优化
2016-06-06 16:44
393 查看
问题定义
目标函数为minf(x)梯度下降
一阶方法f(x)在xk的一阶泰勒级数展开:f(xk+1)=f(xk+Δxk)≈f(xk)+f(xk)′Δxk
momentum
通过积累下降速度,来加速梯度下降方法。这时学习率(学习速度)变复杂。牛顿法
二阶方法对f(x)在xk处进行二阶泰勒展开f(xk+1)=f(xk+Δx)≈f(xk)+f′(xk)Δx+12ΔxTH(f)Δx
其中,H(f)是f(x)的所有二阶导数构成的矩阵.我们的目标是求上式得最小值,所以按照惯例对Δx其求导:f′(xk)+H(f)Δx=0得到迭代更新量Δx=−f′(xk)H(f)牛顿法利用了二阶导数,对于二次函数的最小化问题能够一步收敛。由于需要计算Hessian矩阵,对于非二次函数的高纬问题,计算、存储开销为O(n2),而且对于使用BP方式计算梯度的神经网络来说,我们可能根本不知道如何计算Hessian矩阵。而共轭梯度下降是无需要计算Hessian矩阵的方法。
共轭梯度下降(Conjugate gradient)
二阶方法。使用梯度下降可能存在在相同的方向上多次迭代,如下图绿线所示: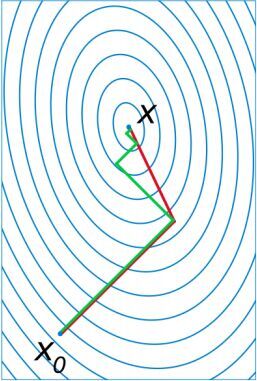
共轭梯度方法不选择准确的梯度方向为它的前进方向,从不在相同的方向上迭代两次,如上图中红线所示。
对于目标函数f(x)为二次的情况,可以写为:
f(x)=12xTAx+bTx+c,并且总可以找到A满足对称性:A=AT,求∇f(x):∇f(x)=Ax+b,
梯度下降和共轭梯度下降方法对比如下:
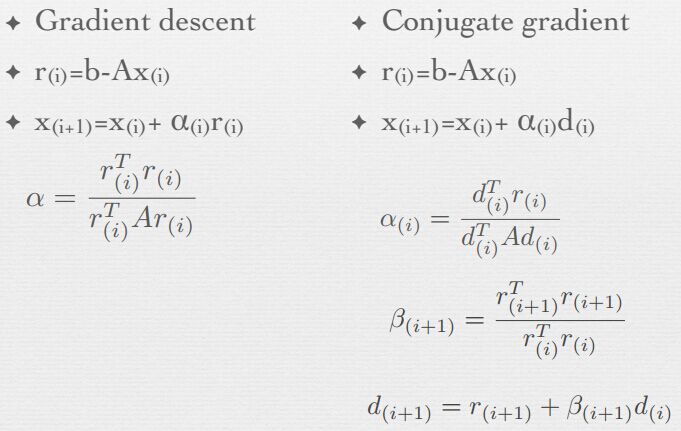
计算问题
不用计算hesse矩阵学习率
学习率过小,收敛速度慢;学习率过大,可能导致网络的损失函数值不降反增。如下图: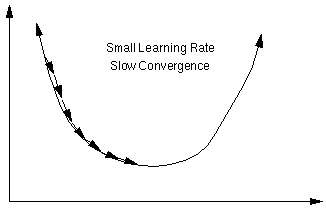
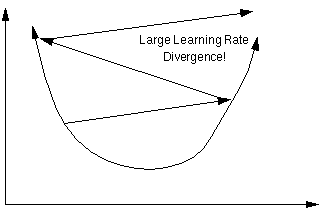
根据学习率随训练迭代的变化方式分为两种:非自适应和自适应。
非自适应
一般地,学习率随着训练迭代增加而减小,其形式包括很多种,如退火方法(Annealing schedule,如指数退火法),或者其他自定义的衰减方式。
caffe中使用的learning rate 下降方式,详见这里。
自适应
Adagrad
Adadelta
RMSprop
Adam
Adaptive Moment Estimation以上详细见本部分的参考2
参考
1.Learning Rate Schedules for Faster Stochastic Gradient Search, Christian Darken, Joseph Chang and John Moody, Neural Networks for Signal Processing 2 — Proceedings of the 1992 IEEE Workshop, IEEE Press, Piscataway, NJ, 1992.2.http://sebastianruder.com/optimizing-gradient-descent/
3.http://cs231n.github.io/neural-networks-3/#anneal
参考
共轭梯度:1.bengio,etc,Deep Learning,2015
2.Jonathan Richard Shewchuk,An Introduction to the Conjugate Gradient Method Without the Agonizing Pain,1994
3.http://andrew.gibiansky.com/blog/machine-learning/conjugate-gradient/

相关文章推荐
- MySQL 优化
- Google排名优化的几个影响因素
- DB2优化(简易版)
- Mysql limit 优化,百万至千万级快速分页 复合索引的引用并应用于轻量级框架
- C#中尾递归的使用、优化及编译器优化
- 对优化Ruby on Rails性能的一些办法的探究
- 优化Ruby脚本效率实例分享
- Asp编码优化技巧
- 如何监测和优化OLAP数据库
- mysql -参数thread_cache_size优化方法 小结
- 深入学习SQL Server聚合函数算法优化技巧
- MySQL常见的底层优化操作教程及相关建议
- 详解mysql的limit经典用法及优化实例
- 数据库学习建议之提高数据库速度的十条建议
- oracle数据库sql的优化总结
- SQL语句性能优化(续)
- SQL语句优化提高数据库性能
- SQL优化经验总结
- SQL优化技巧指南
- SQL Server优化50法汇总