HashMap实现原理
2016-06-13 18:02
447 查看
这里用到的知识有hashcode()、equals()、数组、链表、哈希表等知识。
1.equals(Object obj)和hashcode()这两个方法是在Object类中定义的。
equals(Object obj)方法用来判断两个对象是否“相同”,如果“相同”则返回true,否则返回false。
hashcode()方法返回一个int数,在Object类中的默认实现是“将该对象的内部地址转换成一个整数返回”。
2.接下来有两个关于这两个方法的重要规范(这里只抽取了最重要的两个,其实不止两个):
规范1:若重写equals(Object obj)方法,有必要重写hashcode()方法,确保通过equals(Object obj)方法判断结果为true的两个对象具备相等的hashcode()返回值。即“两个对象相等,则hashcode必须相同”不过请注意:这个只是规范,如果你非要写一个类让equals(Object obj)返回true而hashcode()返回两个不相等的值,编译和运行都是不会报错的。不过这样违反了Java规范,程序也就埋下了BUG。
规范2:如果equals(Object obj)返回false,即两个对象“不相同”,并不要求对这两个对象调用hashcode()方法得到两个不相同的数。即“两个对象的hashcode相同,不一定相等”
其实这两个规范,其实只需记住第一个规范,第二个规范通过第一个规范可以推导出来。所以最重要的就是“两个对象equals相等,则hashcode必须相同”
根据这两个规范,可以得到如下推论:
1、如果两个对象equals,Java运行时环境会认为他们的hashcode一定相等(原命题)。
2、如果两个对象不equals,他们的hashcode有可能相等(1的否命题)。
3、如果两个对象hashcode相等,他们不一定equals(1的逆命题)。
4、如果两个对象hashcode不相等,他们一定不equals(1的逆否命题)。
之所以要将equals()和hashcode()方法,是因为HashMap的存取方法用到了这两个方法并且遵守了规范的最低要求。
哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法—— 拉链法,我们可以理解为“链表的数组” ,如图:
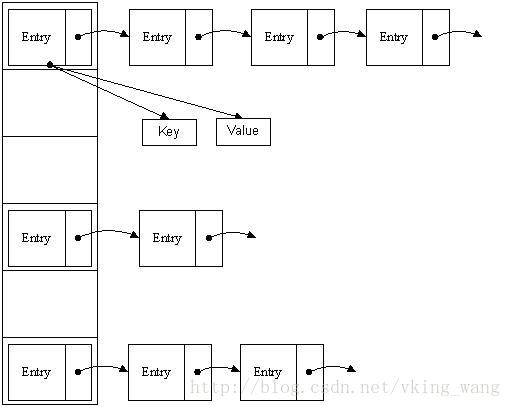
从上图我们可以发现哈希表是由数组+链表组成的,一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。
HashMap其实也是一个线性的数组实现的,所以可以理解为其存储数据的容器就是一个线性数组。这可能让我们很不解,一个线性的数组怎么实现按键值对来存取数据呢?这里HashMap有做一些处理。
首先HashMap里面实现一个静态内部类Entry,其重要的属性有 key , value, next,从属性key,value我们就能很明显的看出来Entry就是HashMap键值对实现的一个基础bean,我们上面说到HashMap的基础就是一个线性数组,这个数组就是Entry[],Map里面的内容都保存在Entry[]里面。
put方法:
get方法:
hashmap中的hash算法:
这里,算法进行了二次hash,使高位也参与到计算中,防止低位不变造成的hash冲突
注:这一切的目的实际上都是为了使value尽量分布到map中不同的位置
对于任意给定的对象,只要它的 hashCode() 返回值相同,那么程序调用 hash(int h) 方法所计算得到的 hash 码值总是相同的。我们首先想到的就是把 hash 值对数组长度取模运算,这样一来,元素的分布相对来说是比较均匀的。但是,“模”运算的消耗还是比较大的,在 HashMap 中是这样做的:调用 indexFor(int h, int length) 方法来计算该对象应该保存在 table 数组的哪个索引处。indexFor(int h, int length) 方法的代码如下:
这个方法就是为了获取数据存入哈希表中的指定位置索引而进行的取模运算。这里牵扯到hashmap的另外一个问题–关于length长度的定义和位运算的一个知识。
在put操作的开始,有判断table是否为空,如果为空则会初始化table,初始化的代码如下:
HashMap 的性能参数(这段直接从参考文章引来):
HashMap 包含如下几个构造器:
HashMap():构建一个初始容量为 16,负载因子为 0.75 的 HashMap。
HashMap(int initialCapacity):构建一个初始容量为 initialCapacity,负载因子
为 0.75 的 HashMap。
HashMap(int initialCapacity, float loadFactor):以指定初始容量、指定的负载因子创建一个 HashMap。HashMap 的基础构造器 HashMap(int initialCapacity, float loadFactor)带有两个参数,它们是初始容量 initialCapacity 和加载因子 loadFactor。
initialCapacity:HashMap 的最大容量,即为底层数组的长度。
loadFactor:负载因子 loadFactor 定义为:散列表的实际元素数目(n)/ 散列表的容量(m)。负载因子衡量的是一个散列表的空间的使用程度,负载因子越大表示散列表的装填程度越高,反之愈小。对于使用链表法的散列表来说,查找一个元素的平均时间是 O(1+a),因此如果负载因子越大,对空间的利用更充分,然而后果是查找效率的降低;如果负载因子太小,那么散列表的数据将过于稀疏,对空间造成严重浪费。
HashMap 的实现中,通过 threshold 字段来判断 HashMap 的最大容量:
结合负载因子的定义公式可知, threshold 就是在此 loadFactor 和 capacity 对应下允许的最大元素数目,超过这个数目就重新 resize,以降低实际的负载因子。默认的的负载因子0.75 是对空间和时间效率的一个平衡选择。当容量超出此最大容量时, resize 后的 HashMap容量是容量的两倍。
table存储新key的方法如下:
这段代码的if语句代表若map的容量超过临界值时就扩容table,这样就保证了map的容量总是2的次幂的形式。
当length是2的次幂时,h& (length-1)运算等价于对 length 取模,也就是h%length,但是&比%具有更高的效率。原因就是当length 是2的次幂时,length -1的二进制数1都连续的位于后几位,如8是1000,而8-1就是0111。这样任何一个数和它与时,实际上就是将后几位截取了下来,而这几位就是h对length的余数。
下面是存储新key过程:
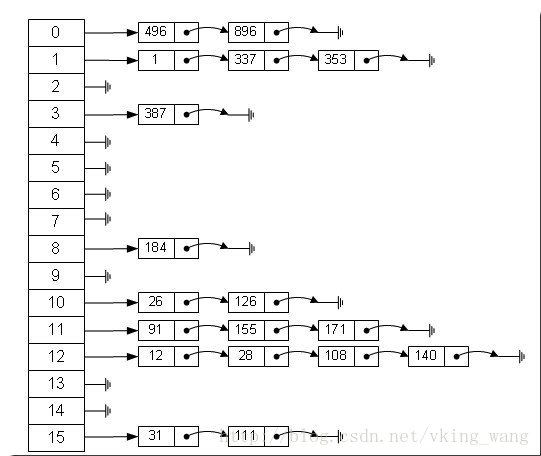
Entry类里面有一个next属性,作用是指向下一个Entry。打个比方, 第一个键值对A进来,通过计算其key的hash得到的index=0,记做:Entry[0] = A。一会后又进来一个键值对B,通过计算其index也等于0,现在怎么办?HashMap会这样做:B.next = A,Entry[0] = B,如果又进来C,index也等于0,那么C.next = B,Entry[0] = C;这样我们发现index=0的地方其实存取了A,B,C三个键值对,他们通过next这个属性链接在一起。所以疑问不用担心。也就是说数组中存储的是最后插入的元素。到这里为止,HashMap的大致实现,我们应该已经清楚了。
引用:http://my.oschina.net/zhenglingfei/blog/403146
引用:http://blog.csdn.net/lclai/article/details/6195104
引用:http://blog.csdn.net/vking_wang/article/details/14166593
equals()和hashcode()
这里首先说明一下equals(Object obj)和hashcode():1.equals(Object obj)和hashcode()这两个方法是在Object类中定义的。
equals(Object obj)方法用来判断两个对象是否“相同”,如果“相同”则返回true,否则返回false。
hashcode()方法返回一个int数,在Object类中的默认实现是“将该对象的内部地址转换成一个整数返回”。
2.接下来有两个关于这两个方法的重要规范(这里只抽取了最重要的两个,其实不止两个):
规范1:若重写equals(Object obj)方法,有必要重写hashcode()方法,确保通过equals(Object obj)方法判断结果为true的两个对象具备相等的hashcode()返回值。即“两个对象相等,则hashcode必须相同”不过请注意:这个只是规范,如果你非要写一个类让equals(Object obj)返回true而hashcode()返回两个不相等的值,编译和运行都是不会报错的。不过这样违反了Java规范,程序也就埋下了BUG。
规范2:如果equals(Object obj)返回false,即两个对象“不相同”,并不要求对这两个对象调用hashcode()方法得到两个不相同的数。即“两个对象的hashcode相同,不一定相等”
其实这两个规范,其实只需记住第一个规范,第二个规范通过第一个规范可以推导出来。所以最重要的就是“两个对象equals相等,则hashcode必须相同”
根据这两个规范,可以得到如下推论:
1、如果两个对象equals,Java运行时环境会认为他们的hashcode一定相等(原命题)。
2、如果两个对象不equals,他们的hashcode有可能相等(1的否命题)。
3、如果两个对象hashcode相等,他们不一定equals(1的逆命题)。
4、如果两个对象hashcode不相等,他们一定不equals(1的逆否命题)。
之所以要将equals()和hashcode()方法,是因为HashMap的存取方法用到了这两个方法并且遵守了规范的最低要求。
哈希表
数组
数组存储区间是连续的,占用内存严重,故空间复杂的很大。但数组的二分查找时间复杂度小,为O(1);数组的特点是:寻址容易,插入和删除困难;链表
链表存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,达O(N)。链表的特点是:寻址困难,插入和删除容易。哈希表
那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是我们要提起的哈希表。哈希表((Hash table)既满足了数据的查找方便,同时不占用太多的内容空间,使用也十分方便。哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法—— 拉链法,我们可以理解为“链表的数组” ,如图:
从上图我们可以发现哈希表是由数组+链表组成的,一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。
HashMap其实也是一个线性的数组实现的,所以可以理解为其存储数据的容器就是一个线性数组。这可能让我们很不解,一个线性的数组怎么实现按键值对来存取数据呢?这里HashMap有做一些处理。
首先HashMap里面实现一个静态内部类Entry,其重要的属性有 key , value, next,从属性key,value我们就能很明显的看出来Entry就是HashMap键值对实现的一个基础bean,我们上面说到HashMap的基础就是一个线性数组,这个数组就是Entry[],Map里面的内容都保存在Entry[]里面。
哈希算法
哈希算法又称散列算法,就是把任意长度的输入(又叫做预映射, pre-image ),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,这种转化是不可逆的。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。 HASH 主要用于信息安全领域中加密算法,它把一些不同长度的信息转化成杂乱的128 位的编码, 这些编码值叫做HASH 值. 也可以说,hash 就是找到一种数据内容和数据存放地址之间的映射关系。 下面,来看看HashMap的存取代码,即put、get方法
HashMap存取原理
首先浏览一下get、put方法put方法:
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>.
* (A <tt>null</tt> return can also indicate that the map
* previously associated <tt>null</tt> with <tt>key</tt>.)
*/
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);//初始化table
}
if (key == null)
return putForNullKey(value);//null总是放在数组的
//第一个链表中
int hash = hash(key);//hash算法
int i = indexFor(hash, table.length);//获取该key-
//value在table的存储索引
for (Entry<K,V> e = table[i]; e != null; e = e.next) {//遍历该位置处的链表
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {//查找该key是否已经存储,若是则替换原来的value,并返回oldValue
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
//若key不曾存储,则修改次数增1,并存储key-value
modCount++;
addEntry(hash, key, value, i);
4000
return null;
}get方法:
/**
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* <p>More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code (key==null ? k==null :
* key.equals(k))}, then this method returns {@code v}; otherwise
* it returns {@code null}. (There can be at most one such mapping.)
*
* <p>A return value of {@code null} does not <i>necessarily</i>
* indicate that the map contains no mapping for the key; it's also
* possible that the map explicitly maps the key to {@code null}.
* The {@link #containsKey containsKey} operation may be used to
* distinguish these two cases.
*
* @see #put(Object, Object)
*/
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}hashmap中的hash算法:
/**
* Retrieve object hash code and applies a supplemental hash function to the
* result hash, which defends against poor quality hash functions. This is
* critical because HashMap uses power-of-two length hash tables, that
* otherwise encounter collisions for hashCodes that do not differ
* in lower bits. Note: Null keys always map to hash 0, thus index 0.
*/
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}这里,算法进行了二次hash,使高位也参与到计算中,防止低位不变造成的hash冲突
注:这一切的目的实际上都是为了使value尽量分布到map中不同的位置
对于任意给定的对象,只要它的 hashCode() 返回值相同,那么程序调用 hash(int h) 方法所计算得到的 hash 码值总是相同的。我们首先想到的就是把 hash 值对数组长度取模运算,这样一来,元素的分布相对来说是比较均匀的。但是,“模”运算的消耗还是比较大的,在 HashMap 中是这样做的:调用 indexFor(int h, int length) 方法来计算该对象应该保存在 table 数组的哪个索引处。indexFor(int h, int length) 方法的代码如下:
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}这个方法就是为了获取数据存入哈希表中的指定位置索引而进行的取模运算。这里牵扯到hashmap的另外一个问题–关于length长度的定义和位运算的一个知识。
在put操作的开始,有判断table是否为空,如果为空则会初始化table,初始化的代码如下:
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
int capacity = roundUpToPowerOf2(toSize);
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}resize
resize只有在hashmap中元素的大小达到临界值的时候才会进行,而临界值和loadFactor 参数有关,只有数量达到loadFactor *table.length才会重新分配table,元素也将重新映射,这是非常耗性能的操作,所以最好一开始能确定元素的大概范围HashMap 的性能参数(这段直接从参考文章引来):
HashMap 包含如下几个构造器:
HashMap():构建一个初始容量为 16,负载因子为 0.75 的 HashMap。
HashMap(int initialCapacity):构建一个初始容量为 initialCapacity,负载因子
为 0.75 的 HashMap。
HashMap(int initialCapacity, float loadFactor):以指定初始容量、指定的负载因子创建一个 HashMap。HashMap 的基础构造器 HashMap(int initialCapacity, float loadFactor)带有两个参数,它们是初始容量 initialCapacity 和加载因子 loadFactor。
initialCapacity:HashMap 的最大容量,即为底层数组的长度。
loadFactor:负载因子 loadFactor 定义为:散列表的实际元素数目(n)/ 散列表的容量(m)。负载因子衡量的是一个散列表的空间的使用程度,负载因子越大表示散列表的装填程度越高,反之愈小。对于使用链表法的散列表来说,查找一个元素的平均时间是 O(1+a),因此如果负载因子越大,对空间的利用更充分,然而后果是查找效率的降低;如果负载因子太小,那么散列表的数据将过于稀疏,对空间造成严重浪费。
HashMap 的实现中,通过 threshold 字段来判断 HashMap 的最大容量:
threshold = (int)(capacity * loadFactor);
结合负载因子的定义公式可知, threshold 就是在此 loadFactor 和 capacity 对应下允许的最大元素数目,超过这个数目就重新 resize,以降低实际的负载因子。默认的的负载因子0.75 是对空间和时间效率的一个平衡选择。当容量超出此最大容量时, resize 后的 HashMap容量是容量的两倍。
table存储新key的方法如下:
/**
* Adds a new entry with the specified key, value and hash code to
* the specified bucket. It is the responsibility of this
* method to resize the table if appropriate.
*
* Subclass overrides this to alter the behavior of put method.
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}这段代码的if语句代表若map的容量超过临界值时就扩容table,这样就保证了map的容量总是2的次幂的形式。
当length是2的次幂时,h& (length-1)运算等价于对 length 取模,也就是h%length,但是&比%具有更高的效率。原因就是当length 是2的次幂时,length -1的二进制数1都连续的位于后几位,如8是1000,而8-1就是0111。这样任何一个数和它与时,实际上就是将后几位截取了下来,而这几位就是h对length的余数。
下面是存储新key过程:
/**
* Like addEntry except that this version is used when creating entries
* as part of Map construction or "pseudo-construction" (cloning,
* deserialization). This version needn't worry about resizing the table.
*
* Subclass overrides this to alter the behavior of HashMap(Map),
* clone, and readObject.
*/
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}Entry类里面有一个next属性,作用是指向下一个Entry。打个比方, 第一个键值对A进来,通过计算其key的hash得到的index=0,记做:Entry[0] = A。一会后又进来一个键值对B,通过计算其index也等于0,现在怎么办?HashMap会这样做:B.next = A,Entry[0] = B,如果又进来C,index也等于0,那么C.next = B,Entry[0] = C;这样我们发现index=0的地方其实存取了A,B,C三个键值对,他们通过next这个属性链接在一起。所以疑问不用担心。也就是说数组中存储的是最后插入的元素。到这里为止,HashMap的大致实现,我们应该已经清楚了。
引用:http://my.oschina.net/zhenglingfei/blog/403146
引用:http://blog.csdn.net/lclai/article/details/6195104
引用:http://blog.csdn.net/vking_wang/article/details/14166593

相关文章推荐
- c语言实现hashmap(转载)
- Windows Powershell使用哈希表
- 探索PowerShell (八) 数组、哈希表(附:复制粘贴技巧)
- 轻松学习C#的哈希表
- PHP实现的一致性哈希算法完整实例
- Equals和==的区别 公共变量和属性的区别小结
- JS hashMap实例详解
- 解析WeakHashMap与HashMap的区别详解
- java String 类的一些理解 关于==、equals、null
- 全面解析Java中的HashMap类
- hashCode方法的使用讲解
- C#使用Equals()方法比较两个对象是否相等的方法
- PHP内核探索:哈希表碰撞攻击原理
- php-perl哈希算法实现(times33哈希算法)
- 基于Java HashMap的死循环的启示详解
- C#值类型、引用类型中的Equals和==的区别浅析
- Java中HashMap和Hashtable的区别浅析
- 重载toString实现JS HashMap分析
- Android中实现HashMap排序的方法
- php内核解析:PHP中的哈希表