Regularization(规则化)和model selection以及Python实现
2016-06-07 16:28
537 查看
这次以非线性转换(Nonlinear Transformation)为例,分别通过对多项式次数的选择和regularization避免过拟合,还通过model selection来提高识别能力。
(一)非线性模型
原来的学习模型大多假设两个类别是线性可分的,所以找到了一条直线或一个线性空间平面可以将两个类别进行分类,但是一些情况下会出现线性不可分的情况。或者进行回归预测的过程中,不能用一条直线来拟合数据。这时候就需要非线性模型来实现。下面两个图分别是Logistic 回归和回归过程在线性情况下欠拟合,到参数(这里看的是多项式的阶数)过多情况下过拟合的过程。选择适当的非线性模型参数是分类或回归的效果最好是我们的目的。


<span style="font-size:18px;">程序相对以前的改动如下</span>
准确率达到了百分之96.666
(二)产生过拟合的原因
VC维变大时,函数的Ein变小但Eout变大(也就是假设函数的泛化能力很差),此种情况称之为过拟合。相对于过拟合有着欠拟合,解决方法只要提高多项式次数就可以。而过拟合的处理方法相对复杂。
产生过拟合的原因主要有三种,使用过度的VC维、噪声、数据量大小。
1、对于噪声和VC维,有噪声情况下,低次多项式假设比和目标函数同次的多项式假设表现更好。假设没有噪声,在更高次数的目标函数下,比如50次的多项式函数,用2次假设或10次假设都相当于一种含有噪声的情况(由于两者都无法做到50次的目标函数,相当于含有噪声)。下图为二次函数和10次函数的学习鸿沟(learning curves)可以看出,当数据量少时2次函数的Ein和Eout差距小,泛化能力强。
2、对于噪声、复杂度(高次也相当于一种噪声形式)和训练数据量与过拟合的关系,就像教小孩学习,要从简单开始(低复杂度),多次重复(数据量),减少其他事情的干扰(减少噪声)。具体的内容可以参考林轩田的机器学习基石课程第13课。
而出现了过拟合问题,应该如何处理呢?主要有两个办法:特征选择和正则化

(三)regularization(正则化)
正则化中我们将保留所有的特征变量,但是会减小特征变量的数量级(参数数值的大小w(j))。这个方法非常有效,当我们有很多特征变量时,其中每一个变量都能对预测产生一点影响。其本质就是给代价函数或Ein的系数加上一个限制。
利用拉格朗日函数可以得到下面的结果。(虽然符号不同,但是都讲了同样的事情)

下面的这项就是一个正则化项

并且 λ 在这里我们称做正则化参数。我们需要适当的选择正则化参数。下图表达了λ从小到大由过拟合到欠拟合的过程。参数的选择方式主要是通过交叉验证实现(model selection部分提到)。
在林教授的机器学习基石课程中讲到了,若输入Xn是一个[-1,1]之间的数,多项式的转换函数在高次项的时候会变得非常小,所以为了和低次项对应的权值向量分量产生一致的影响力,则该项的权值Wq会非常大,但正则化的求解需要特别小的权值向量,因此需要转换后的多项式各项线性无关,可以将转换函数设为Legendre多项式。
除了上面讲的Regularization方法还有L1norm方法(针对少数1多数为0的情况如在支持向量机中应用)。下面的文章写的不错。http://blog.csdn.net/zouxy09/article/details/24971995/
(四)模型选择
模型选择就是希望在有许多模型的情况下,能够在偏差和方差之间达到平衡。对于不同的算法,可能想选择合适的多项式次数、局部加权线性回归的 τ或者是SVM中的惩罚因子C。而只通过经验风险(也就是训练误差)最小化方法一定会产生过拟合的现象,所以我们希望通过下面的方式来解决这一问题。
1、 从全部的训练数据S中随机选择70%的样例作为训练集
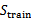
,剩余的30%作为测试集
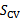
。
2、 在
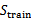
上训练每一个
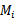
,得到假设函数
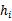
。
3、 在
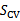
上测试每一个
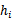
,得到相应的经验错误
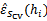
。
4、 选择具有最小经验错误
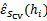
的
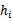
作为最佳模型。
这种方法称为保留交叉验证(hold-out cross validation)。在数据量很小的情况下这个明显不太适用。所以我们采用K重交叉验证(k-fold cross validation),方法如下:
简单说就是把一个数据集随机分成K份,对于一个模型,首先用K-1份进行训练,一份进行测试得到一个错误率,然后重复K次得到一个平均错误率。对所有的模型都进行这样的训练,然后取平均错误率最小的作为最终的模型。
(五)特征选择
严格来说,特征选择也是模型选择的一种。特征选择主要针对一类问题,就是特征的数量远远大于训练样本数时想要通过某种方式来剔除无用的特征,n个特征就有2^n种情况,显然不能用交叉验证注意考察每种模型的错误率。需要一些启发式的搜索方法。而有很多可以实现的方法,不逐一介绍了。可以参考下面的链接
http://www.cnblogs.com/XBWer/p/4563079.html
注:程序参考http://scikit-learn.org/stable/auto_examples/model_selection/plot_underfitting_overfitting.html
(一)非线性模型
原来的学习模型大多假设两个类别是线性可分的,所以找到了一条直线或一个线性空间平面可以将两个类别进行分类,但是一些情况下会出现线性不可分的情况。或者进行回归预测的过程中,不能用一条直线来拟合数据。这时候就需要非线性模型来实现。下面两个图分别是Logistic 回归和回归过程在线性情况下欠拟合,到参数(这里看的是多项式的阶数)过多情况下过拟合的过程。选择适当的非线性模型参数是分类或回归的效果最好是我们的目的。
<span style="font-size:18px;">程序相对以前的改动如下</span>
# -*- coding: utf-8 -*-
import random
from numpy import *
from math import *
from sklearn.preprocessing import PolynomialFeatures
polynomial_features = PolynomialFeatures(2, False)
# 逻辑函数
def sigmoid(inX):#由于在计算过程中inX可能会超出Exp(-inX)计算的界限
if inX > 1000:
return 1
elif inX< -500:
return -1
else:
return 1.0/(1+exp(-inX))
#加载数据
#Logistic 回归
def logisticRegression(dataMat,labelMat,opts):
numSamples,numFeature = shape(dataMat)
alpha = opts['alpha'] ; maxIter = opts['maxIter']
weight = ones((21,1))#由于2次多项式的系数是21,这个只要测试一下就可以了
for j in range(maxIter):
if opts['optimizeType'] == 'smoothStocGradDescent':# smooth stochastic gradient descent
dataIndex = range(numSamples)
for i in range(numSamples):
randIndex = int(random.uniform(0,len(dataIndex)))#产生0到dataIndex之间的随机数
alpha = 4.0/(1.0+j+i)+0.01 #j是迭代次数,i是迭代时,第i个选出的样本
dataMatMul = polynomial_features.fit_transform(dataMat[randIndex]) #这个函数是sklearn带的
dataMatMul = mat(dataMatMul)
h = sigmoid(sum(dataMatMul[0]*weight))
error = labelMat[randIndex] - h
weight = weight + alpha * dataMatMul[0].T* error
del(dataIndex[randIndex])
else:
raise NameError('Not support optimize method type!')
return weight</pre></p><p></p><p><span style="font-size:18px"><span style="font-size:18px">主程序如下:</span></span></p><p><span style="font-size:18px"><span style="font-size:18px"></span></span><pre class="python" name="code"># -*- coding: utf-8 -*-
from logisticRegression import *
from numpy import *
#知道了Iris共有三种类别Iris-setosa,Iris-versicolor和Iris-virginica
def loadDataSet(filename):
numFeat = len(open(filename).readline().split(','))-1
dataMat = []; labelMat = []
fr = open(filename)
for line in fr.readlines():
lineArr = []
curLine = line.strip().split(',')
for i in range(numFeat):
lineArr.append(float(curLine[i]))
dataMat.append([1]+lineArr) #这里是为了使 x0 等于 1
labelMat.append(curLine[-1])
return dataMat,labelMat
# voteResult = {'Iris-setosa':0,'Iris-versicolo':0,'Iris-virginica':0}#记录投票情况
voteResult = [0,0,0]
categorylabels = ['Iris-setosa','Iris-versicolor','Iris-virginica']#类别标签
opts = {'alpha': 0.01, 'maxIter': 100, 'optimizeType': 'smoothStocGradDescent'}
#训练过程
dataMat,labelMat = loadDataSet('train.txt')
weight1 = []
for i in range(3):#三类
labelMat1 = []
for j in range(len(labelMat)):#把名称变成0或1的数字
if labelMat[j] == categorylabels[i]:
labelMat1.append(1)
else:
labelMat1.append(0)
dataMat = mat(dataMat);
weight1.append(logisticRegression(dataMat,labelMat1,opts))
print weight1
#测试过程
dataMat,labelMat = loadDataSet('test.txt')
dataMat = mat(dataMat)
initial_value = 0
list_length = len(labelMat)
h = [initial_value]*list_length
for j in range(len(labelMat)):
voteResult = [0,0,0]
for i in range(3):
dataMatMul = polynomial_features.fit_transform(dataMat[j])
dataMatMul = mat(dataMatMul)
h[j] = float(sigmoid(dataMatMul[0]*weight1[i]))#得到训练结果
if h[j] > 0.5 and h[j] <= 1:
voteResult[i] = voteResult[i]+1+h[j]
elif h[j] >= 0 and h[j] <= 0.5:
voteResult[i] = voteResult[i]-1+h[j]
else:
print 'Properbility wrong!'
h[j] = voteResult.index(max(voteResult))
print h
labelMat2 = []
for j in range(len(labelMat)):#把名称变成0或1或2的数字
for i in range(3):#三类
if labelMat[j] == categorylabels[i]:
labelMat2.append(i);break
#计算正确率
error = 0.0
for j in range(len(labelMat)):
if h[j] != labelMat2[j]:
error = error +1
pro = 1 - error / len(labelMat)#正确率
print pro准确率达到了百分之96.666
(二)产生过拟合的原因
VC维变大时,函数的Ein变小但Eout变大(也就是假设函数的泛化能力很差),此种情况称之为过拟合。相对于过拟合有着欠拟合,解决方法只要提高多项式次数就可以。而过拟合的处理方法相对复杂。
产生过拟合的原因主要有三种,使用过度的VC维、噪声、数据量大小。
1、对于噪声和VC维,有噪声情况下,低次多项式假设比和目标函数同次的多项式假设表现更好。假设没有噪声,在更高次数的目标函数下,比如50次的多项式函数,用2次假设或10次假设都相当于一种含有噪声的情况(由于两者都无法做到50次的目标函数,相当于含有噪声)。下图为二次函数和10次函数的学习鸿沟(learning curves)可以看出,当数据量少时2次函数的Ein和Eout差距小,泛化能力强。
2、对于噪声、复杂度(高次也相当于一种噪声形式)和训练数据量与过拟合的关系,就像教小孩学习,要从简单开始(低复杂度),多次重复(数据量),减少其他事情的干扰(减少噪声)。具体的内容可以参考林轩田的机器学习基石课程第13课。
而出现了过拟合问题,应该如何处理呢?主要有两个办法:特征选择和正则化
(三)regularization(正则化)
正则化中我们将保留所有的特征变量,但是会减小特征变量的数量级(参数数值的大小w(j))。这个方法非常有效,当我们有很多特征变量时,其中每一个变量都能对预测产生一点影响。其本质就是给代价函数或Ein的系数加上一个限制。
利用拉格朗日函数可以得到下面的结果。(虽然符号不同,但是都讲了同样的事情)
下面的这项就是一个正则化项

并且 λ 在这里我们称做正则化参数。我们需要适当的选择正则化参数。下图表达了λ从小到大由过拟合到欠拟合的过程。参数的选择方式主要是通过交叉验证实现(model selection部分提到)。
在林教授的机器学习基石课程中讲到了,若输入Xn是一个[-1,1]之间的数,多项式的转换函数在高次项的时候会变得非常小,所以为了和低次项对应的权值向量分量产生一致的影响力,则该项的权值Wq会非常大,但正则化的求解需要特别小的权值向量,因此需要转换后的多项式各项线性无关,可以将转换函数设为Legendre多项式。
除了上面讲的Regularization方法还有L1norm方法(针对少数1多数为0的情况如在支持向量机中应用)。下面的文章写的不错。http://blog.csdn.net/zouxy09/article/details/24971995/
(四)模型选择
模型选择就是希望在有许多模型的情况下,能够在偏差和方差之间达到平衡。对于不同的算法,可能想选择合适的多项式次数、局部加权线性回归的 τ或者是SVM中的惩罚因子C。而只通过经验风险(也就是训练误差)最小化方法一定会产生过拟合的现象,所以我们希望通过下面的方式来解决这一问题。
1、 从全部的训练数据S中随机选择70%的样例作为训练集

,剩余的30%作为测试集

。
2、 在
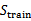
上训练每一个
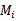
,得到假设函数
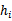
。
3、 在
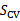
上测试每一个
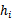
,得到相应的经验错误

。
4、 选择具有最小经验错误
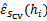
的
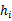
作为最佳模型。
这种方法称为保留交叉验证(hold-out cross validation)。在数据量很小的情况下这个明显不太适用。所以我们采用K重交叉验证(k-fold cross validation),方法如下:
简单说就是把一个数据集随机分成K份,对于一个模型,首先用K-1份进行训练,一份进行测试得到一个错误率,然后重复K次得到一个平均错误率。对所有的模型都进行这样的训练,然后取平均错误率最小的作为最终的模型。
(五)特征选择
严格来说,特征选择也是模型选择的一种。特征选择主要针对一类问题,就是特征的数量远远大于训练样本数时想要通过某种方式来剔除无用的特征,n个特征就有2^n种情况,显然不能用交叉验证注意考察每种模型的错误率。需要一些启发式的搜索方法。而有很多可以实现的方法,不逐一介绍了。可以参考下面的链接
http://www.cnblogs.com/XBWer/p/4563079.html
注:程序参考http://scikit-learn.org/stable/auto_examples/model_selection/plot_underfitting_overfitting.html

相关文章推荐
- python调试工具pdb和ipdb的使用
- 在Python的Flask中使用WTForms表单框架的基础教程
- Python - 实用的内置函数zip
- PYTHON-进阶-编码处理
- 提取用Bounding box label标记后的误标文件
- Python中Mysql的操作方法
- 详解Python的Flask框架中生成SECRET_KEY密钥的方法
- windows下安装python pip
- python读取数据库数据,读取出的中文乱码问题
- python写入中文到文件乱码的问题
- Python实现农历生日提醒功能
- Python Flask Web 第十一课 —— 使用 Flask-SQLAlchemy 管理数据库
- python定义多维字典
- Python的学习
- Python的Flask框架中配置多个子域名的方法讲解
- 使用python通过selenium模拟打开chrome窗口报错 出现 "您使用的是不受支持的命令行标记:--ignore-certificate-errors
- Python的Flask框架中SERVER_NAME域名项的配置教程
- python实现hive自动化测试
- python itertools模块指南
- Python之re模块 —— 正则表达式操作[转]