasticsearch进行通信,你可以使用你喜欢的WEB客户端,你也可以通过curl命令与Elasticsearch通信。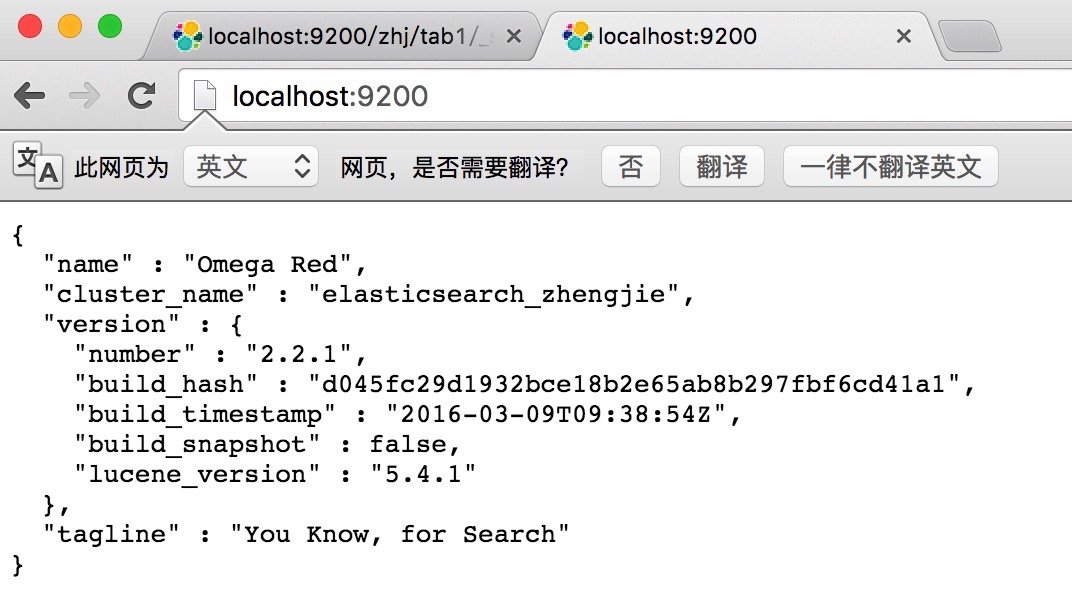
通过http://localhost:9200/?pretty
可以查看Elasticsearch安装的详细信息,包括版本号,集群名称…
术语和基本的概念
在Elasticsearch中存储数据的行为就叫做索引(indexing)文档归属于一种类型(type),而这些类型存在于索引(index)中,我们可以画一些简单的对比图来类比传统关系型数据库:
Relational DB -> Databases -> Tables -> Rows -> Columns Elasticsearch -> Indices -> Types -> Documents -> Fields
Elasticsearch集群可以包含多个索引(indices)(数据库),每一个索引可以包含多个类型(types)(表),每一个类型包含多个文档(documents)(行),然后每个文档包含多个字段(Fields)(列)。
「索引」含义的区分 你可能已经注意到索引(index)这个词在Elasticsearch中有着不同的含义,所以有必要在此做一下区分: 索引(名词) 如上文所述,一个索引(index)就像是传统关系数据库中的数据库,它是相关文档存储的地方,index的复数是indices 或indexes。 索引(动词) 「索引一个文档」表示把一个文档存储到索引(名词)里,以便它可以被检索或者查询。这很像SQL中的INSERT关键字,差别是,如果文档已经存在,新的文档将覆盖旧的文档。 倒排索引 传统数据库为特定列增加一个索引,例如B-Tree索引来加速检索。Elasticsearch和Lucene使用一种叫做倒排索引(inverted index)的数据结构来达到相同目的。
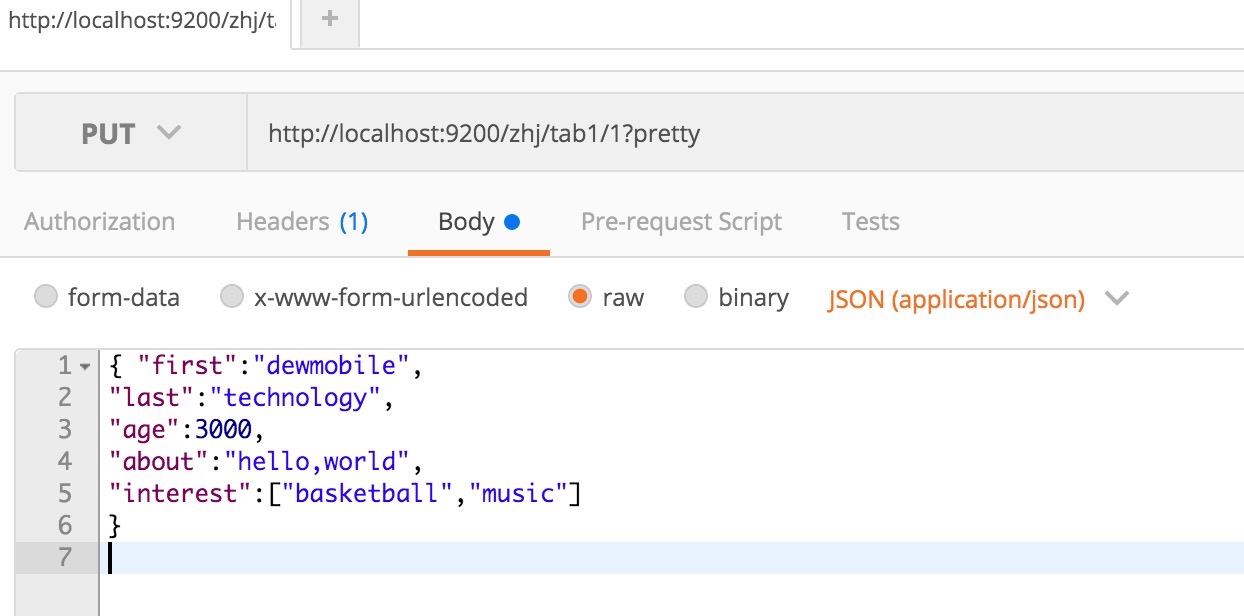
分析:
first last age about interest 为Fields 1 为文档 每个文档的类型为tab1。 tab1类型归属于索引 zhj。 zhj 索引存储在Elasticsearch集群中。
通过restful API我们可以查看刚才存储的信息
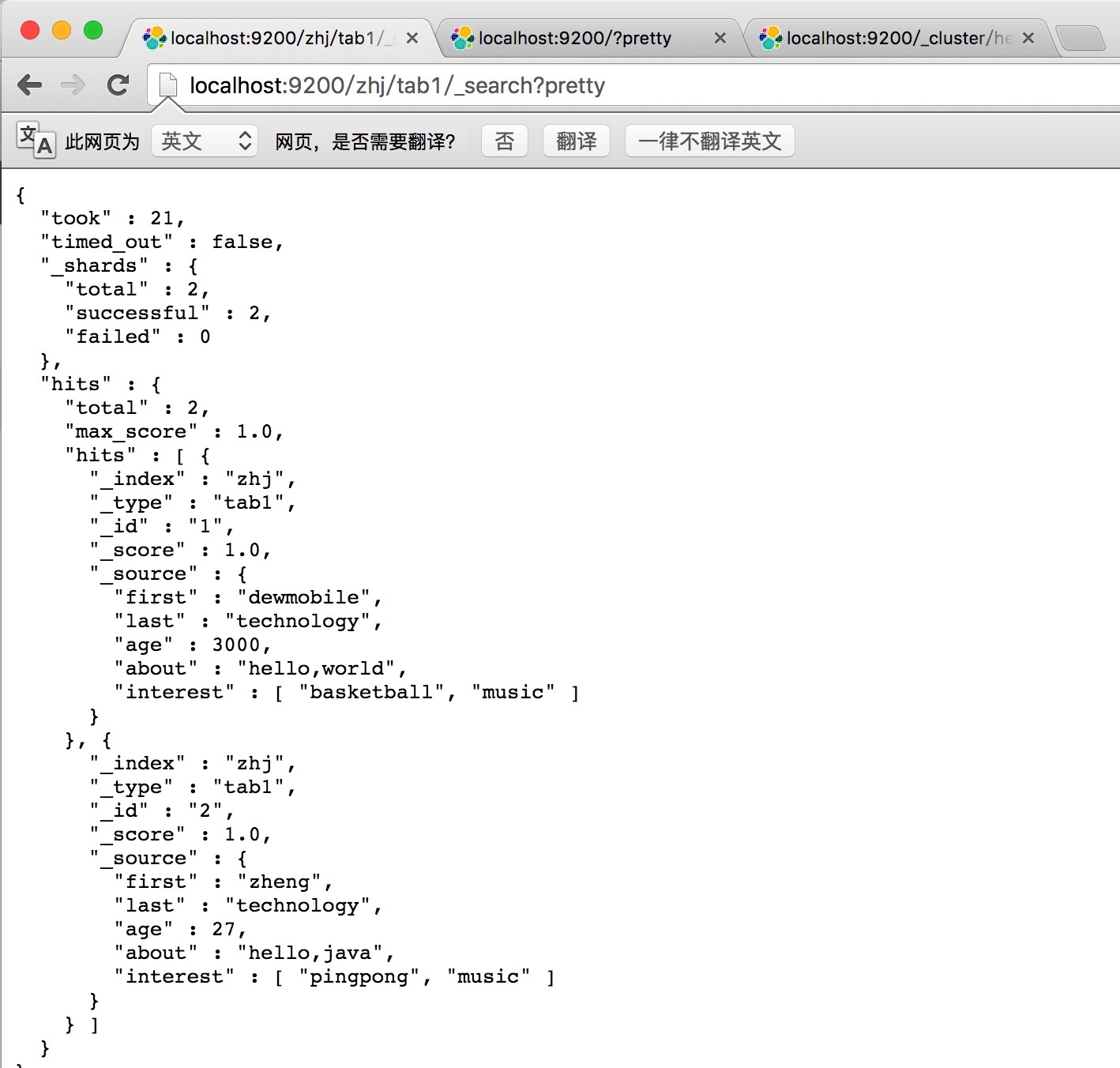
以上是对Elasticsearch 基础学习,后续会继续补充对其进行分布式增删改查,搜索,结构化查询,分片等等。

相关文章推荐
- 微信搜一搜迈出新的一步,好戏来了
- 巧用mysql提示符prompt清晰管理数据库的方法
- AJAX 支持搜索引擎问题分析
- 搜索引擎对关键词作弊判断方法揭密
- 使用php记录用户通过搜索引擎进网站的关键词
- 两大步骤教您开启MySQL 数据库远程登陆帐号的方法
- android将搜索引擎设置为中国雅虎无法搜索问题解决方法
- Asp.Net、asp实现的搜索引擎网址收录检查程序
- phpmyadmin 4+ 访问慢的解决方法
- linux系统下实现mysql热备份详细步骤(mysql主从复制)
- 如何让搜索引擎抓取AJAX内容解决方案
- PHP判断来访是搜索引擎蜘蛛还是普通用户的代码小结
- php实现判断访问来路是否为搜索引擎机器人的方法
- CentOS 5.5下安装MySQL 5.5全过程分享
- MySQL复制的概述、安装、故障、技巧、工具(火丁分享)
- MySQL中删除重复数据的简单方法
- php获取从百度、谷歌等搜索引擎进入网站关键词的方法
- 解析PHP对现有搜索引擎的调用
- C#判断访问来源是否为搜索引擎链接的方法
- WordPress特定文章对搜索引擎隐藏或只允许搜索引擎查看