单样本和两样本的统计推断:置信区间和假设检验
2016-06-12 20:44
651 查看
《商务与经济统计学》读书笔记 6
点估计:用一个数值来估计总体参数。
置信系数(confidence coefficient):置信区间包含总体参数的概率。
置信水平(confidence level):置信系数的百分比表示形式。
常见目标参数
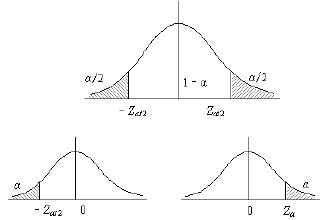
对于正太分布(z分布)的统计量,μ在大样本下(1−α)的置信区间
α已知:x¯±zα/2σx=x¯±zα/2σn√
α未知:x¯±zα/2σx=x¯±zα/2sn√
大样本置信区间的条件:
1.目标总体中选择一个随机样本
2.样本容量很大(n≥30)。中心极限定理,保证了x¯的抽样分布近似正态分布。
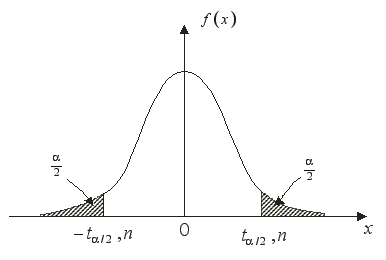
(t分布)的统计量,μ在小样本下(1−α)的置信区间
α已知:x¯±tα/2σx¯=x¯±tα/2σn√
α未知:x¯±tα/2σx=x¯±tα/2sn√
其中tα/2是基于n−1个自由度t分布中右尾面积α/2对应的t值。
小样本置信区间的条件:
1.目标总体中选择一个随机样本
2.总体相对频数分布近似于标准正态分布。
p^±zα/2σp^=p^±zα/2pqn−−−√
说明:
1.p^的抽样分布均值是p,p^是p的无偏估计值。
2.p^的抽样分布标准差是pq/n−−−−√,其中q=1−p。
3.对于大样本,p^的抽样分布是近似正太的,如果np^≥15和nq^≥15同时成立,样本被视为大样本。
大样本置信区间的条件:
1.目标总体中选择一个随机样本
2.样本容量很大(如果np^≥15和nq^≥15同时成立)。
p值调整:
当p值接近1或者0时,大样本的条件很难满足,可以对总体比例进行调整。
总体比例p调整后的置信区间。
p˘±zα/2σp˘=p˘±zα/2p˘(1−p˘)n+4−−−−−−−−√
其中,p˘=x+2n+4。
根据μ的1−α置信区间确定样本量
zα/2(σn√)=ME
则可以得到
n=(zα/2)2σ2ME2
总体比例
根据p的1−α置信区间确定样本量
zα/2(pqn−−−√)=ME
则可以得到
n=(zα/2)2pqME2
σ2的1−α的置信区间
(n−1)s2χ2α/2≤σ2≤(n−1)s2χ2(1−α/2)
χ2α/2和χ2(1−α/2)代表自由度为n−1的卡方分布右尾和左尾面积为α/2所对应的值。
σ2有效置信区间的条件:
1.从目标总体中选择一个随机样本。
2.总体的频率分布近似正太。
原假设(H0):μ=μ0
备择假设(Ha):μ≠μ0
检验统计量:z=x¯−μσx¯=x¯−μσ/n√
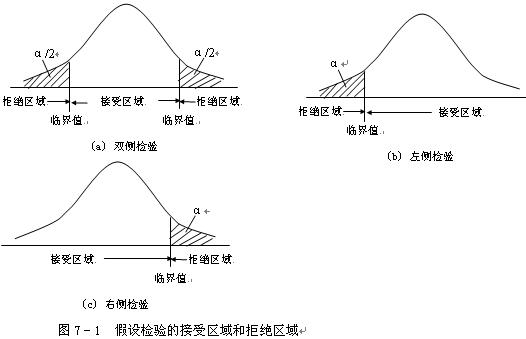
当z落在拒绝域时,我们认为这是一个小概率事件(p=α),发生的可能性非常低,因此原假设不正确,因而拒绝原假设。
当z落在接受区域,则没有充分的理由来拒绝原假设。(但是也没有充分理由接受原假设)
此时涉及两类错误:
第I类错误:H0为真的情况下拒绝原假设而接受备择假设,犯第I类错误的概率为α。
第II类错误:H0为假的情况下接受原假设,犯第II类错误的概率为β。
p值:显著性水平
1.计算z值,zp=x¯−μσx¯
2.如果是单侧检验,那么p值就是靠近备择假设区域的面积。
如备择假设是>,那么p=P(z>zp)如备择假设是<,那么p=P(z<zp);
3.如果是双侧检验,那么那么p值就是靠近备择假设区域的面积的两倍。
p=P(z>|zp|)
p值作为检验结果的优势:
1.p小于显著水平α,那么拒绝原假设。
2.可以通过p来确定能容忍的最大α值。
1.x1¯−x2¯的抽样分布均值是μ1¯−μ2¯。
2.如果两个样本相互独立,抽样分布的标准差:
σ(x¯1−x¯2)=σ21n1+σ22n2−−−−−−−−√
3.根据中心极限定理,x1¯−x2¯的抽样分布在大样本下近似服从正太分布。
独立大样本情况下μ1−μ2的置信区间:正太z
(x1¯−x2¯)±za/2(σ(x1¯−x2¯)=(x1¯−x2¯)±za/2σ21n1+σ22n2−−−−−−−√≈(x1¯−x2¯)±za/2s21n1+s22n2−−−−−−−√
独立大样本情况下μ1−μ2的假设检验:正太z
1.σ2混合样本估计量表示为s2p
s2p=(n1−1)s21+(n2−1)s22(n1−1)+(n2−1)=(n1−1)s21+(n2−1)s22(n1+n2−2)
独立小样本情况下μ1−μ2的置信区间:学生t
(x1¯−x2¯)±ta/2s2p(1n1+1n2)−−−−−−−−−−√=(x1¯−x2¯)±ta/2(n1−1)s21+(n2−1)s22(n1+n2−2)(1n1+1n2)−−−−−−−−−−−−−−−−−−−−√
独立小样本情况下μ1−μ2的假设检验:正太t
若σ21≠σ22的情况
1.样本量相同(n1=n2=n)
置信区间:(x1¯−x2¯)±ta/2(s21+s22)/n−−−−−−−−−√
H0:μ1−μ2=0下的检验统计量:t=(x1¯−x2¯)(s21+s22)/n−−−−−−−−−√
t是基于自由度v=n1+n2−2=2(n−1)。
2.样本量不相同(n1≠n2)
置信区间:(x1¯−x2¯)±ta/2(s21/n1+s22/n2)−−−−−−−−−−−−−√
H0:μ1−μ2=0下的检验统计量:t=(x1¯−x2¯)(s21/n1+s22/n2)−−−−−−−−−−−−−√
t是基于自由度v=(s21/n1+s22/n2)2(s21/n1)2n1−1+(s22/n2)2n2−1。
配对差异试验的置信区间:
配对差异试验μd=(μ1−μ2)的置信区间。
大样本
d¯±zα/2σdnd√≈d¯±zα/2σdnd√
小样本
d¯±tα/2σdnd√
其中,tα/2是基于自由度为nd−1的。
配对差异试验的假设检验:
1.p1^−p2^的抽样分布均值是p1−p2。即:
E(p1^−p2^)=p1−p2
2.如果两个样本相互独立,抽样分布的标准差:
σ(p1^−p2^)=p1q1n1+p2q2n2−−−−−−−−−−−√
3.根据中心极限定理,p1^−p2^的抽样分布在大样本下近似服从正太分布。
独立大样本情况下p1−p2的置信区间:
(p1^−p2^)±za/2σ(p1^−p2^)=(p1¯−p2¯)±za/2p1q1n1+p2q2n2−−−−−−−−−√≈(p1^−p2^)±za/2p1^q1^n1+p2^q2^n2−−−−−−−−−√
独立大样本情况下p1−p2的假设检验:正太z
根据μ1−μ2的1−α置信水平和误差限ME确定样本量
zα/2σ21n1+σ22n2−−−−−−−−√=ME
此时n=n1=n2则可以得到
n=(zα/2)2(σ21+σ212)ME2
总体比例
根据p的1−α置信区间确定样本量
zα/2p1q1n1+p2q2n2−−−−−−−−−−−√=ME
此时n=n1=n2则可以得到
n=(zα/2)2(p1q1+p2q2)ME2
1 相关概念
置信区间(confidence interval):用一个区间范围来估计总体参数,和点估计对比。点估计:用一个数值来估计总体参数。
置信系数(confidence coefficient):置信区间包含总体参数的概率。
置信水平(confidence level):置信系数的百分比表示形式。
常见目标参数
| 参数 | 概念 | 数据类型 |
|---|---|---|
| μ | 均值;平均数 | 定量 |
| p | 比例;百分比 | 定性 |
| σ2 | 方差;变异;散步 | 定量 |
2 置信区间—单样本的统计推断
2.1 大样本置信区间:正太(z)统计量
对于正太分布(z分布)的统计量,μ在大样本下(1−α)的置信区间
α已知:x¯±zα/2σx=x¯±zα/2σn√
α未知:x¯±zα/2σx=x¯±zα/2sn√
大样本置信区间的条件:
1.目标总体中选择一个随机样本
2.样本容量很大(n≥30)。中心极限定理,保证了x¯的抽样分布近似正态分布。
2.2 小样本置信区间:学生(t)统计量
(t分布)的统计量,μ在小样本下(1−α)的置信区间
α已知:x¯±tα/2σx¯=x¯±tα/2σn√
α未知:x¯±tα/2σx=x¯±tα/2sn√
其中tα/2是基于n−1个自由度t分布中右尾面积α/2对应的t值。
小样本置信区间的条件:
1.目标总体中选择一个随机样本
2.总体相对频数分布近似于标准正态分布。
2.3 大样本置信区间:总体比例(p)统计量
对于重复抽样分布(p^分布)的统计量,p的大样本下(1−α)的置信区间p^±zα/2σp^=p^±zα/2pqn−−−√
说明:
1.p^的抽样分布均值是p,p^是p的无偏估计值。
2.p^的抽样分布标准差是pq/n−−−−√,其中q=1−p。
3.对于大样本,p^的抽样分布是近似正太的,如果np^≥15和nq^≥15同时成立,样本被视为大样本。
大样本置信区间的条件:
1.目标总体中选择一个随机样本
2.样本容量很大(如果np^≥15和nq^≥15同时成立)。
p值调整:
当p值接近1或者0时,大样本的条件很难满足,可以对总体比例进行调整。
总体比例p调整后的置信区间。
p˘±zα/2σp˘=p˘±zα/2p˘(1−p˘)n+4−−−−−−−−√
其中,p˘=x+2n+4。
2.4 样本量的确定
总体均值根据μ的1−α置信区间确定样本量
zα/2(σn√)=ME
则可以得到
n=(zα/2)2σ2ME2
总体比例
根据p的1−α置信区间确定样本量
zα/2(pqn−−−√)=ME
则可以得到
n=(zα/2)2pqME2
2.5 总体方差(σ2)统计量:χ2分布
σ2的1−α的置信区间
(n−1)s2χ2α/2≤σ2≤(n−1)s2χ2(1−α/2)
χ2α/2和χ2(1−α/2)代表自由度为n−1的卡方分布右尾和左尾面积为α/2所对应的值。
σ2有效置信区间的条件:
1.从目标总体中选择一个随机样本。
2.总体的频率分布近似正太。
3 假设检验—单样本统计推断
3.1检验统计量、拒绝域及P值
检验统计量和拒绝域原假设(H0):μ=μ0
备择假设(Ha):μ≠μ0
检验统计量:z=x¯−μσx¯=x¯−μσ/n√
当z落在拒绝域时,我们认为这是一个小概率事件(p=α),发生的可能性非常低,因此原假设不正确,因而拒绝原假设。
当z落在接受区域,则没有充分的理由来拒绝原假设。(但是也没有充分理由接受原假设)
此时涉及两类错误:
第I类错误:H0为真的情况下拒绝原假设而接受备择假设,犯第I类错误的概率为α。
第II类错误:H0为假的情况下接受原假设,犯第II类错误的概率为β。
| 结论 | H0为真 | Ha为真 |
|---|---|---|
| 接受H0 | 正确决定 | 第II类错误(概率为β) |
| 拒绝H0 | 第I类错误(概率为α) | 正确决定 |
1.计算z值,zp=x¯−μσx¯
2.如果是单侧检验,那么p值就是靠近备择假设区域的面积。
如备择假设是>,那么p=P(z>zp)如备择假设是<,那么p=P(z<zp);
3.如果是双侧检验,那么那么p值就是靠近备择假设区域的面积的两倍。
p=P(z>|zp|)
p值作为检验结果的优势:
1.p小于显著水平α,那么拒绝原假设。
2.可以通过p来确定能容忍的最大α值。
3.2 假设检验:正太(z);学生(t);比例(p);总体方差
双侧检验:| 统计量 | 大样本总体均值 | 小样本总体均值 | 总体比例(p) | 总体方差 |
|---|---|---|---|---|
| 分布 | 正太(z) | 学生(t) | (p) | σ2 |
| H0 | μ=μ0 | μ=μ0 | p=p0 | σ2=σ20 |
| Ha | μ≠μ0 | μ≠μ0 | p≠p0 | σ2≠σ20 |
| 检验统计量 | z=x¯−μ0σ/n√ | t=x¯−μ0s/n√ | z=p^−p0σp^=p^−p0p0q0/n√ | χ2=(n−1)s2σ20 |
| 拒绝域 | |z|>zα/2 | |t|>tα/2 | |z|>zα/2 | χ2<χ2(1−α/2) |
4 置信区间和假设检验—两样本的统计推断
目标参数:| 参数 | 概念 | 数据类型 |
|---|---|---|
| μ1−μ2 | 均值差;平均上的差异 | 定量 |
| p1−p2 | 比例差;百分比差;比率差 | 定性 |
| σ21/σ22 | 方差比值;变异差异 | 定量 |
4.1 大样本总体均值
x1¯−x2¯抽样分布性质1.x1¯−x2¯的抽样分布均值是μ1¯−μ2¯。
2.如果两个样本相互独立,抽样分布的标准差:
σ(x¯1−x¯2)=σ21n1+σ22n2−−−−−−−−√
3.根据中心极限定理,x1¯−x2¯的抽样分布在大样本下近似服从正太分布。
独立大样本情况下μ1−μ2的置信区间:正太z
(x1¯−x2¯)±za/2(σ(x1¯−x2¯)=(x1¯−x2¯)±za/2σ21n1+σ22n2−−−−−−−√≈(x1¯−x2¯)±za/2s21n1+s22n2−−−−−−−√
独立大样本情况下μ1−μ2的假设检验:正太z
| 单侧检验 | 双侧检验 | |
|---|---|---|
| H0 | μ1−μ2=D0 | μ1−μ2=D0 |
| Ha | μ1−μ2<D0(或μ1−μ2>D0) | μ1−μ2≠D0 |
| 检验统计量z | z=(x1¯−x2¯)−D0σ(x¯1−x¯2)=(x1¯−x2¯)−D0σ21n1+σ22n2√≈(x1¯−x2¯)−D0s21n1+s22n2√ | |
| 拒绝域 | z<−zα或z>zα | |z|>zα/2 |
| 有效大样本统计推断条件 | 1.两个样本独立的方式从总体中随机抽取 2样本量n1和n2都很大。 |
4.2 小样本总体均值
混合样本估计量s2p1.σ2混合样本估计量表示为s2p
s2p=(n1−1)s21+(n2−1)s22(n1−1)+(n2−1)=(n1−1)s21+(n2−1)s22(n1+n2−2)
独立小样本情况下μ1−μ2的置信区间:学生t
(x1¯−x2¯)±ta/2s2p(1n1+1n2)−−−−−−−−−−√=(x1¯−x2¯)±ta/2(n1−1)s21+(n2−1)s22(n1+n2−2)(1n1+1n2)−−−−−−−−−−−−−−−−−−−−√
独立小样本情况下μ1−μ2的假设检验:正太t
| 单侧检验 | 双侧检验 | |
|---|---|---|
| H0 | μ1−μ2=D0 | μ1−μ2=D0 |
| Ha | μ1−μ2<D0(或μ1−μ2>D0) | μ1−μ2≠D0 |
| 检验统计量t | t=(x1¯−x2¯)−D0s2p(1n1+1n2)√ | |
| 拒绝域 | t<−tα或t>tα | |t|>tα/2 |
| 有效大样本统计推断条件 | 1.两个样本独立的方式从两个目标总体中随机抽取 2两个被抽样的总体近似服从正态分布 3两个总体具有相同的方差(σ21=σ22) |
1.样本量相同(n1=n2=n)
置信区间:(x1¯−x2¯)±ta/2(s21+s22)/n−−−−−−−−−√
H0:μ1−μ2=0下的检验统计量:t=(x1¯−x2¯)(s21+s22)/n−−−−−−−−−√
t是基于自由度v=n1+n2−2=2(n−1)。
2.样本量不相同(n1≠n2)
置信区间:(x1¯−x2¯)±ta/2(s21/n1+s22/n2)−−−−−−−−−−−−−√
H0:μ1−μ2=0下的检验统计量:t=(x1¯−x2¯)(s21/n1+s22/n2)−−−−−−−−−−−−−√
t是基于自由度v=(s21/n1+s22/n2)2(s21/n1)2n1−1+(s22/n2)2n2−1。
4.3 配对差异试验
对于某些情况,由于某些原因不再符合独立样本,比如考察毕业生男生和女生工资薪酬均值差,如果是独立样本,结果可能因为专业和平均成绩差异而变化比较大,因此可以根据专业和平均成绩进行匹配。配对差异试验的置信区间:
配对差异试验μd=(μ1−μ2)的置信区间。
大样本
d¯±zα/2σdnd√≈d¯±zα/2σdnd√
小样本
d¯±tα/2σdnd√
其中,tα/2是基于自由度为nd−1的。
配对差异试验的假设检验:
| 单侧检验 | 双侧检验 | |
|---|---|---|
| H0 | μd=D0 | μd=D0 |
| Ha | μd<D0(或μd>D0) | μd≠D0 |
| 大样本 | ||
| 检验统计量z | z=d¯−D0σd/nd√≈d¯−D0sd/nd√ | |
| 拒绝域 | z<−zα或z>zα | |z|>zα/2 |
| 有效大样本统计推断条件 | 1随机样本差值是从两个目标总体中随机抽取 2样本量nd很大(σ21=σ22) | |
| 小样本 | ||
| 检验统计量t | t=d¯−D0sd/nd√ | |
| 拒绝域 | t<−tα或t>tα | |t|>tα/2 |
| 有效小样本统计推断条件 | 1.随机样本差值是从两个目标总体中随机抽取 2总体差异近似服从正态分布 |
4.3 总体比例
p1^−p2^抽样分布性质1.p1^−p2^的抽样分布均值是p1−p2。即:
E(p1^−p2^)=p1−p2
2.如果两个样本相互独立,抽样分布的标准差:
σ(p1^−p2^)=p1q1n1+p2q2n2−−−−−−−−−−−√
3.根据中心极限定理,p1^−p2^的抽样分布在大样本下近似服从正太分布。
独立大样本情况下p1−p2的置信区间:
(p1^−p2^)±za/2σ(p1^−p2^)=(p1¯−p2¯)±za/2p1q1n1+p2q2n2−−−−−−−−−√≈(p1^−p2^)±za/2p1^q1^n1+p2^q2^n2−−−−−−−−−√
独立大样本情况下p1−p2的假设检验:正太z
| 单侧检验 | 双侧检验 | |
|---|---|---|
| H0 | p1−p2=0 | p1−p2=0 |
| Ha | p1−p2<0(或p1−p2>0) | p1−p2≠0 |
| 检验统计量z | z=(p1^−p2^)σ(x^1−x^2)=(p1^−p2^)p1q1n1+p2q2n2√≈(p1^−p2^)p1^q1^n1+p2^q2^n2√ | |
| 拒绝域 | z<−zα或z>zα | |z|>zα/2 |
| 有效大样本统计推断条件 | 1.两个样本独立的方式从总体中随机抽取 2样本量n1和n2都很大(n1p^1≥15,n2p^2≥15)。 |
4.4 样本量确定
总体均值根据μ1−μ2的1−α置信水平和误差限ME确定样本量
zα/2σ21n1+σ22n2−−−−−−−−√=ME
此时n=n1=n2则可以得到
n=(zα/2)2(σ21+σ212)ME2
总体比例
根据p的1−α置信区间确定样本量
zα/2p1q1n1+p2q2n2−−−−−−−−−−−√=ME
此时n=n1=n2则可以得到
n=(zα/2)2(p1q1+p2q2)ME2
4.5 总体方差:两样本
独立大样本情况下相等方差的F假设检验:F| 单侧检验 | 双侧检验 | |
|---|---|---|
| H0 | σ21=σ22 | σ21=σ22 |
| Ha | σ21<σ22或(σ21>σ22) | σ21≠σ22 |
| 检验统计量F | F=s22s21(或F=s21s22) | F=较大的样本方差较小的样本方差 |
| 拒绝域 | F>Fα | F>Fα/2 |
| 有效大样本统计推断条件 | 1.被抽样的总体服从正态分布 样本随机且独立。 |

相关文章推荐
- 拖延良久,终于开始了博客之旅(preference)
- 1111
- Java里length,length(),size()区别
- Perl中删除或替换字符串中特殊字符(如空格)的方法
- [置顶] 台大机器学习笔记-Kernel 支持向量机
- 【忽略】Python操作数据库
- [Android]使用Intent跳转至桌面首页
- Spring 事务
- Python 偏函数
- JZOJ 4485【GDOI 2016 Day1】第一题 中学生数学题
- $a && $b = $c的问题
- sqlite3使用简介
- window下systemc的环境搭建
- c++11多线程简介
- centos下使用yum 安装percona xtrabackup
- Java配置环境变量
- 试问CodeFile、CodeBehind深几许?
- 本周学习进度
- 所有排序算法
- 《JAVA与模式》之策略模式