比较排序
2016-06-11 19:00
344 查看
比较排序的性质
在算法最终得到的排序结果,依赖于各个元素直接的比较。简言之就是需要对每个元素对比大小关系来进行排序。常见常用的比较排序有冒泡排序、选择排序、插入排序、归并排序、堆排序、快速排序。
这些排序的时间复杂度各不相同,各有优缺点。
冒泡排序

图片来自Wikipedia
一种简单、易想的排序,但效率很差。
平均时间复杂度为O(n²)
template <class T>
void swap(T *a, T *b) {
if (a != b) {
T temp = *a;
*a = *b;
*b = temp;
}
}
template <class T>
void bubbleSort(T *arr, int len) {
for (int i = 0; i < len - 1; i++)
for (int j = len - 1; j > i; j--)
if (arr[j] < arr[j - 1])
swap(&arr[j], &arr[j - 1]);
}选择排序

图片来自Wikipedia
另一种简单、易想的排序,同样冒泡排序一样,效率很差
平均时间复杂度为O(n²)
template <class T>
void swap(T *a, T *b) {
if (a != b) {
T temp = *a;
*a = *b;
*b = temp;
}
}
template <class T>
void selectionSort(T *arr, int len) {
for (int i = 0; i < len - 1; i++) {
int min_index = i;
for (int j = i + 1; j < len; j++)
if (arr[j] < arr[min_index])
min_index = j;
if (i != min_index)
swap(&arr[i], &arr[min_index]);
}
}插入排序
图片来自Wikipedia
其思想就类似于我们打牌的时候,把牌拿起来,插入手里的牌中,然后排序。
最好的情况,即给定的一组元素已经排好序(升序),此时时间复杂度为Θ(n)
平均时间复杂度为O(n²)
最坏的情况下也是Θ(n²),但花销比平均要大。
对于少量元素,这种排序效率还算不错,优于冒泡排序和选择排序。
template <class T>
void swap(T *a, T *b) {
if (a != b) {
T temp = *a;
*a = *b;
*b = temp;
}
}
template <class T>
void insertSort(T *arr, int len) {
for (int j = 1; j < len; j++) {
T key = arr[j];
int i = j - 1;
while (i >= 0 && arr[i] > key) {
arr[i + 1] = arr[i];
i--;
}
arr[i + 1] = key;
}
}归并排序
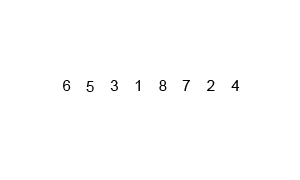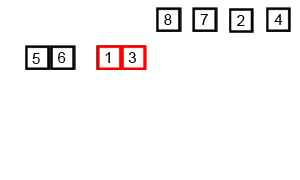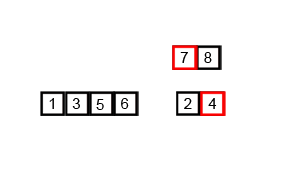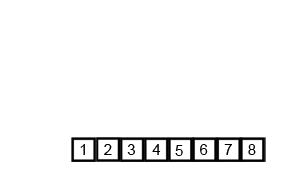
图片来自Wikipedia
归并排序将一个大数组不断分解成多个小数组,然后再将小数组有序地合并起来。
前面提到的三种算法以及下面要提到的堆排序和快速排序都是原址的,而归并排序不是原址的。
什么叫原址?就是在数组原先的空间中。归并排序在分解为小数组的时候需要创建新的数组,这样就没有维持原址了。
平均时间复杂度为O(nlgn),而且非常稳定,即使在最坏的情况下也是O(nlgn)
template <class T>
void merge(T *arr, int first, int mid, int last) {
int left_len = mid - first + 1;
int right_len = last - mid;
T *left_arr = new T[left_len];
T *right_arr = new T[right_len];
for (int i = 0; i < left_len; i++)
left_arr[i] = arr[first + i];
for (int i = 0; i < right_len; i++)
right_arr[i] = arr[mid + i + 1];
int left_index = 0;
int right_index = 0;
int index = 0;
for (index = first; index <= last; index++) {
// If one of the two arrays reaches the end, jump out.
if (left_index == left_len || right_index == right_len)
break;
if (left_arr[left_index] <= right_arr[right_index]) {
arr[index] = left_arr[left_index];
++left_index;
} else {
arr[index] = right_arr[right_index];
++right_index;
}
}
/** Only one of the two loops below will be executed.
* Beacuse the jumping-out condition of the loop above is that
* one of the two arrays reaches the end.
* Although the rest part of one of the two arrays is not sorted,
* the array still can be sorted by next merge.
*/
// The rest part of left_arr should be pushed into arr.
for (int i = left_index; i < left_len; i++) {
arr[index] = left_arr[i];
++index;
}
// The rest part of right_arr should be pushed into arr.
for (int i = right_index; i < right_len; i++) {
arr[index] = right_arr[i];
++index;
}
delete[] left_arr;
delete[] right_arr;
}
template <class T>
void mergeSort(T *arr, int first, int last) {
if (first < last) {
int mid = (last + first) / 2;
mergeSort(arr, first, mid);
mergeSort(arr, mid + 1, last);
merge(arr, first, mid, last);
}
}堆排序
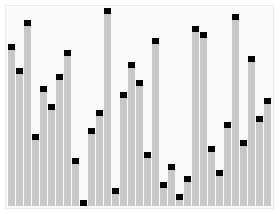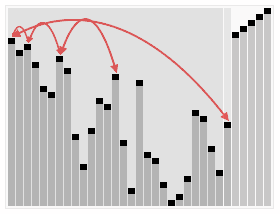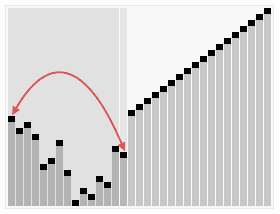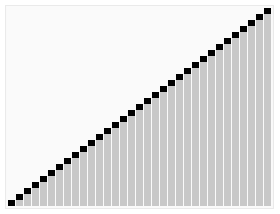
图片来自Wikipedia
堆排序使用到堆这种数据结构。
堆是一种以二叉树为基础的数据结构,它满足如下性质:(高度为h)
1. 从根节点至h-1层是完全树
2. 所有的叶子节点只存在于h与h-1层上
3. 所有到达h层叶子节点的路径都在到达h-1层叶子节点路径的左侧
堆有两种常用的形式最大堆和最小堆。
最大堆的每一个结点的值都比子节点的值要大。
最小堆的每一个结点的值都比子节点的值要小。
将数组转换为堆,只需这么考虑
每个元素arr[i]的parent结点是arr[i / 2]
每个元素的left结点是arr[i * 2],right结点是arr[i * 2 + 1]
除了将数组转换为堆,还得是最大堆。因此构造堆的时候需要构造一个最大堆。
排序的过程就是取出堆的根节点,然后重新让堆具有最大堆性质。
template <class T>
void swap(T *a, T *b) {
if (a != b) {
T temp = *a;
*a = *b;
*b = temp;
}
}
int parent(int i) { return i >> 1; } // i / 2
int left(int i) { return i << 1; } // i * 2
int right(int i) { return (i << 1) | 1; } // i * 2 + 1
// Find the max among arr[i], the left and right nodes of arr[i]
// Using recursion because the subtree down the node arr[i] may object the rules of maximal heap
template <class T>
void max_heapify(T *arr, int heapsize, int i) {
int l = left(i);
int r = right(i);
int largest = 0;
if (l < heapsize && arr[l] > arr[i])
largest = l;
else
largest = i;
if (r < heapsize && arr[r
4000
] > arr[largest])
largest = r;
if (largest != i) {
swap(&arr[i], &arr[largest]);
max_heapify(arr, heapsize, largest);
}
}
// left = 2i, right = 2, so we just need to start from the middle place of the array
template <class T>
void build_max_heap(T *arr, int len) {
for (int i = len / 2 - 1; i >= 0; i--)
max_heapify(arr, len, i);
}
template <class T>
void heapSort(T *arr, int len) {
int heapsize = len;
build_max_heap(arr, heapsize);
for (int i = len - 1; i >= 1; i--) {
swap(&arr[0], &arr[i]);
--heapsize;
max_heapify(arr, heapsize, 0);
}
}堆排序的执行过程
构造最大堆:
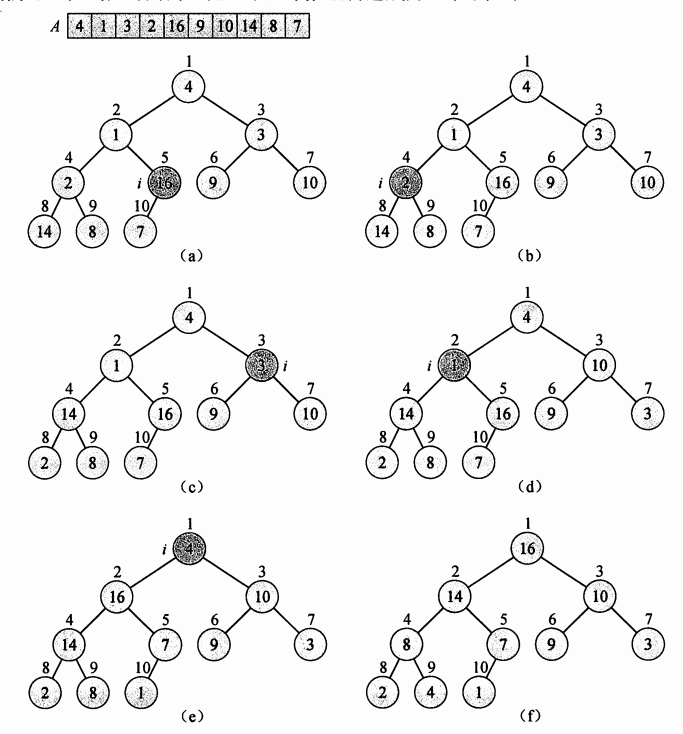
图片来自《算法导论》
排序:
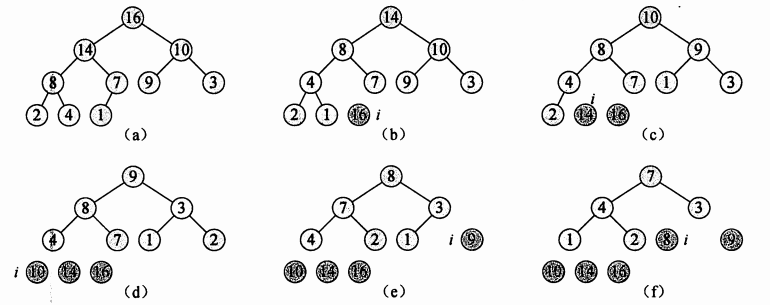
图片来自《算法导论》
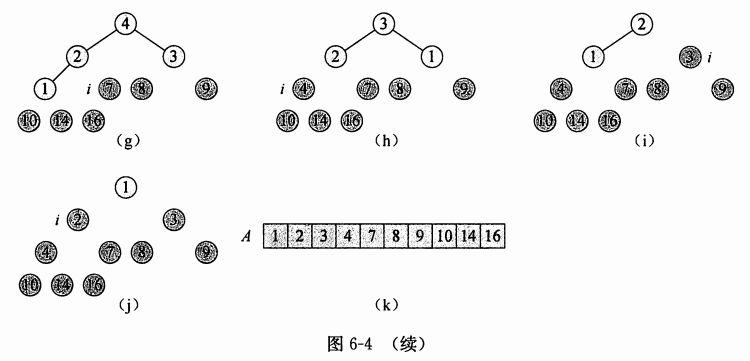
图片来自《算法导论》
快速排序
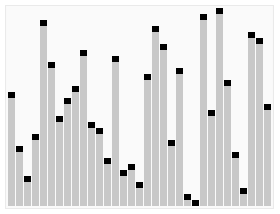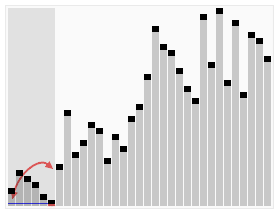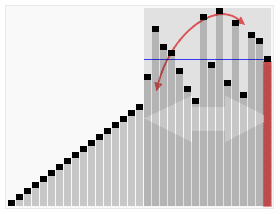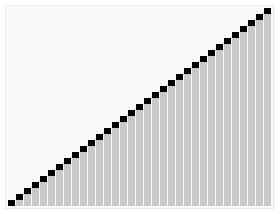
快速排序运用到了分治策略。
寻找分界点,然后根据分界点将大数组分为小数组,在分界点左侧所有数字小于分界点,在分界点右侧所有数组大于分界点
平均时间复杂度为O(nlgn)
但是最坏的情况,即已经是给定排好序的数组(不论升序降序)时,时间复杂度为O(n²)
template <class T>
void swap(T *a, T *b) {
if (a != b) {
T temp = *a;
*a = *b;
*b = temp;
}
}
template<class T>
int partition(T *arr, int first, int last) {
int pivot = arr[last];
int swap_candidate = first - 1;
for (int i = first; i <= last - 1; i++) {
if (arr[i] < pivot) {
++swap_candidate;
swap(&arr[swap_candidate], &arr[i]);
}
}
swap(&arr[swap_candidate + 1], &arr[last]);
return (swap_candidate + 1);
}
template <class T>
void quickSort(T *arr, int first, int last) {
if (first < last) {
int mid = partition(arr, first, last);
quickSort(arr, first, mid - 1);
quickSort(arr, mid + 1, last);
}
} 时间对比
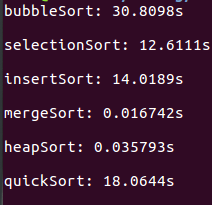
平均状况下,使用一个数据规模为10万的数组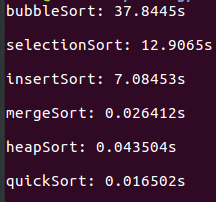
冒泡排序花的时间明显大于其他排序,原因就在于冒泡排序里面频繁的swap操作。
在这样的结果中,大致可以得出一个结论就是,多数情况下,快速排序是效率最好的比较排序。
如果给定一个已经降序排列的数组,结果会怎么样呢?
快速排序的效率变得很低,时间花销超过了选择排序和插入排序。而归并排序和堆排序保持稳定。
参考书籍
《算法导论》
相关文章推荐
- 插入排序
- 堆排序
- 快速排序
- 书评:《算法之美( Algorithms to Live By )》
- 动易2006序列号破解算法公布
- Ruby实现的矩阵连乘算法
- C#插入法排序算法实例分析
- 超大数据量存储常用数据库分表分库算法总结
- C#数据结构与算法揭秘二
- C#冒泡法排序算法实例分析
- C#快速排序算法实例分析
- C#堆排序实现方法
- 算法练习之从String.indexOf的模拟实现开始
- C#算法之关于大牛生小牛的问题
- C#实现的算24点游戏算法实例分析
- 经典排序算法之冒泡排序(Bubble sort)代码
- c语言实现的带通配符匹配算法
- 浅析STL中的常用算法
- 算法之排列算法与组合算法详解
- C++实现一维向量旋转算法