spider/pyspider基础
2016-06-13 00:00
211 查看
一、爬虫的基本思路(以下内容选自《知乎》)
链接:http://www.zhihu.com/question/20899988/answer/24923424想象你是一只蜘蛛,现在你被放到了互联“网”上。那么,你需要把所有的网页都看一遍。怎么办呢?没问题呀,你就随便从某个地方开始,比如说人民日报的首页,这个叫initial pages,用$表示吧。
在人民日报的首页,你看到那个页面引向的各种链接。于是你很开心地从爬到了“国内新闻”那个页面。太好了,这样你就已经爬完了俩页面(首页和国内新闻)!暂且不用管爬下来的页面怎么处理的,你就想象你把这个页面完完整整抄成了个html放到了你身上。
突然你发现, 在国内新闻这个页面上,有一个链接链回“首页”。作为一只聪明的蜘蛛,你肯定知道你不用爬回去的吧,因为你已经看过了啊。所以,你需要用你的脑子,存下你已经看过的页面地址。这样,每次看到一个可能需要爬的新链接,你就先查查你脑子里是不是已经去过这个页面地址。如果去过,那就别去了。
好的,理论上如果所有的页面可以从initial page达到的话,那么可以证明你一定可以爬完所有的网页。
那么在python里怎么实现呢?
很简单
>
import Queue > initial_page = "http://www.renminribao.com" > url_queue = Queue.Queue() seen = set() > seen.insert(initial_page) url_queue.put(initial_page) > while(True): #一直进行直到海枯石烂 if url_queue.size()>0: current_url = url_queue.get() #拿出队例中第一个的url store(current_url) #把这个url代表的网页存储好 for next_url in extract_urls(current_url): #提取把这个url里链向的url if next_url not in seen: seen.put(next_url) url_queue.put(next_url) else: break
二.什么是pyspider?
pyspider是用python实现的爬虫框架。基于这个框架开发爬虫功能可以简化开发工作。它具有以下优点:
(1)使用Python为pysider写脚本,可以方便地使用python的各种库,支持python 2&3版本
(2)提供工程管理,每个工程又分为多个任务。每个任务具有优先级、重试、周期性运行、重新爬取等特性
(3)提供功能强大的WebUI,可以用于编译脚本、爬虫任务监控、工程管理以及浏览结果
(4)可以使用多种数据库存储结果:MySQL, MongoDB, Redis, SQLite, PostgreSQL with SQLAlchemy
(5)可以结合使用多种消息队列:RabbitMQ, Beanstalk, Redis and Kombu
(6)分布式的结构,支持爬取JS页面,支持python 2&3版本.
安装pyspider:
yum install pyspider //redhat
使用pyspider生成一个最简单的最爬虫:
step1: ./pyspider

step2: 打开浏览器,输出127.0.0.1:5000
step3:点击create,创建一个工程,填入工程名与initial page
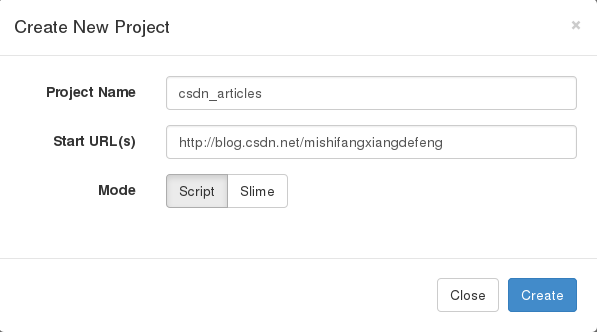
step4:pysider生成了一段默认代码,这段的代码是什么意思以及怎么运行,将在后面介绍。
如果需要设置代理的可以在这里改一下代码:
crawl_config = {
"proxy":"local_proxy:8080",
}step6 右上角save
运行效果:
分析initial page中所有链接,并提取链接的url和title
运行第一个爬虫程序
运行的方法有两种:直接运行和单步跟踪,这里讲“单步跟踪”
step1:左下角切到follow

step2:上方点击run,将看到程序运行的第一个结果,这就一开始提供的initial page

step3:点击右边绿色的播放按钮,又得到了一大批链接,这些链接都是从initial page页面解析出来的
step4:在这批页面中随意选择一个,点击它右边的播放按钮,将看到类似这样的打印

运行结束
代码解释:
@every(minutes=24 * 60) #该工程每天启动一次
def on_start(self): #onstart是入口函数
#使用self.index_page 函数来处理'http://blog.csdn.net/mishifangxiangdefeng'页面
self.crawl('http://blog.csdn.net/mishifangxiangdefeng', callback=self.index_page)
@config(age=10 * 24 * 60 * 60) #有效期10天
def index_page(self, response):
# 在 pyspider 中,内置了 response.doc 的 PyQuery 对象,让你可以使用类似 jQuery 的语法操作 DOM 元素。
for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page) #self.detail_page函数来处理该页面中所有的链接
@config(priority=2)
def detail_page(self, response): #解析内面的信息
return {
"url": response.url,
"title": response.doc('title').text(),
}

相关文章推荐
- HDU1325 Is It A Tree?
- 算法导论 第13章 红黑树
- Linux0.12-文件系统-系统调用接口
- HDU1575 Tr A 矩阵应用
- Ubuntu
- 算法导论 第7章 快速排序
- 算法导论 第12章 二叉查找树
- 算法导论-24.2-有向无回路图中的单源最短路径
- linux中内存泄漏的检测(二)定制化的malloc/free
- 1133catalan数二维变种
- 复制构造函数总结
- 算法导论 第10章 10.1 栈和队列
- 1.最简单的操作系统(二)makefile
- 静态库的符号解析和重定义处理策略
- 算法导论 11.1-4 大数组的直接寻址表
- 算法导论-14-1-最大重叠点
- HDOJ 2438 三分查找
- 随便记一下j
- CSMA/CD(多路访问/冲突检测)
- HDU2544用矩阵实现的Dijkstra