初试scrapy编写twitter爬虫
2016-06-09 21:42
781 查看
这篇文章记录的是我研究整个问题的思路,最终做出来的东西在1.4.2节
第一步要做的当然是生成一个新project
第一步要做的当然是生成一个新project
scrapy startproject twitterProject我计划用这个爬虫做的第一件事就是抓取twitter上希拉里的推文以及她的关注。所以新建一个spider
scrapy genspider hillary https://twitter.com/HillaryClinton[/code] 本文首先参考 https://github.com/yall/scrapy-twitter 中的代码进行学习1.登陆
twitter是不能直接访问的,所有内容都必须在注册账号并登陆后才能查看。所以写twitter爬虫的第一步就是实现用scrapy登陆并返回url。
根据 https://github.com/yall/scrapy-twitter 中的说明,需要先在settings中设置 API credentials 并且把TwitterDownloaderMiddleware加入到settings中。
根据这个github上的说明,settings中的设置如下:DOWNLOADER_MIDDLEWARES = { 'scrapy_twitter.TwitterDownloaderMiddleware': 10, } TWITTER_CONSUMER_KEY = 'xxxx' TWITTER_CONSUMER_SECRET = 'xxxx' TWITTER_ACCESS_TOKEN_KEY = 'xxxx' TWITTER_ACCESS_TOKEN_SECRET = 'xxxx'那么首先应该弄清CONSUMER_KEY 到 ACCESS_TOKEN_SECRET 这四个变量是做什么的。
想起原来没看完的Web Scraping with Python上有关于twitter API的内容,再捡起来看看。1.1 twitter api
登陆twitter之后打开twitter的developer site:apps.twitter.com
Create一个新的App。起名叫ScrapingXYZ。输入description及web site 后就进入了编辑应用的界面。
在Keys and Access Tokens下应该就能找到我们想要的四个变量。
果然,CONSUMER_KEY 和 CONSUMER_SECRET就在这页选项卡的开头,而TOKEN_KEY和TOKEN_SECRET需要点击一下页面最下方的generate My Access Token and Token Secret按钮来生成。1.2 user Timeline example
这篇github文章中给出地第一个spider例子用于抓取一个用户时间线上的所有推文。
下面分析一下这个spider的代码。
其代码如下:(源码可以在此处获得:https://github.com/yall/scrapy-twitter)
scrapy_twitter.py:# coding:utf-8 from scrapy import log from scrapy.http import Request, Response import twitter class TwitterUserTimelineRequest(Request): def __init__(self, *args, **kwargs): self.screen_name = kwargs.pop('screen_name', None) self.count = kwargs.pop('count', None) self.max_id = kwargs.pop('max_id', None) super(TwitterUserTimelineRequest, self).__init__('http://twitter.com', dont_filter=True, **kwargs) class TwitterStreamFilterRequest(Request): def __init__(self, *args, **kwargs): self.track = kwargs.pop('track', None) super(TwitterStreamFilterRequest, self).__init__('http://twitter.com', dont_filter=True, **kwargs) class TwitterResponse(Response): def __init__(self, *args, **kwargs): self.tweets = kwargs.pop('tweets', None) super(TwitterResponse, self).__init__('http://twitter.com', *args, **kwargs) class TwitterDownloaderMiddleware(object): def __init__(self, consumer_key, consumer_secret, access_token_key, access_token_secret): self.api = twitter.Api(consumer_key=consumer_key, consumer_secret=consumer_secret, access_token_key=access_token_key, access_token_secret=access_token_secret) log.msg('Using creds [CONSUMER KEY: %s, ACCESS TOKEN KEY: %s]' % (consumer_key, access_token_key), level=log.INFO) @classmethod def from_crawler(cls, crawler): settings = crawler.settings consumer_key = settings['TWITTER_CONSUMER_KEY'] consumer_secret = settings['TWITTER_CONSUMER_SECRET'] access_token_key = settings['TWITTER_ACCESS_TOKEN_KEY'] access_token_secret = settings['TWITTER_ACCESS_TOKEN_SECRET'] return cls(consumer_key, consumer_secret, access_token_key, access_token_secret) def process_request(self, request, spider): if isinstance(request, TwitterUserTimelineRequest): tweets = self.api.GetUserTimeline(screen_name=request.screen_name, count=request.count, max_id=request.max_id) return TwitterResponse(tweets=[tweet.AsDict() for tweet in tweets]) if isinstance(request, TwitterStreamFilterRequest): tweets = self.api.GetStreamFilter(track=request.track) return TwitterResponse(tweets=tweets) def process_response(self, request, response, spider): return response from scrapy.item import DictItem, Field def to_item(dict_tweet): field_list = dict_tweet.keys() fields = {field_name: Field() for field_name in field_list} item_class = type('TweetItem', (DictItem,), {'fields': fields}) return item_class(dict_tweet)
1-6行:导入所需模块。根据scrapy1.1.0的文档,新版本的scrapy中scrapy.log模块已经没有了,取而代之的是用Python内建的logging模块来进行日志记录。所以 “from scrapyimport log” 这行命令以后应该需要改成 “import logging”,并对下面相关的代码进行修改。
9-17行:
User Timeline:import scrapy from scrapy_twitter import TwitterUserTimelineRequest, to_item class UserTimelineSpider(scrapy.Spider): name = "user-timeline" allowed_domains = ["twitter.com"] def __init__(self, screen_name = None, *args, **kwargs): if not screen_name: raise scrapy.exceptions.CloseSpider('Argument scren_name not set.') super(UserTimelineSpider, self).__init__(*args, **kwargs) self.screen_name = screen_name self.count = 100 def start_requests(self): return [ TwitterUserTimelineRequest( screen_name = self.screen_name, count = self.count) ] def parse(self, response): tweets = response.tweets for tweet in tweets: yield to_item(tweet) if tweets: yield TwitterUserTimelineRequest( screen_name = self.screen_name, count = self.count, max_id = tweets[-1]['id'] - 1)
未完待续1.3 Learning Scrapy:Ch5 Quick Spider Recipes - A spider that logs in
上面两段代码不懂的地方太多了,也许应该先回到 Learn Scrapy 这本书看看其中的 A spider that logs in 一节,并按其中的思路对twitter的网页进行分析。
首先打开网页 https://twitter.com 可以看见输入用户名和密码的输入框以及登录按钮。第一步需要做的就是把这三块提取出来并用scrapy完成再返回相应的Request。
如果登陆成功那么页面会跳转到自己的主页,然而网页的url保持不变。
如果登录失败,页面会跳转到一个提示登录失败并要求重新输入用户名和密码的网页:https://twitter.com/login/error?redirect_after_login=%2F
未完待续1.4 另一个网上的例子
详见此网页:https://blog.scrap
4000
inghub.com/2012/10/26/filling-login-forms-automatically/1.4.1 using loginform
招其中的例子写了一个名为 login 的 spider,代码如下:# -*- coding: utf-8 -*- from scrapy.spider import BaseSpider from scrapy.http import FormRequest from loginform import fill_login_form class LoginSpider(BaseSpider): name = "login" #allowed_domains = ["twitter.com"] start_urls = ( 'https://twitter.com/', ) login_user = "xxxxx" login_pass = "xxxxx" def parse(self, response): args, url, method = fill_login_form(response.url, response.body, self.login_user, self.login_pass) return FormRequest(url, method=method, formdata=args, callback=self.after_login) def after_login(self, response): print('We logged in!')运行时会报错:exceptions.ImportError: No module named middlewares
之后我又看了一下,出现上面这个错误的原因是因为我在settings.py中把DOWNLOADER_MIDDLEWARE激活了,然而事实上并没有写相应的middleware。所以注释掉那部分:DOWNLOADER_MIDDLEWARES = { 'scrapy_twitter.TwitterDownloaderMiddleware': 10, } TWITTER_CONSUMER_KEY = 'xxxx' TWITTER_CONSUMER_SECRET = 'xxxx' TWITTER_ACCESS_TOKEN_KEY = 'xxxx' TWITTER_ACCESS_TOKEN_SECRET = 'xxxx'
之后就没有这个错误了。1.4.2 Only FormRequest(只看这个就好了)
这是一个处理登陆的包,上面一个例子中用到了。
为了学习这个包我又改了一下login这个spider:# -*- coding: utf-8 -*- import scrapy class LoginSpider(scrapy.Spider): name = "login" # allowed_domains = ["twitter.com"] start_urls = ( 'https://github.com/login', ) http_user = "xxxxx" http_pass = "xxxxx" def parse(self, response): return scrapy.FormRequest.from_response( response, formdata={'username': self.http_user, 'password': self.http_pass}, callback=self.after_login ) def after_login(self, response): print(response.xpath('//a'))
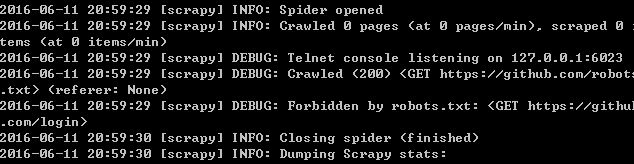
shell中运行时有个问题:
Forbidden by robots.txt
上网找到一个解决方法,
就是在settings.py中进行如下改变:ROBOTSTXT_OBEY=false
然后在shell中再运行spider,现在运行似乎没有错误,但是好像返回的并不像我想的那样是跳转后的页面:
然后找到两一个和解决这个问题相关的帖子: http://stackoverflow.com/questions/31919069/scrapy-recursive-website-crawl-after-login
用处不大。
在以下这个网址找到一个解决方法。 http://stackoverflow.com/questions/30746820/python-scrapy-login-redirecting-problems http://stackoverflow.com/questions/5850755/using-scrapy-with-authenticated-logged-in-user-session(这个链接是最重要的)
在参考这个解决方法后又写了一个登陆github的spider,终于成功了!!!!
下面总结一下进过# -*- coding: utf-8 -*- import scrapy class LoginSpider(scrapy.Spider): name = "login" # allowed_domains = ["twitter.com"] start_urls = ( 'https://github.com/login', ) http_user = "xxxxx" http_pass = "xxxxx" def parse(self, response): return scrapy.FormRequest.from_response( response, formdata={'login': self.http_user, 'password': self.http_pass}, callback=self.after_login ) def after_login(self, response): print(response.body) return scrapy.Request(url="https://github.com/iam-xiaoyi-zhang/CSDN", callback=self.parse_tastypage) def parse_tastypage(self, response): print(response.xpath('(//button)[1]/@data-ga-click').extract()) print(response.xpath('(//button)[13]').extract())
简单说来,这段代码的思路如下:
1,在登录网页的源码中找到需要填写formdata的位置。
2,在能确认登陆进去的情况下,只要接着发送新的Requests,就认为是以用户的身份进行发送的。
3,在适当的callback函数中进行登陆成功的确认,我在此用的方法是试着打印一些只有登录进去的用户的页面上才显示的信息。
代码解释:
1.spider设置的登录url就是 ‘https://github.com/login’, 然后必要的两个属性肯定是用户名和密码,在此已经隐去。
2.对于start_urls中的url,返回的response的callback都是parse(),而在parse()中我们要做的肯定是用自己的用户名和密码进行登录。这时就需要用到scrapy.Request的一个子类:scrapy.FormRequest。.简单说来,这个类比scrapy.Request多的东西就是在提交request时可以顺带提交这个url可能需要的Form-Data,像用户名密码这种。
3.parse()方法:这个方法返回了一个新的Request,用到的是FormRequest中from_response()这个方法。其作用就是重新返回,加上在这个url中找到的formdata的request,并且指定其响应函数为after_login.而这一个返回的FormRequest就正是scrapy所模拟的登录操作。
4.after_login()方法:由parse的返回值得知,再返回的FormRequest得到的response将进入这个方法进行处理。这个方法只是简单地打印了一下整个response的数据,然后又返回了一个新的request,就是我github中一个特定的depository,用于存放csdn中博客用到的图片。。本没想有这么麻烦,奈何csdn没相册啊。。而且,其实我原本想再用和start_urls中一样的网址做request的,因为一旦登陆进去,这个网址显示的就是你自己的信息了,但是downloader
middleware中有一个好像能自动过滤重复的url,而我还没找到取消这个中间件的方法。
5.oarse_tastypage():这个方法就用于处理上个方法中返回的github repository的response。我之所以选择这两行打印,是因为这两行的内容如下:
第一行是Header, sign out
第二行是Create new file.
所以显而易见,只有成功登陆之后页面才会提示sign out,也才会允许访问者创建新文件。所以这步其实就是在证明我确实已经登录进去了。1.5 第二个网上的例子
然后我又偶然找到之前看过的文档中的一个loginSpider的例子,链接如下 http://doc.scrapy.org/en/latest/topics/request-response.html#topics-request-response-ref-request-userlogin
我写的代码是这样的:# -*- coding: utf-8 -*- import scrapy class LoginSpider(scrapy.Spider): name = "login" #allowed_domains = ["twitter.com"] start_urls = ( 'https://twitter.com/', ) login_user = "xxxxx" login_pass = "xxxxx" def parse(self, response): return scrapy.FormRequest.from_response( response, formdata={'username':self.login_user,'password':self.login_pass}, callback=self.after_login ) def after_login(self, response): print(response)其实只是把url和用户名密码改了一下,并且把用户名密码定义成类的属性而已。
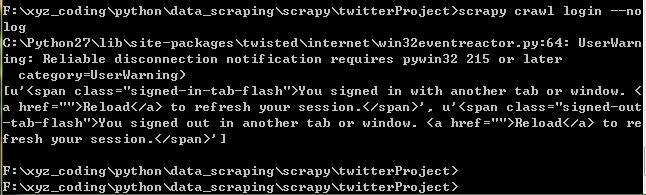
运行后也是报同样的错误。
然后为了再进一步看看这是什么样的问题,我在items.py相同的目录下建立了一个空的文件,就叫middlewares.py
再执行scrapy crawl login之后,又会有下面这个错误:exceptions.NameError: Module 'twitterProject.middlewares' doesn't define any object named 'MyCustomDownloaderMiddleware'
看来需要返回scrapy的文档看看middleware的功能和作用。
之后我又看了一下,出现之前exceptions.ImportError: No module named middlewares错误的原因是因为我在settings.py中把DOWNLOADER_MIDDLEWARE激活了,然而事实上并没有写相应的middleware。所以注释掉那部分:DOWNLOADER_MIDDLEWARES = { 'scrapy_twitter.TwitterDownloaderMiddleware': 10, } TWITTER_CONSUMER_KEY = 'xxxx' TWITTER_CONSUMER_SECRET = 'xxxx' TWITTER_ACCESS_TOKEN_KEY = 'xxxx' TWITTER_ACCESS_TOKEN_SECRET = 'xxxx'
之后就没有这个错误了。1.6 关于工作流程和middleware
1.6.1 Scrapy工作流程
在看middleware之前,先简单了解一下Scrapy的工作流程。
Scrapy的核心是Scrapy Engine,Scrapy所有重要的组成部分都与Scrapy Engine直接作用,来间接地与其它模块交流。
Scrapy的组成部分除了Engine之外还有:Spiders,Spider Middlewares,Scheduler,Downloader,Downloader Middlewares和Item Pipeline。
其中Spider Middlewares是Spider和Engine的中间件,Downloader Middlewares是Downloader和Engine的中间件。
其具体的工作流程如下:
1.首先,Engine从Spider获得第一个需要从中抓取数据的URL,然后将其排入Scheduler的队列中,这就是一个Request。
2.Engine会从Scheduler询问下一个URL
3.Scheduler会返回下一个URL到Engine,由Engine经由Downloader Middleware发送到Downloader。
4.从目标网页下载完数据之后,Downloader会生成一个包含网页内容的Response并把它经由Downloader Middleware传送回Engine。
5.Engine收到从Downloader返回的Response之后会经由Spider Middleware把它传送给Spider进行处理。
6.Spider会对Response进行处理,并把处理好的items和新生成的Requests(with url)再经由Spider Middleware传送给Engine。
7.Engine会把Spider生成的items传送给Item Pipeline进行后续处理,并把Requests传送给Scheduler。
8.整个过程从第一步开始循环,直到Scheduler中没有新的Requests了为止。1.6.2 Downloader Middleware
要使用Downloader Middleware,第一步是在settings中通过设置激活它。例如可以是如下这样:DOWNLOADER_MIDDLEWARES = { 'myproject.middlewares.CustomDownloaderMiddleware':543 }Middleware实质上是设置了一个列表列出了在response和request进行传递过程中都需要如何被处理。对于每种action,Middleware中都需要设定一个数字然后系统会根据数字的大小来依次进行操作。
在setting中可以编辑的是DOWNLOADER_MIDDLEWARE,其实Downloader Middleware还有另一部分,就是DOWNLOADER_MIDDLEWARE_BASE,其中已经列出了一系列动作,每个动作都如字典的键一样,配备了一个值,来决定执行的先后,正因此,DOWNLOADER_MIDDLEWARE中数字的大小也就非常重要。如果想disable BASE中的某个动作的话,就必须要在DOWNLOADER_MIDDLEWARE中对这个动作进行声明,然后赋值为None。
关于写自己的Downloader Middleware:
每个middelware component都是一个包含以下方法中至少一种的一个类。
这几种方法是:
process_request(request, spider)
process_response(request,response,spider)
process_exception(request,exception,spider)
其中process_request和process_response都是只要经过此middleware的request和response都要分别被调用的。
对于process_request,其返回值只能有四种,None,Response对象,Request对象,或者raise一个IgnoreRequest
如果返回值是None的话,那么Scrapy会继续处理这个Request,也就是按顺序接着让Request通过其它middleware。最后request会被downloader调用并用于抓取数据。
如果返回值是Response的话。那Scrapy就直接认为从此Request返回Response的过程已经完成了,所以也就直接把这个Response return回去。当然,在这个过程中,所有middleware的process_response方法都会被调用用来处理生成的Response。
如果返回值是Request的话,那么这个原有的request的处理将终止,并把返回的request重新放入scheduler中进行reschedule。
如果结果是生成IgnoreRequest exception的话,将会调用process_exception()方法,如果所有的middleware都没有这个方法,那么系统会调用Request.errback。而且如果所有middlewares都没有这个方法的话,那这个exception也就不会被记录到日志中。
对于process_response,其返回值有三种,Response对象,Request对象或者是一个IgnoreRequest exception。
如果返回Response,那么这是最正常的结果,这个response(有可能在处理过程中已经完全和输入的response不一样了,但这也是有可能的)会进入后续的middleware的process_response()方法进行处理。
如果返回Request,那么这个middleware链会终止,并将这个request 投入到scheduler中进行reschedule。(这和process_request()返回Request的结果是一样的)
如果生成IgnoreRequest exception,和在process_request中的结果是一样的。
对于process-exceotion,其返回值也有三种:Response,Request或None。
如果是None的话,Scrapy会继续处理这个exception,执行后续middleware中的process_exception方法。
如果返回Response的话,middleware中的process_response()链会启动,来处理这个response。
如果返回Request的话,这个request会被reschedule回scheduler中,并且执行process_exception的链会中止。
所有内建的downloader middleware详见下面的Scrapy文档链接: http://doc.scrapy.org/en/latest/topics/downloader-middleware.html
下面对每个built-in middleware进行简要说明:
CookiesMiddleware:用于需要cookies的站点,功能室跟踪服务器发出的cookies并把它们随request发回。
DefaultHeadersMiddleware:此中间件按照setting中的DEFAULT_REQUEST_HEADERS来设置request header。
HttpAuthMiddleware:设置了这个中间件之后所有需要http认证(应该就是登录的意思)的request才生效,为了使这个中间件生效,需要在spider中设置 http_user 和http_pass-----所以这个middleware很可能就是我们最终在登陆问题上需要的。
HttpCacheMiddleware:给所有http requests 和 responses提供cache。
HttpCompressionMiddleware:不懂:This middleware allows compressed(gzip,deflate) traffic to be sent /received from web sites.
ChunkedTransferMiddleware:此中间件提供对分块传输编码的支持。
HttpProxyMiddleware:此中间件通过给Request对象设定proxy meta value来设置HTTP代理。
RedirectMiddleware:此中间件基于response的状态来对requests进行重定向(不懂)。
MetaRefreshMiddleware:This middleware handles redirection of requests based on meta-refresh html tag.
RetryMiddleware:用于
bb4f
重试由于一些暂时性问题而失败的requests。
RobotsTxtMiddleware:此中间件过滤掉被robots.txt exclusion standard终止的requests。
DownloaderStats:存储所有经过的requests,responses和exceptions的数据的中间件。
AjaxCrawlMiddleware:(没看懂)Middleware that finds 'AJAX crawlable' page variants based on meta-fragment html tag.2 正式开始解决twitter登陆的问题
2.1 First Try
首先先按1.4.2中spider的写法写了一个登陆twitter的spider,代码如下:__author__ = 'xyz' # -*- coding: utf-8 -*- import scrapy class LoginSpider(scrapy.Spider): name = "logintwitter" # allowed_domains = ["twitter.com"] start_urls = ( 'https://twitter.com', ) http_user = "xxxxx" http_pass = "xxxxx" def parse(self, response): return scrapy.FormRequest.from_response( response, formdata={'session[username_or_email]': self.http_user, 'session[password]': self.http_pass}, callback=self.after_login ) def after_login(self, response): # print(response.body) print(response.xpath('(//a[contains(@href,"hashtag")])//b | (//a[contains(@href,"hashtag")])//span/text()').extract()) return scrapy.Request(url="https://twitter.com/Xyz2271372940", callback=self.parse_tastypage) def parse_tastypage(self, response): print(response.xpath('//*[@id="page-container"]/div[3]/div/div[2]/div[2]/div/div[2]/div/div/ul/li[4]/div/button').extract())
结果出现了如下DEBUG信息:
中间隐去的是第二个GET中包含用户名密码的部分。
所以在这里需要弄清楚的有几个问题:
1.scrapy中DEBUG的作用
2.Telnet console的作用
3 Crawled <200>, Redirecting <302>的含义
4.referer的含义
问题一:重新运行github的spider其中也有DEBUG信息,所以这应该不是问题。
问题二:scrapy文档中的Telnet console是一个控制台,类似于scrapy shell,和这个问题好像无关。
Telnet本身是远程终端协议,也不代表这是一个问题,而是每个spider都要用到的。
问题三:由于这个问题,我又运行了一遍登陆github的spider,发现其中也有DEBUG Craawled <200>,所以虽然现在不懂这是什么不过应该不是问题所在。
问题四:referer同理,在github这个spider的执行中也出现,而且有些和referer之前的url不同,所以这也应该不是问题。
综上,又因为response还是可以打印出一部分信息,并且response.body也可以打印,所以我现在推测问题还是在xpath或者twitter专有的某种信息获取规则上。
I'm gonna stop here, think over the whole thing, see if I should learn some basic stuff at first, and then I'll come back here.
参考文献: http://doc.scrapy.org/en/latest/index.html https://github.com/yall/scrapy-twitter
Learning Scrapy https://blog.scrapinghub.com/2012/10/26/filling-login-forms-automatically/ https://github.com/scrapy/loginform http://stackoverflow.com/questions/31919069/scrapy-recursive-website-crawl-after-login http://stackoverflow.com/questions/30746820/python-scrapy-login-redirecting-problems http://stackoverflow.com/questions/5850755/using-scrapy-with-authenticated-logged-in-user-session (最重要的)




相关文章推荐
- Python动态类型的学习---引用的理解
- Python3写爬虫(四)多线程实现数据爬取
- 垃圾邮件过滤器 python简单实现
- 下载并遍历 names.txt 文件,输出长度最长的回文人名。
- install and upgrade scrapy
- install scrapy with pip and easy_install
- Scrapy的架构介绍
- Centos6 编译安装Python
- 使用Python生成Excel格式的图片
- 让Python文件也可以当bat文件运行
- [Python]推算数独
- Python中zip()函数用法举例
- Python中map()函数浅析
- Python将excel导入到mysql中
- Python在CAM软件Genesis2000中的应用
- 使用Shiboken为C++和Qt库创建Python绑定