Python 华理 教学周
2016-06-04 21:16
645 查看
找
对于我等学渣来说,现在是第几周,向来搞不清的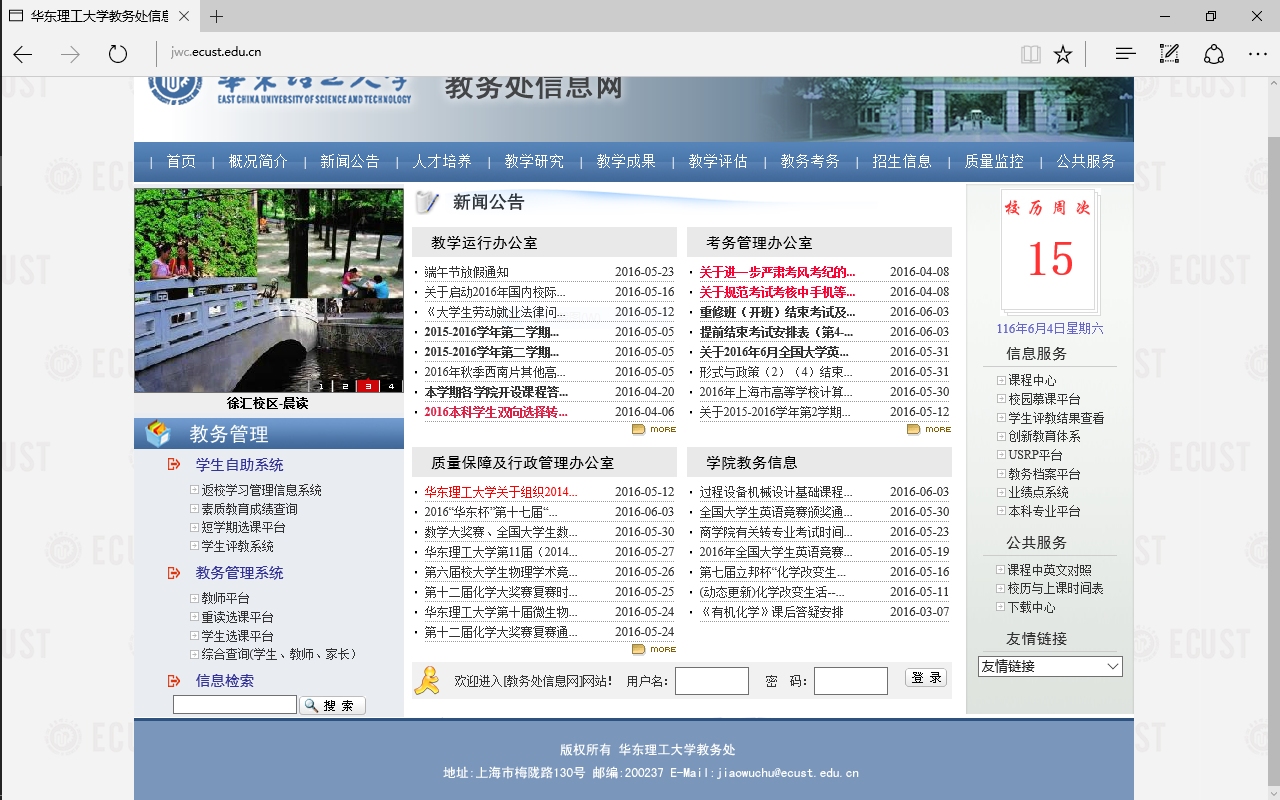
于是想写个程序来看是第几周
先右键检查元素
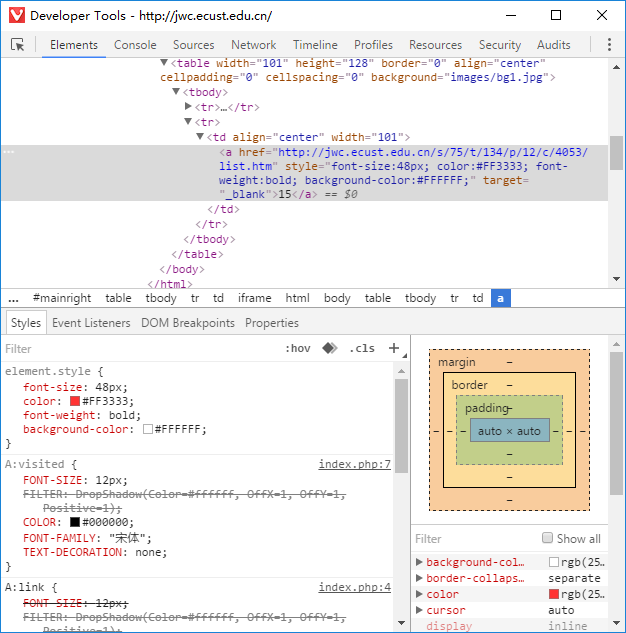
看到15了 并且还有href 和 style 属性
再Ctrl + U看下源代码
结果并没有找到这一段 说明是后来加载了
于是我就找啊找,结果发现是iframe加载的

那好办了,直接访问src就是了
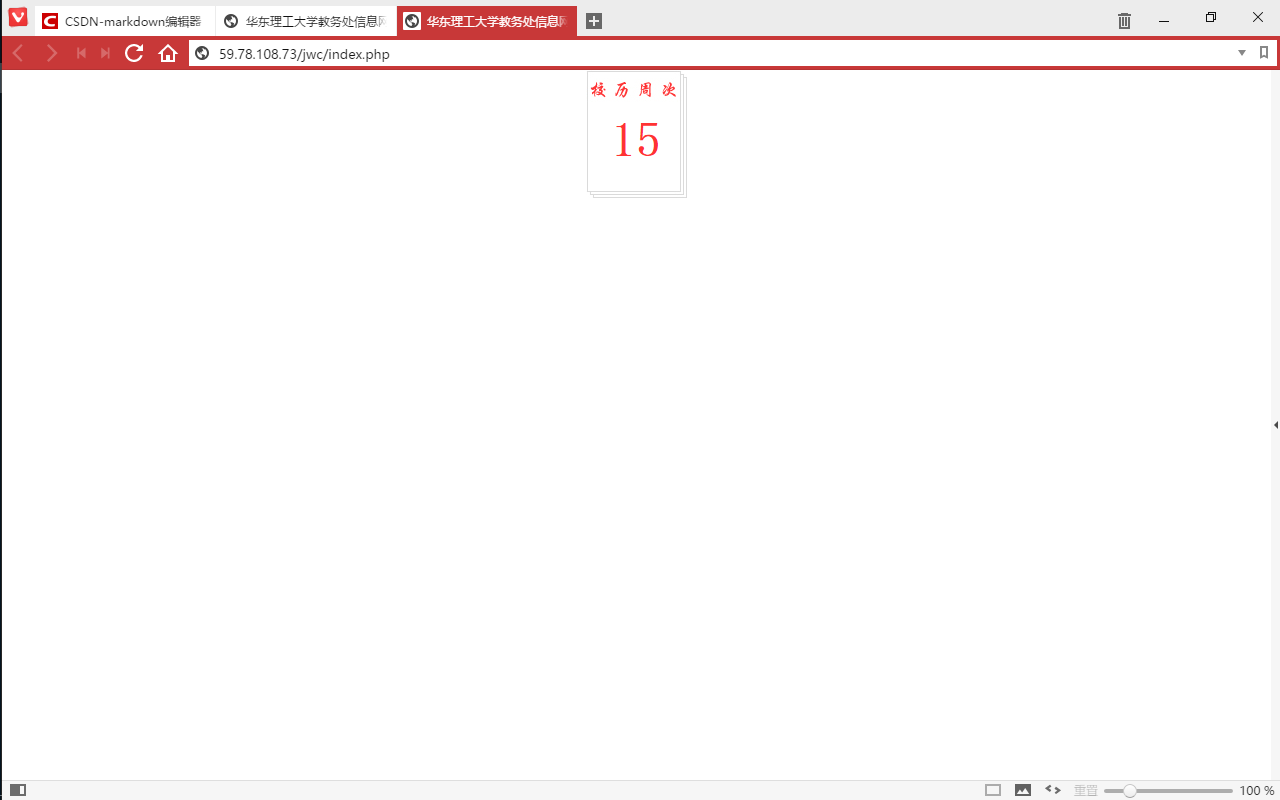
这个网页真是言简意赅
看下源码
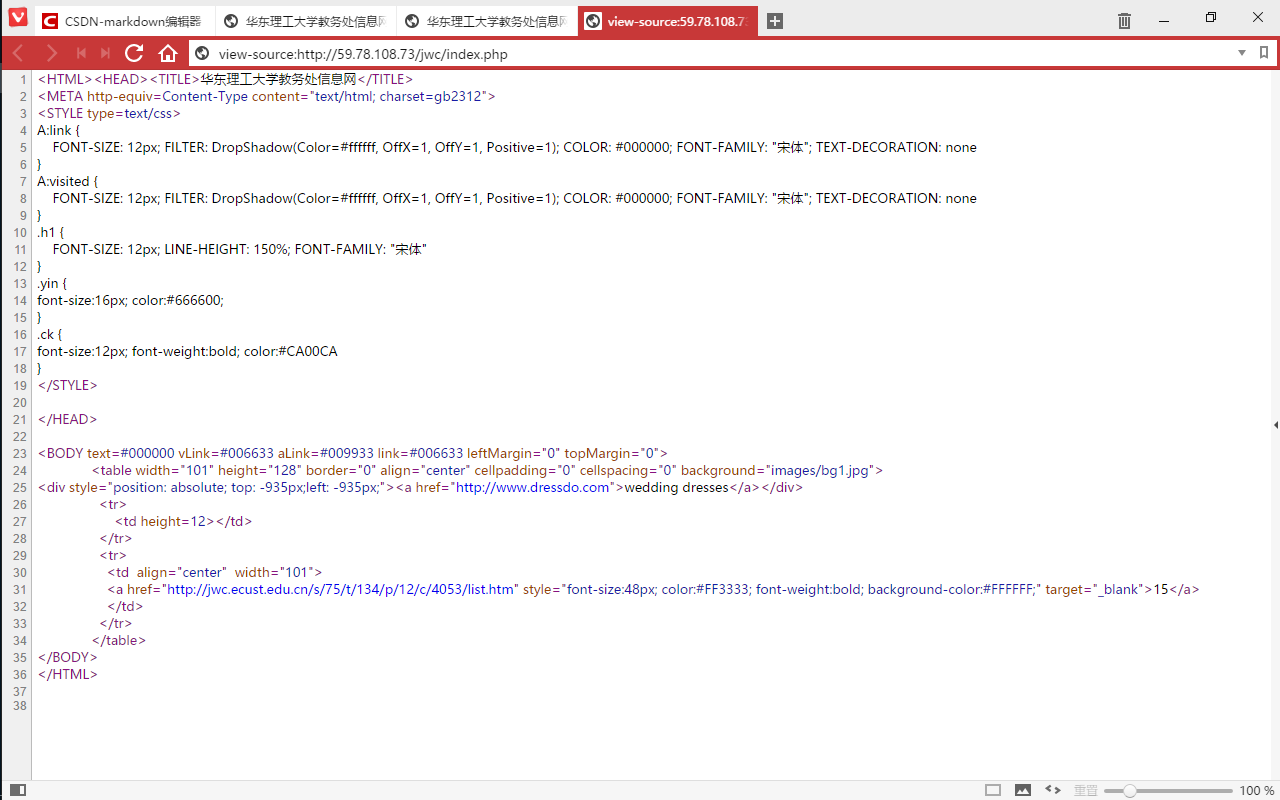
看到15了 可以开始编程了
写
>>> import requests >>> url = 'http://59.78.108.73/jwc/index.php' >>> html = requests.get(url).text
这首先引入request 因为我装的是了anaconda,所以就自带了
然后html就是url的全部html字符串,i.e.上图
>>> from bs4 import BeautifulSoup >>> soup = BeautifulSoup(html, "lxml")
这里使用了BeautifulSoup这个库,用来解析html,与jsoup类似
关于BeatuifulSoup可以看这个文档,有中文
后面的lxml是xml解析器什么的,文档上直接
soup = BeautifulSoup(html)
这会报一个Warning,大概意思是没指定xml解析器不同的机器就会用不同的xml解析器来解析。
>>> doc = soup.select('a[herf="http://jwc.ecust.edu.cn/s/75/t/134/p/12/c/4053/list.htm"]')这时我们用css选择器的语法把15找出来
但此时得到的doc是一个list
所以还要用doc[0]这种写法
>>> doc[0].text u'15' >>> print doc[0].text 15
这样就把当前周给找出来了

相关文章推荐
- nested function in python
- Python使用函数默认值实现函数静态变量的方法
- Ipython notebook安装
- Python Tricks(十六)—— list转换为str
- Python--基础学习--流程控制
- python 数据清理诺干错误
- Python内置函数chr() unichr() ord()
- Python机器学习开发环境搭建和GraphLab Create安装
- python爬虫的使用
- python str bytes转换
- Python进阶之函数式编程
- Python--详解Python中re.sub
- Opencv3.0-python的那些事儿:(四)、Opencv的图像阈值处理
- python学习第一天
- Python list 交集,并集,差集
- python学习 函数
- Python断行
- PYTHON 源码解析
- censys 数据库地理信息自定义接口(python版)
- python二叉树的层次遍历