linux里的nvme驱动代码分析(加载初始化)
2016-06-04 16:17
686 查看
SSD取代HDD已经是个必然的趋势了。SSD的接口一路从sata变成pcie,上层协议又从ahci转变为nvme,一次次的升级也带来了一次次性能的提升。nvme物理层基于高速的pcie接口,pcie3.0一个lane就已经达到了8Gb/s的速度。x2 x4 x8 … N个lane在一起就是N倍的速度,非常强大。另外加上nvme协议本身的简洁高效,使得协议层的消耗进一步降低,最终达到高速的传输效果。
qemu是一个模拟器,可以模拟x86 arm powerpc等等等等,而且支持nvme设备的模拟(不过当前貌似nvme设备只在x86下支持,我尝试过ARM+PCI的环境,但是qemu表示不支持nvme设备)。主机端的系统当然是选择linux,因为我们可以很方便的获得nvme相关的一切代码。
那…接下来到底要怎么上手哪?linux只是一个内核,还需要rootfs,需要这需要那。我们在这里想要学习的是nvme驱动,而不是如何从零开始搭建一个linux系统,所以我们需要一条快速而又便捷的道路。这时候,我就要给大家介绍下buildroot了。有了他,一切全搞定!^_^当然,前提是我们需要一个linux的主机(推荐ubuntu,个人比较喜欢,用的人也多,出了问题比较容易在网上找到攻略,最新的可以安装16.04),并安装了qemu。
buildroot最新的版本可以从这里下载:https://buildroot.org/downloads/buildroot-2016.05.tar.bz2
解压后运行
编译完成后,根据board/qemu/x86_64/readme.txt里描述的命令,可以在qemu里运行起来刚才编译好的linux系统。
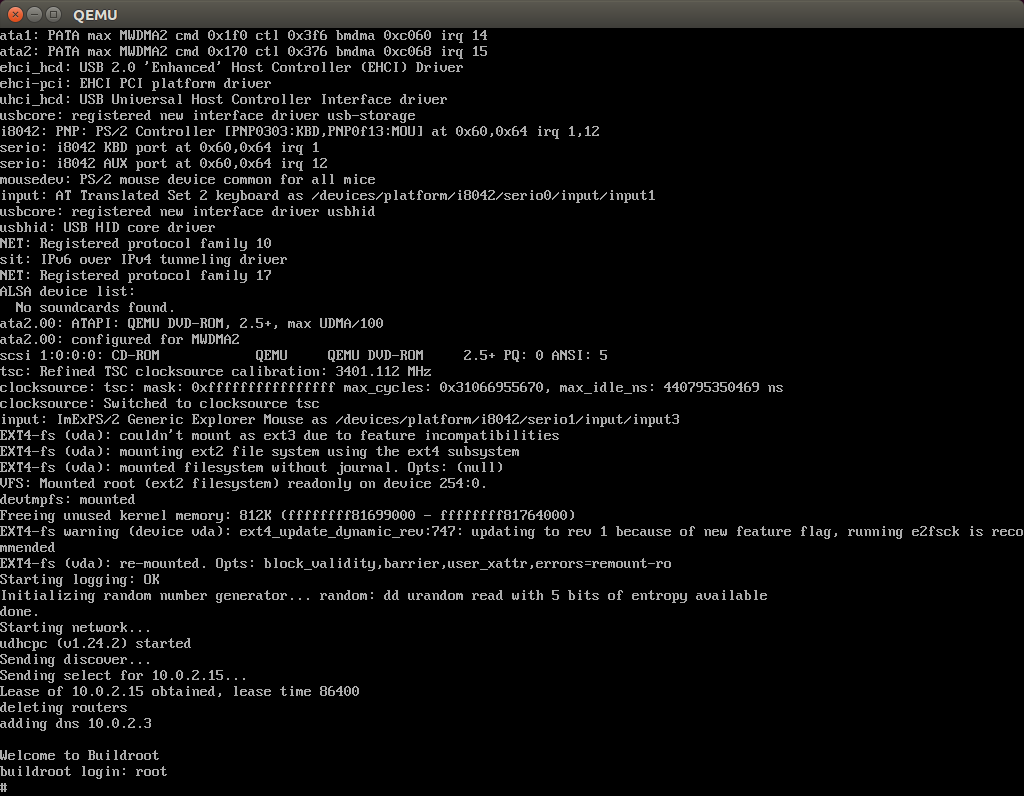
这个默认的系统log输出被重定向到了虚拟机的“屏幕”上,而非shell上,不能回滚,使得调试起来很不方便。我们需要修改一些东西把log重定向到linux的shell上。首先是编辑buildroot目录下的.config文件。
改成
然后重新编译。等到编译完成后运行下面修改过的命令,就得到我们想要的结果了。
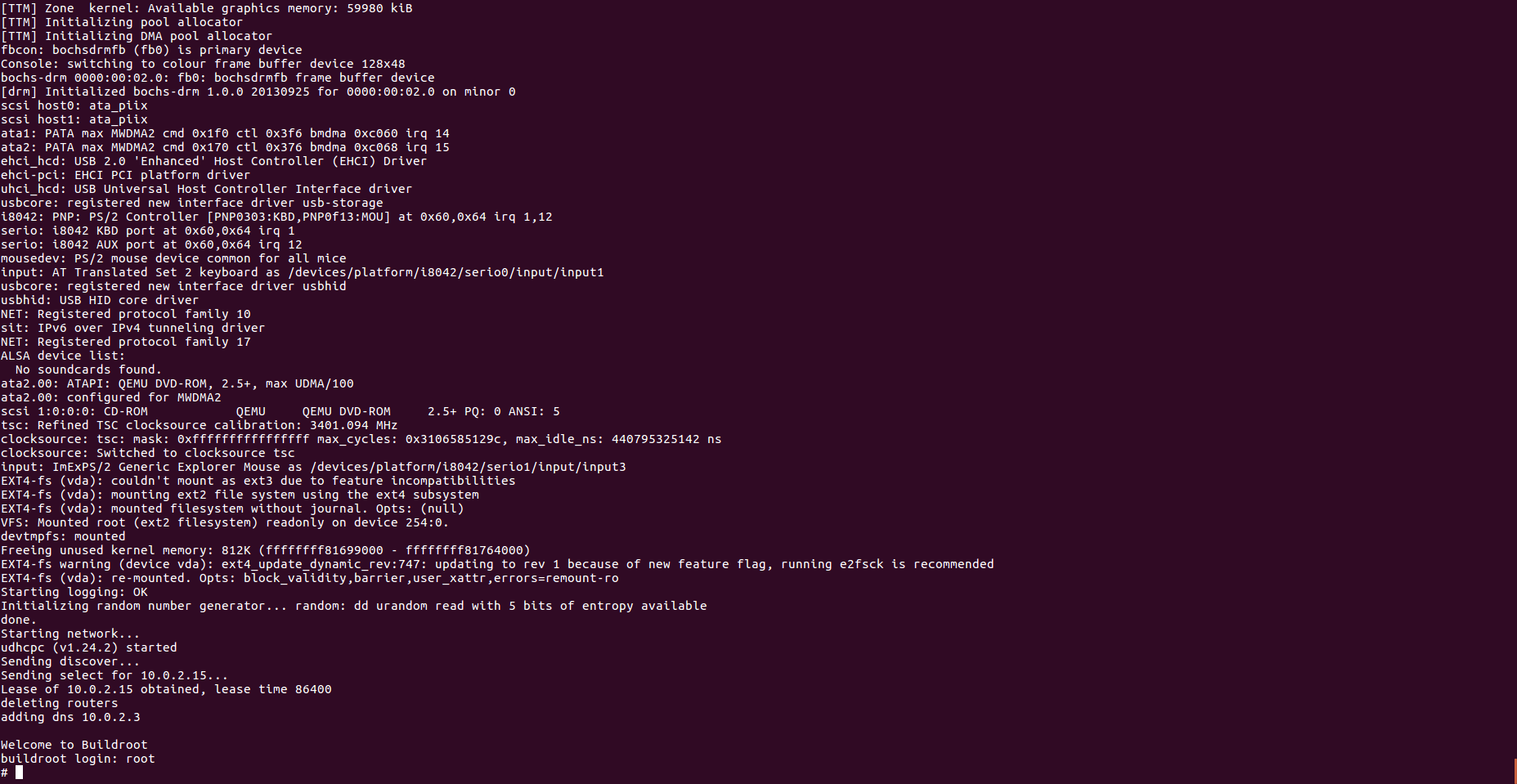
下面,我们再修改一些命令,加上nvme的支持。
linux系统起来后,我们可以在/dev下面查看到nvme相关的设备了。
自此,我们的动手实践稍作暂停,可以去学习下nvme的代码了。在遇到问题的时候,我们可以修改代码并在qemu里运行查看效果,真棒!
分析驱动,首先是要找到这个驱动的入口。module_init把函数nvme_init声明为这个驱动的入口,在linux加载过程中会自动被调用。
nvme_init流程分析:
创建一个全局的workqueue,有了这个workqueue之后,很多的work就可以丢到这个workqueue里执行了。后面会提到的两个很重要的scan_work和reset_work就是在这个workqueue里被调度运行的。
调用nvme_core_init。
调用pci_register_driver。
nvme_core_init流程分析:
调用register_blkdev注册一个名字叫nvme的块设备。
调用__register_chrdev注册一个名字叫nvme的字符设备。这些注册的设备并不会在/dev下出现,而是在/proc/devices下,代表某种设备对应的主设备号,而不是设备的实例。这里要注意一点就是,字符设备和块设备的主设备号是不相关的,所以完全可以一样,代表的是完全无关的设备。我们在这里获得的字符设备和块设备的主设备号就正好都是253。
细心的读者可能会发现,刚才我们列出来的一个字符设备nvme0,它的主设备号确实是253。但是块设备nvme0n1的主设备号是259,也就是blkext,这是为什么那?先等等,到后面注册这个设备实例的时候我们再看。
回到nvme_init,pci_register_driver注册了一个pci驱动。这里有几个重要的东西,一个是vendor id和device id,我们可以看到有一条是PCI_VDEVICE(INTEL, 0x5845),有了这个,这个驱动就能跟pci总线枚举出来的设备匹配起来,从而正确的加载驱动了。
在linux里我们通过lspci命令来查看当前的pci设备,发现nvme设备的device id就是0x5845。
pci_register_driver还有一个重要的事情就是设置probe函数。有了probe函数,当设备和驱动匹配了之后,相应驱动的probe函数就会被调用,来实现驱动的加载。所以nvme_init返回后,这个驱动就啥事不做了,直到pci总线枚举出了这个nvme设备,然后就会调用我们的nvme_probe。
nvme_probe流程分析:
为dev、dev->entry、dev->queues分配空间。entry保存的是msi相关的信息,为每个cpu core分配一个。queues为每个core分配一个io queue,所有的core共享一个admin queue。这里的queue的概念,更严格的说,是一组submission queue和completion queue的集合。
调用nvme_dev_map。
初始化三个work变量,关联回掉函数。
调用nvme_setup_prp_pools。
调用nvme_init_ctrl
通过workqueue调度dev->reset_work,也就是调度nvme_reset_work函数。
nvme_dev_map流程分析:
调用pci_select_bars,这个函数的返回值是一个mask值,每一位代表一个bar(base address register),哪一位被置位了,就代表哪一个bar为非零。这个涉及到pci的协议,pci协议里规定了pci设备的配置空间里有6个32位的bar寄存器,代表了pci设备上的一段内存空间(memory、io)。
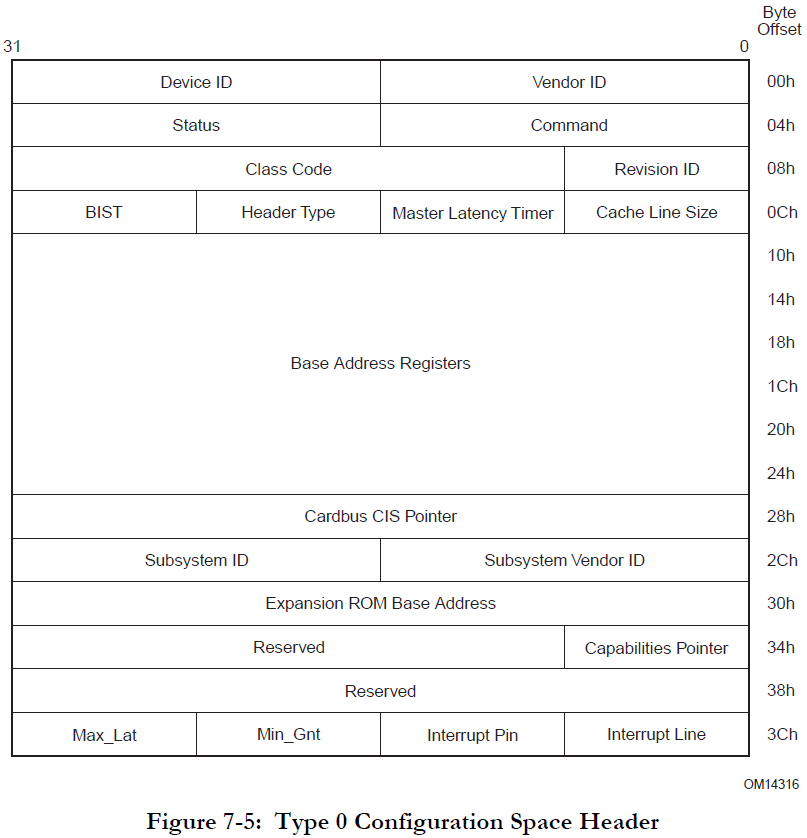
在代码中我们可以尝试着增加一些调试代码,以便我们更好的理解。在修改好代码后,我们需要在buildroot目录下重新编译内核,这样可以很快速的得到一个新的内核,然后运行看结果。我查看过pci_select_bars的返回值,是0x11,代表bar0和bar4是非零的。
调用pci_request_selected_regions,这个函数的一个参数就是之前调用pci_select_bars返回的mask值,作用就是把对应的这个几个bar保留起来,不让别人使用。
不调用pci_request_selected_regions的话/proc/iomem如下
调用pci_request_selected_regions的话/proc/iomem如下,会多出两项nvme,bar0对应的物理地址就是0xfebd0000,bar4对应的是0xfebd4000。
调用ioremap。前面说到bar0对应的物理地址是0xfebd0000,在linux中我们无法直接访问物理地址,需要映射到虚拟地址,ioremap就是这个作用。映射完后,我们访问dev->bar就可以直接操作nvme设备上的寄存器了。但是代码中,并没有根据pci_select_bars的返回值来决定映射哪个bar,而是直接hard code成映射bar0,原因是nvme协议中强制规定了bar0就是内存映射的基址。而bar4是自定义用途,暂时还不确定有什么用。
回到nvme_probe来看nvme_setup_prp_pools,主要是创建dma pool,后面就可以通过其他dma函数从dma pool中获得memory了。这里一个pool里提供的是256字节大小的内存,一个提供的是4K大小的,主要是为了对于不一样长度的prp list来做优化。
回到nvme_probe,nvme_init_ctrl里主要做的事情就是通过device_create_with_groups创建一个名字叫nvme0的字符设备,也就是我们之前见到的。
有了这个字符设备之后,我们就可以通过open、ioctl之类的接口去操作它了。
而nvme0的这个0是通过nvme_set_instance得到的。这里面主要是通过ida_get_new可以得到一个唯一的索引值。
再次回到nvme_probe,dev->reset_work被调度,也就是nvme_reset_work被调用了。
nvme_reset_work流程分析:
首先通过NVME_CTRL_RESETTING标志来确保nvme_reset_work不会被重复进入。
调用nvme_pci_enable。
调用nvme_configure_admin_queue。
调用nvme_init_queue
调用nvme_alloc_admin_tags
调用nvme_init_identify
调用nvme_setup_io_queues
调用nvme_dev_list_add
nvme_pci_enable流程分析:
调用pci_enable_device_mem来使能nvme设备的内存空间,也就是之前映射的bar0空间。
之后就可以通过readl(dev->bar + NVME_REG_CSTS)来直接操作nvme设备上的控制寄存器了,也就是nvme协议中的如下这个表。
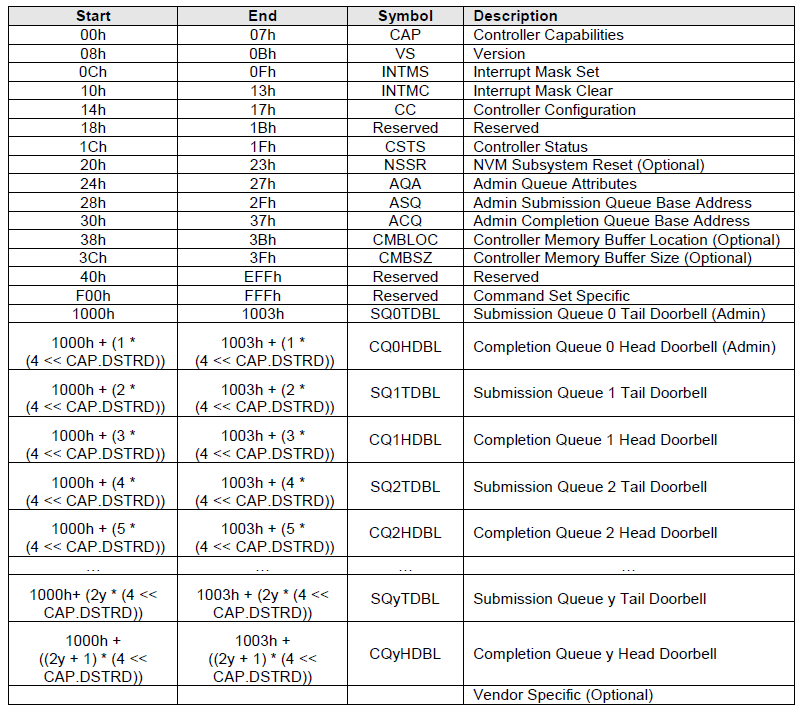
pci有两种中断模式,一种是INT,另一种是MSI。假如不支持INT模式的话,就使能MSI模式。在这里使用的是INT模式,irq号为11。但是这里还是为admin queue的msi中断号dev->entry[0].vector附了值,看来后面是可能会用到msi的。
从CAP寄存器中获得一些配置参数,并把dev->dbs设置成dev->bar+4096。4096的由来是上面表里doorbell寄存器的起始地址是0x1000。
假如nvme协议的版本大于等于1.2的话,需要调用nvme_map_cmb映射controller memory buffer。但是现在2.5版的qemu实现的nvme是1.1版的,所以这些不被支持。但是作为1.2版本的一个新加功能,我在这里还是分析一下。CMB的主要作用是把SQ/CQ存储的位置从host memory搬到device memory来提升性能,改善延时。其实这个函数里做的事情和之前做的pci映射工作没有太大区别,但是有一点需要注意,这里映射用的是ioremap_wc而不是ioremap。
我们先来看看ioremap,其实它就等价于ioremap_nocache。因为我们重映射很多情况下映射的是寄存器之类的东西,要是使用的cache的话,会产生不可预测的问题,所以默认情况下cache是不能使用的。而ioremap_wc使用了一种叫write combining的cache机制。据我所知,这是arm中没有的功能,而在x86里有实现。首先要明确的是,设置成WC之后,就和L1,L2,L3的cache没有任何关系了。在x86里,有另外一块存储区域叫WC buffer(通常是一个buffer是64字节大小,不同平台有不同数量个buffer)。设置成WC的内存,对其进行读操作时,直接从内存里读取,绕过cache。但是当对其进行写操作的时候,区别就来了。新的数据不会被直接写进内存,而是缓存在WC buffer里,等到WC buffer满了或者执行了某些指令后,WC buffer里的数据会一下子被写进内存里去。不管怎么说,这还是一种cache机制,在这里能使用的主要原因是因为SQ/CQ的内容对写进去的顺序是没有要求的,直到最后的doorbell寄存器被修改,或者设备发出一个中断后,才有可能有人去读取,所以可以用到这种优化。
回到nvme_reset_work分析nvme_configure_admin_queue。
nvme_configure_admin_queue流程分析:
从CAP寄存器中获悉对Subsystem Reset的支持
调用nvme_disable_ctrl
调用nvme_alloc_queue
调用nvme_enable_ctrl
调用queue_request_irq
这里的ctrl->ops就是之前nvme_init_ctrl时传进去的nvme_pci_ctrl_ops,reg_write32通过NVME_REG_CC寄存器disable设备。
然后通过读取状态寄存器NVME_REG_CSTS来等待设备真正停止。超时上限是根据CAP寄存器的Timeout域来计算出来的,每个单位代表500ms。

回到nvme_configure_admin_queue分析nvme_alloc_queue。
nvme_alloc_queue流程分析:
调用dma_zalloc_coherent为completion queue分配内存以供DMA使用。nvmeq->cqes为申请到的内存的虚拟地址,供内核使用。而nvmeq->cq_dma_addr就是这块内存的物理地址,供DMA控制器使用。
nvmeq->irqname是用来注册中断的时候的名字,从nvme%dq%d可以看到,就是最后生成的nvme0q0和nvme0q1,一个是给admin queue的,一个是给io queue的。
调用nvme_alloc_sq_cmd来处理submission queue,假如nvme版本是1.2或者以上的,并且cmb支持submission queue,那就使用cmb。要不然就和completion queue一样使用dma_alloc_coherent来分配内存。

再次回到nvme_configure_admin_queue,看看nvme_enable_ctrl。这个函数并没有太多特别的,可以简单理解为前面分析过的nvme_disable_ctrl的逆向操作。
回到nvme_configure_admin_queue,看最后一个函数queue_request_irq。这个函数主要的工作是设置中断处理函数,默认情况下不使用线程化的中断处理,而是使用中断上下文的中断处理。
一路返回到nvme_reset_work,分析nvme_init_queue。根据传到nvme_init_queue的参数可知,这里初始化的是queue 0,也就是admin queue。
这个函数做的事情不多,主要是对nvme_queue的成员变量进行一些初始化。q_db指向这个queue对应的doorbell寄存器的地址。
回到nvme_reset_work,分析nvme_alloc_admin_tags。
nvme_alloc_admin_tags流程分析:
blk_mq_alloc_tag_set申请tag set并和request_queue关联起来,并且会对queue_depth(254)个request(index 0-253)做初始化。初始化函数就是nvme_mq_admin_ops传进去的nvme_admin_init_request。
blk_mq_init_queue初始化request_queue并赋值给dev->ctrl.admin_q,会调用nvme_admin_init_hctx,并会调用nvme_admin_init_request初始化index 254的request,这点很奇怪。
回到nvme_reset_work,分析nvme_init_identify。
nvme_init_identify流程分析:
调用nvme_identify_ctrl
调用nvme_set_queue_limits
先来分析nvme_identify_ctrl
nvme_identify_ctrl流程分析:
创建一个opcode为nvme_admin_identify(0x6)的command。在这里我们会看到cpu_to_le32这样的函数,这些函数的主要用途是因为在nvme协议里规定的一些消息格式都是按照小端存储的,但是我们的主机可能是小端的x86,也可能是大端的arm或者其他类型,用了这样的函数就可以做到主机格式和小端之间的转换,让代码更好得跨平台。
通过nvme_submit_sync_cmd把命令发送给nvme设备
__nvme_submit_sync_cmd流程分析:
调用nvme_alloc_request
调用blk_rq_map_kern
调用blk_execute_rq,其中会调用函数指针queue_rq指向的函数nvme_queue_rq。
先看下nvme_alloc_request,blk_mq_alloc_request从request_queue中申请一个request,然后初始化这个request的一些属性。这些属性都很重要,很多会直接影响到后续代码的执行流程。
假如传进__nvme_submit_sync_cmd的buffer和bufflen参数都不为空的话,blk_rq_map_kern会被执行。在之前的nvme_alloc_request里,req->__data_len被设置成0。但是只要blk_rq_map_kern执行过之后,req->__data_len就会变成非零值,也就是映射的区域的大小。实测下来应该是以页(4096B)为单位的大小。
再分析下nvme_queue_rq。这个函数十分重要,实现了最终的命令的发送。
nvme_queue_rq流程分析:
调用nvme_init_iod
调用nvme_map_data
调用blk_mq_start_request
调用__nvme_submit_cmd
调用nvme_process_cq
看一下nvme_init_iod,第一句blk_mq_rq_to_pdu就非常让人不解。
读一下注释,再结合nvme_alloc_admin_tags里的dev->admin_tagset.cmd_size = nvme_cmd_size(dev);可知,分配空间的时候,每个request都是配备有额外的空间的,大小就是通过cmd_size来指定的。所以在request之后紧跟着的就是额外的空间。这里可以看到,额外的空间还不只是nvme_iod的大小。
由于前面设置了req->cmd_flags为REQ_TYPE_DRV_PRIV,所以command直接通过memcpy来拷贝。然后根据:
假如这个request需要传输的数据的段数目大于2,或者总长度大于2个nvme page的话,就为iod->sg另行分配空间,要不然就直接指向struct nvme_iod(区域1)的尾部,也就是struct scatterlist * nseg(区域2)的前端。
回到nvme_queue_rq,假如req->nr_phys_segments不为0,nvme_map_data会被调用。
nvme_map_data流程分析:
调用sg_init_table,初始化的就是区域2中存放的scatterlist。
调用blk_rq_map_sg
调用dma_map_sg
调用nvme_setup_prps,一个没有一行注释的长函数~其实这个函数分成3个部分,对应设置prp的三种不同情况。第一种情况是一个prp entry就能描述所有的传输,第二种情况是需要两个prp entry才能描述所有的传输,第三种情况是需要prp list才能描述所有的传输。我会在代码中加入注释来说明。
回到nvme_queue_rq,调用__nvme_submit_cmd。这个函数很简单,单很重要,就是把命令复制到submission queue中,然后把最后一个命令的索引写入doorbell的寄存器通知设备去处理。
来看nvme_queue_rq里最后一个调用的函数__nvme_process_cq,从名字上就很容易知道是用来处理completion queue的。
先看一下nvme协议里规定的completion entry的格式,每个16字节。
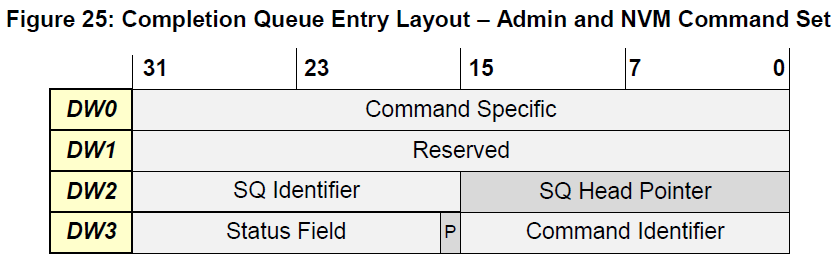
我们知道,不管是admin queue还是io queue,都有若干个submission queue和一个completion queue。而不管是submission queue还是completion queue,都是通过head和tail变量来管理的。主机端负责更新submission queue的tail来表示新任务的添加。设备端从submission queue里拿出任务处理,并修改head值。但是这个head怎么通知给主机那?答案就在completion entry的SQ Head Pointer中。对于completion queue,是反过来的,设备负责往里面添加元素,然后修改tail值。这个tail值是怎么传递给主机的那?这里就用到了另外一个机制,就是在Status Field中的PP标志位。

P标志位全称是Phase Tag,在completion queue刚建立的时候,全部初始化成0。当设备第一遍往completion queue里添加元素的时候,就把对应的entry的Phase Tag设置成1。这样,主机端通过Phase Tag的值就能够知道有多少个新的元素被添加到了completion queue中。当设备添加元素到了队列的底部,就要重新回到索引0处,这也就是completion queue的第二遍更新,这次设备又会把Phase Tag全部设置成0。就这样,一遍1一遍0再一遍1再一遍0…最后,主机处理好completion之后,更新completion queue的head值,并通过doorbell告诉设备。
__nvme_process_cq的主要机制分析了,但是为什么要在nvme_queue_rq的最后调用__nvme_process_cq,有点疑惑。因为即使不显示调用__nvme_process_cq,设备在处理完submission之后,也会发送中断(INT/MSI)给主机,在主机的中断处理函数中,也会进行__nvme_process_cq的调用。
在__nvme_process_cq中,对于处理好了的request,会调用blk_mq_complete_request。这会触发我们之前注册的nvme_complete_rq被调用。
分析了那么一大串,nvme_identify_ctrl终于讲完了。往上到nvme_init_identify,也已经基本没什么事情要做了。再往上回到nvme_reset_work,看看nvme_init_identify之后的nvme_setup_io_queues做了些什么。
nvme_setup_io_queues流程分析:
调用nvme_set_queue_count
调用nvme_create_io_queues
nvme_set_queue_count发送了一个set features的命令,feature id为0x7,设置io queue的数量。
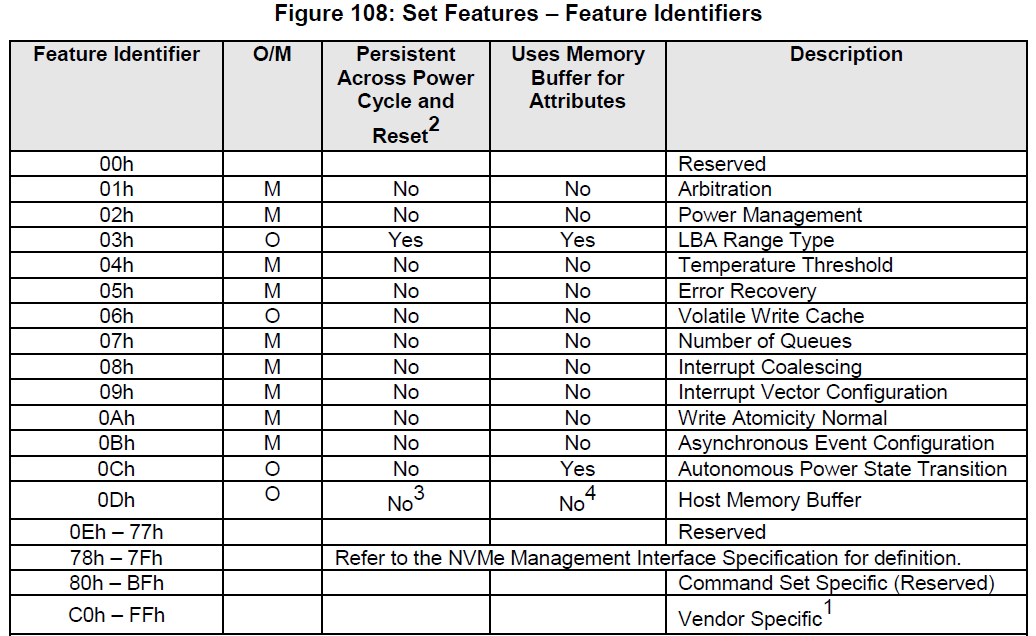
queue的大小存放在set features命令的dword 11中。

回到nvme_setup_io_queues,分析nvme_create_io_queues。
nvme_alloc_queue在之前分析过就不再累赘了,主要看下nvme_create_queue。
adapter_alloc_cq发送opcode为0x5的create io completion queue命令。
adapter_alloc_sq发送opcode为0x1的create io submission queue命令。
最后注册中断,就是之前我们列出来过的nvme0q1。
再次回到nvme_reset_work,分析nvme_dev_list_add。这个函数主要做的是启动了一个内核线程nvme_kthread,这个函数我们后面再分析。
继续回到nvme_reset_work,分析nvme_start_queues。
继续回到nvme_reset_work,分析最后一个函数nvme_dev_add。blk_mq_alloc_tag_set在之前调用过一次,是为admin queue分配tag set。这次则是为了io queue分配tag set。
最后,调用nvme_queue_scan调度了另一个work,也就是函数nvme_dev_scan。
至此,nvme_reset_work完全结束。让我们进入到下一个work里,去征服另一个山头吧!
调用nvme_scan_namespaces。
先调用nvme_identify_ctrl给设备发一个identify命令,然后把取得的namespace number传给__nvme_scan_namespaces。

为每个namespace调用一次nvme_validate_ns。nvme协议规定,namespace号0表示不使用namespace功能,0xFFFFFFFF表示匹配任何namespace号。所以正常的namespace号是从1开始的。
先查找某个namespace是否已经存在,初始化的时候,namespace都还没有创建,所以返回的肯定是空。
既然找不到相应的namespace,那就要创建它。
nvme_alloc_ns中有个重要函数nvme_revalidate_disk需要跟进去。
回到nvme_alloc_ns,执行完add_disk之后,注册在disk->fops中的nvme_open和nvme_revalidate_disk会被调用。
回到nvme_dev_scan,调用nvme_set_irq_hints。主要做一些中断亲和性的优化工作。
至此,nvme_dev_scan也结束了,整个nvme驱动的初始化也基本完成了。初始化完成之后,留给我们的就是/dev下的nvme0和nvme0n1两个供应用层操作的接口,以及一个默默无闻在那里1秒轮询一次的内核线程nvme_kthread。这个线程做的事情很有限,检测是否需要重启,是否有没有处理的completion消息。但是我没有明白,像处理CQ这种事情不都是有中断驱动的吗,为何还需要去轮询?
由于篇幅有限,有关初始化后的读写打算放在另一篇文章里写。
当然,由于对nvme的学习还处在入门阶段,代码分析总会出现不够详细甚至是错误的地方,希望大家对于错误的地方积极指出,我好确认后改掉,谢谢。
QEMU + BUILDROOT
出于好奇和兴趣,想要学习一下nvme。协议自然是看最新的pcie3.0和nvme1.2。但是只停留在文档和协议始终只是纸上谈兵,必须要进行一点实践才能理解深刻。要进行实践,无非是两条路。一是从设备端学习固件的nvme模块,二就是从主机端学习nvme的驱动。如今没再从事ssd的工作了,所以想走第一条路基本是不可能了,只能在第二条路上做文章。要是手上有一个nvme的ssd,那对于实验是非常不错的,可惜我没有,相信大多数的人也没有。然而曲线也能救国,总有一条路是给我们准备的,那就是qemu了!qemu是一个模拟器,可以模拟x86 arm powerpc等等等等,而且支持nvme设备的模拟(不过当前貌似nvme设备只在x86下支持,我尝试过ARM+PCI的环境,但是qemu表示不支持nvme设备)。主机端的系统当然是选择linux,因为我们可以很方便的获得nvme相关的一切代码。
那…接下来到底要怎么上手哪?linux只是一个内核,还需要rootfs,需要这需要那。我们在这里想要学习的是nvme驱动,而不是如何从零开始搭建一个linux系统,所以我们需要一条快速而又便捷的道路。这时候,我就要给大家介绍下buildroot了。有了他,一切全搞定!^_^当然,前提是我们需要一个linux的主机(推荐ubuntu,个人比较喜欢,用的人也多,出了问题比较容易在网上找到攻略,最新的可以安装16.04),并安装了qemu。
buildroot最新的版本可以从这里下载:https://buildroot.org/downloads/buildroot-2016.05.tar.bz2
解压后运行
make qemu_x86_64_defconfig make
编译完成后,根据board/qemu/x86_64/readme.txt里描述的命令,可以在qemu里运行起来刚才编译好的linux系统。
qemu-system-x86_64 -M pc -kernel output/images/bzImage -drive file=output/images/rootfs.ext2,if=virtio,format=raw -append root=/dev/vda -net nic,model=virtio -net user
这个默认的系统log输出被重定向到了虚拟机的“屏幕”上,而非shell上,不能回滚,使得调试起来很不方便。我们需要修改一些东西把log重定向到linux的shell上。首先是编辑buildroot目录下的.config文件。
BR2_TARGET_GENERIC_GETTY_PORT="tty1"
改成
BR2_TARGET_GENERIC_GETTY_PORT="ttyS0"
然后重新编译。等到编译完成后运行下面修改过的命令,就得到我们想要的结果了。
make qemu-system-x86_64 -M pc -kernel output/images/bzImage -drive file=output/images/rootfs.ext2,if=virtio,format=raw -append "console=ttyS0 root=/dev/vda" -net nic,model=virtio -net user -serial stdio
下面,我们再修改一些命令,加上nvme的支持。
qemu-img create -f raw nvme.img 1G qemu-system-x86_64 -M pc -kernel output/images/bzImage -drive file=output/images/rootfs.ext2,if=virtio,format=raw -append "console=ttyS0 root=/dev/vda" -net nic,model=virtio -net user -serial stdio -drive file=nvme.img,if=none,format=raw,id=drv0 -device nvme,drive=drv0,serial=foo
linux系统起来后,我们可以在/dev下面查看到nvme相关的设备了。
# ls -l /dev crw------- 1 root root 253, 0 Jun 3 13:00 nvme0 brw------- 1 root root 259, 0 Jun 3 13:00 nvme0n1
自此,我们的动手实践稍作暂停,可以去学习下nvme的代码了。在遇到问题的时候,我们可以修改代码并在qemu里运行查看效果,真棒!
RTFSC - Read The Fucking Source Code
nvme驱动代码的分析基于linux内核版本4.5.3,为什么选择这个版本?主要是因为buildroot-2016.05默认选择的是这个版本的内核。我们也可以手动修改内核的版本,但这里就不做详述了。nvme的代码位于drivers/nvme目录内,文件不多,主要就两个文件:core.c和pci.c。分析驱动,首先是要找到这个驱动的入口。module_init把函数nvme_init声明为这个驱动的入口,在linux加载过程中会自动被调用。
static int __init nvme_init(void)
{
int result;
init_waitqueue_head(&nvme_kthread_wait);
nvme_workq = alloc_workqueue("nvme", WQ_UNBOUND | WQ_MEM_RECLAIM, 0);
if (!nvme_workq)
return -ENOMEM;
result = nvme_core_init();
if (result < 0)
goto kill_workq;
result = pci_register_driver(&nvme_driver);
if (result)
goto core_exit;
return 0;
core_exit:
nvme_core_exit();
kill_workq:
destroy_workqueue(nvme_workq);
return result;
}
static void __exit nvme_exit(void)
{
pci_unregister_driver(&nvme_driver);
nvme_core_exit();
destroy_workqueue(nvme_workq);
BUG_ON(nvme_thread && !IS_ERR(nvme_thread));
_nvme_check_size();
}
module_init(nvme_init);
module_exit(nvme_exit);nvme_init流程分析:
创建一个全局的workqueue,有了这个workqueue之后,很多的work就可以丢到这个workqueue里执行了。后面会提到的两个很重要的scan_work和reset_work就是在这个workqueue里被调度运行的。
调用nvme_core_init。
调用pci_register_driver。
int __init nvme_core_init(void)
{
int result;
result = register_blkdev(nvme_major, "nvme");
if (result < 0)
return result;
else if (result > 0)
nvme_major = result;
result = __register_chrdev(nvme_char_major, 0, NVME_MINORS, "nvme",
&nvme_dev_fops);
if (result < 0)
goto unregister_blkdev;
else if (result > 0)
nvme_char_major = result;
nvme_class = class_create(THIS_MODULE, "nvme");
if (IS_ERR(nvme_class)) {
result = PTR_ERR(nvme_class);
goto unregister_chrdev;
}
return 0;
unregister_chrdev:
__unregister_chrdev(nvme_char_major, 0, NVME_MINORS, "nvme");
unregister_blkdev:
unregister_blkdev(nvme_major, "nvme");
return result;
}nvme_core_init流程分析:
调用register_blkdev注册一个名字叫nvme的块设备。
调用__register_chrdev注册一个名字叫nvme的字符设备。这些注册的设备并不会在/dev下出现,而是在/proc/devices下,代表某种设备对应的主设备号,而不是设备的实例。这里要注意一点就是,字符设备和块设备的主设备号是不相关的,所以完全可以一样,代表的是完全无关的设备。我们在这里获得的字符设备和块设备的主设备号就正好都是253。
# cat /proc/devices Character devices: 1 mem 2 pty 3 ttyp 4 /dev/vc/0 4 tty 4 ttyS 5 /dev/tty 5 /dev/console 5 /dev/ptmx 7 vcs 10 misc 13 input 29 fb 116 alsa 128 ptm 136 pts 180 usb 189 usb_device 226 drm 253 nvme 254 bsg Block devices: 259 blkext 8 sd 65 sd 66 sd 67 sd 68 sd 69 sd 70 sd 71 sd 128 sd 129 sd 130 sd 131 sd 132 sd 133 sd 134 sd 135 sd 253 nvme 254 virtblk
细心的读者可能会发现,刚才我们列出来的一个字符设备nvme0,它的主设备号确实是253。但是块设备nvme0n1的主设备号是259,也就是blkext,这是为什么那?先等等,到后面注册这个设备实例的时候我们再看。
回到nvme_init,pci_register_driver注册了一个pci驱动。这里有几个重要的东西,一个是vendor id和device id,我们可以看到有一条是PCI_VDEVICE(INTEL, 0x5845),有了这个,这个驱动就能跟pci总线枚举出来的设备匹配起来,从而正确的加载驱动了。
static const struct pci_device_id nvme_id_table[] = {
{ PCI_VDEVICE(INTEL, 0x0953),
.driver_data = NVME_QUIRK_STRIPE_SIZE, },
{ PCI_VDEVICE(INTEL, 0x5845), /* Qemu emulated controller */
.driver_data = NVME_QUIRK_IDENTIFY_CNS, },
{ PCI_DEVICE_CLASS(PCI_CLASS_STORAGE_EXPRESS, 0xffffff) },
{ PCI_DEVICE(PCI_VENDOR_ID_APPLE, 0x2001) },
{ 0, }
};
MODULE_DEVICE_TABLE(pci, nvme_id_table);
static struct pci_driver nvme_driver = {
.name = "nvme",
.id_table = nvme_id_table,
.probe = nvme_probe,
.remove = nvme_remove,
.shutdown = nvme_shutdown,
.driver = {
.pm = &nvme_dev_pm_ops,
},
.err_handler = &nvme_err_handler,
};在linux里我们通过lspci命令来查看当前的pci设备,发现nvme设备的device id就是0x5845。
# lspci -k 00:00.0 Class 0600: 8086:1237 00:01.0 Class 0601: 8086:7000 00:01.1 Class 0101: 8086:7010 ata_piix 00:01.3 Class 0680: 8086:7113 00:02.0 Class 0300: 1234:1111 bochs-drm 00:03.0 Class 0200: 1af4:1000 virtio-pci 00:04.0 Class 0108: 8086:5845 nvme 00:05.0 Class 0100: 1af4:1001 virtio-pci
pci_register_driver还有一个重要的事情就是设置probe函数。有了probe函数,当设备和驱动匹配了之后,相应驱动的probe函数就会被调用,来实现驱动的加载。所以nvme_init返回后,这个驱动就啥事不做了,直到pci总线枚举出了这个nvme设备,然后就会调用我们的nvme_probe。
static int nvme_probe(struct pci_dev *pdev, const struct pci_device_id *id)
{
int node, result = -ENOMEM;
struct nvme_dev *dev;
node = dev_to_node(&pdev->dev);
if (node == NUMA_NO_NODE)
set_dev_node(&pdev->dev, 0);
dev = kzalloc_node(sizeof(*dev), GFP_KERNEL, node);
if (!dev)
return -ENOMEM;
dev->entry = kzalloc_node(num_possible_cpus() * sizeof(*dev->entry),
GFP_KERNEL, node);
if (!dev->entry)
goto free;
dev->queues = kzalloc_node((num_possible_cpus() + 1) * sizeof(void *),
GFP_KERNEL, node);
if (!dev->queues)
goto free;
dev->dev = get_device(&pdev->dev);
pci_set_drvdata(pdev, dev);
result = nvme_dev_map(dev);
if (result)
goto free;
INIT_LIST_HEAD(&dev->node);
INIT_WORK(&dev->scan_work, nvme_dev_scan);
INIT_WORK(&dev->reset_work, nvme_reset_work);
INIT_WORK(&dev->remove_work, nvme_remove_dead_ctrl_work);
mutex_init(&dev->shutdown_lock);
init_completion(&dev->ioq_wait);
result = nvme_setup_prp_pools(dev);
if (result)
goto put_pci;
result = nvme_init_ctrl(&dev->ctrl, &pdev->dev, &nvme_pci_ctrl_ops,
id->driver_data);
if (result)
goto release_pools;
queue_work(nvme_workq, &dev->reset_work);
return 0;
release_pools:
nvme_release_prp_pools(dev);
put_pci:
put_device(dev->dev);
nvme_dev_unmap(dev);
free:
kfree(dev->queues);
kfree(dev->entry);
kfree(dev);
return result;
}nvme_probe流程分析:
为dev、dev->entry、dev->queues分配空间。entry保存的是msi相关的信息,为每个cpu core分配一个。queues为每个core分配一个io queue,所有的core共享一个admin queue。这里的queue的概念,更严格的说,是一组submission queue和completion queue的集合。
调用nvme_dev_map。
初始化三个work变量,关联回掉函数。
调用nvme_setup_prp_pools。
调用nvme_init_ctrl
通过workqueue调度dev->reset_work,也就是调度nvme_reset_work函数。
static int nvme_dev_map(struct nvme_dev *dev)
{
int bars;
struct pci_dev *pdev = to_pci_dev(dev->dev);
bars = pci_select_bars(pdev, IORESOURCE_MEM);
if (!bars)
return -ENODEV;
if (pci_request_selected_regions(pdev, bars, "nvme"))
return -ENODEV;
dev->bar = ioremap(pci_resource_start(pdev, 0), 8192);
if (!dev->bar)
goto release;
return 0;
release:
pci_release_regions(pdev);
return -ENODEV;
}nvme_dev_map流程分析:
调用pci_select_bars,这个函数的返回值是一个mask值,每一位代表一个bar(base address register),哪一位被置位了,就代表哪一个bar为非零。这个涉及到pci的协议,pci协议里规定了pci设备的配置空间里有6个32位的bar寄存器,代表了pci设备上的一段内存空间(memory、io)。
在代码中我们可以尝试着增加一些调试代码,以便我们更好的理解。在修改好代码后,我们需要在buildroot目录下重新编译内核,这样可以很快速的得到一个新的内核,然后运行看结果。我查看过pci_select_bars的返回值,是0x11,代表bar0和bar4是非零的。
make linux-rebuild
调用pci_request_selected_regions,这个函数的一个参数就是之前调用pci_select_bars返回的mask值,作用就是把对应的这个几个bar保留起来,不让别人使用。
不调用pci_request_selected_regions的话/proc/iomem如下
# cat /proc/iomem 08000000-febfffff : PCI Bus 0000:00 fd000000-fdffffff : 0000:00:02.0 fd000000-fdffffff : bochs-drm feb80000-febbffff : 0000:00:03.0 febc0000-febcffff : 0000:00:02.0 febd0000-febd1fff : 0000:00:04.0 febd2000-febd2fff : 0000:00:02.0 febd2000-febd2fff : bochs-drm febd3000-febd3fff : 0000:00:03.0 febd4000-febd4fff : 0000:00:04.0 febd5000-febd5fff : 0000:00:05.0
调用pci_request_selected_regions的话/proc/iomem如下,会多出两项nvme,bar0对应的物理地址就是0xfebd0000,bar4对应的是0xfebd4000。
# cat /proc/iomem 08000000-febfffff : PCI Bus 0000:00 fd000000-fdffffff : 0000:00:02.0 fd000000-fdffffff : bochs-drm feb80000-febbffff : 0000:00:03.0 febc0000-febcffff : 0000:00:02.0 febd0000-febd1fff : 0000:00:04.0 febd0000-febd1fff : nvme febd2000-febd2fff : 0000:00:02.0 febd2000-febd2fff : bochs-drm febd3000-febd3fff : 0000:00:03.0 febd4000-febd4fff : 0000:00:04.0 febd4000-febd4fff : nvme febd5000-febd5fff : 0000:00:05.0
调用ioremap。前面说到bar0对应的物理地址是0xfebd0000,在linux中我们无法直接访问物理地址,需要映射到虚拟地址,ioremap就是这个作用。映射完后,我们访问dev->bar就可以直接操作nvme设备上的寄存器了。但是代码中,并没有根据pci_select_bars的返回值来决定映射哪个bar,而是直接hard code成映射bar0,原因是nvme协议中强制规定了bar0就是内存映射的基址。而bar4是自定义用途,暂时还不确定有什么用。
static int nvme_setup_prp_pools(struct nvme_dev *dev)
{
dev->prp_page_pool = dma_pool_create("prp list page", dev->dev,
PAGE_SIZE, PAGE_SIZE, 0);
if (!dev->prp_page_pool)
return -ENOMEM;
/* Optimisation for I/Os between 4k and 128k */
dev->prp_small_pool = dma_pool_create("prp list 256", dev->dev,
256, 256, 0);
if (!dev->prp_small_pool) {
dma_pool_destroy(dev->prp_page_pool);
return -ENOMEM;
}
return 0;
}回到nvme_probe来看nvme_setup_prp_pools,主要是创建dma pool,后面就可以通过其他dma函数从dma pool中获得memory了。这里一个pool里提供的是256字节大小的内存,一个提供的是4K大小的,主要是为了对于不一样长度的prp list来做优化。
int nvme_init_ctrl(struct nvme_ctrl *ctrl, struct device *dev,
const struct nvme_ctrl_ops *ops, unsigned long quirks)
{
int ret;
INIT_LIST_HEAD(&ctrl->namespaces);
mutex_init(&ctrl->namespaces_mutex);
kref_init(&ctrl->kref);
ctrl->dev = dev;
ctrl->ops = ops;
ctrl->quirks = quirks;
ret = nvme_set_instance(ctrl);
if (ret)
goto out;
ctrl->device = device_create_with_groups(nvme_class, ctrl->dev,
MKDEV(nvme_char_major, ctrl->instance),
dev, nvme_dev_attr_groups,
"nvme%d", ctrl->instance);
if (IS_ERR(ctrl->device)) {
ret = PTR_ERR(ctrl->device);
goto out_release_instance;
}
get_device(ctrl->device);
dev_set_drvdata(ctrl->device, ctrl);
ida_init(&ctrl->ns_ida);
spin_lock(&dev_list_lock);
list_add_tail(&ctrl->node, &nvme_ctrl_list);
spin_unlock(&dev_list_lock);
return 0;
out_release_instance:
nvme_release_instance(ctrl);
out:
return ret;
}回到nvme_probe,nvme_init_ctrl里主要做的事情就是通过device_create_with_groups创建一个名字叫nvme0的字符设备,也就是我们之前见到的。
crw------- 1 root root 253, 0 Jun 3 13:00 nvme0
有了这个字符设备之后,我们就可以通过open、ioctl之类的接口去操作它了。
static const struct file_operations nvme_dev_fops = {
.owner = THIS_MODULE,
.open = nvme_dev_open,
.release = nvme_dev_release,
.unlocked_ioctl = nvme_dev_ioctl,
.compat_ioctl = nvme_dev_ioctl,
};而nvme0的这个0是通过nvme_set_instance得到的。这里面主要是通过ida_get_new可以得到一个唯一的索引值。
static int nvme_set_instance(struct nvme_ctrl *ctrl)
{
int instance, error;
do {
if (!ida_pre_get(&nvme_instance_ida, GFP_KERNEL))
return -ENODEV;
spin_lock(&dev_list_lock);
error = ida_get_new(&nvme_instance_ida, &instance);
spin_unlock(&dev_list_lock);
} while (error == -EAGAIN);
if (error)
return -ENODEV;
ctrl->instance = instance;
return 0;
}再次回到nvme_probe,dev->reset_work被调度,也就是nvme_reset_work被调用了。
nvme_reset_work — 一个很长的work
static void nvme_reset_work(struct work_struct *work)
{
struct nvme_dev *dev = container_of(work, struct nvme_dev, reset_work);
int result = -ENODEV;
if (WARN_ON(test_bit(NVME_CTRL_RESETTING, &dev->flags)))
goto out;
/*
* If we're called to reset a live controller first shut it down before
* moving on.
*/
if (dev->ctrl.ctrl_config & NVME_CC_ENABLE)
nvme_dev_disable(dev, false);
set_bit(NVME_CTRL_RESETTING, &dev->flags);
result = nvme_pci_enable(dev);
if (result)
goto out;
result = nvme_configure_admin_queue(dev);
if (result)
goto out;
nvme_init_queue(dev->queues[0], 0);
result = nvme_alloc_admin_tags(dev);
if (result)
goto out;
result = nvme_init_identify(&dev->ctrl);
if (result)
goto out;
result = nvme_setup_io_queues(dev);
if (result)
goto out;
dev->ctrl.event_limit = NVME_NR_AEN_COMMANDS;
result = nvme_dev_list_add(dev);
if (result)
goto out;
/*
* Keep the controller around but remove all namespaces if we don't have
* any working I/O queue.
*/
if (dev->online_queues < 2) {
dev_warn(dev->dev, "IO queues not created\n");
nvme_remove_namespaces(&dev->ctrl);
} else {
nvme_start_queues(&dev->ctrl);
nvme_dev_add(dev);
}
clear_bit(NVME_CTRL_RESETTING, &dev->flags);
return;
out:
nvme_remove_dead_ctrl(dev, result);
}nvme_reset_work流程分析:
首先通过NVME_CTRL_RESETTING标志来确保nvme_reset_work不会被重复进入。
调用nvme_pci_enable。
调用nvme_configure_admin_queue。
调用nvme_init_queue
调用nvme_alloc_admin_tags
调用nvme_init_identify
调用nvme_setup_io_queues
调用nvme_dev_list_add
static int nvme_pci_enable(struct nvme_dev *dev)
{
u64 cap;
int result = -ENOMEM;
struct pci_dev *pdev = to_pci_dev(dev->dev);
if (pci_enable_device_mem(pdev))
return result;
dev->entry[0].vector = pdev->irq;
pci_set_master(pdev);
if (dma_set_mask_and_coherent(dev->dev, DMA_BIT_MASK(64)) &&
dma_set_mask_and_coherent(dev->dev, DMA_BIT_MASK(32)))
goto disable;
if (readl(dev->bar + NVME_REG_CSTS) == -1) {
result = -ENODEV;
goto disable;
}
/*
* Some devices don't advertse INTx interrupts, pre-enable a single
* MSIX vec for setup. We'll adjust this later.
*/
if (!pdev->irq) {
result = pci_enable_msix(pdev, dev->entry, 1);
if (result < 0)
goto disable;
}
cap = lo_hi_readq(dev->bar + NVME_REG_CAP);
dev->q_depth = min_t(int, NVME_CAP_MQES(cap) + 1, NVME_Q_DEPTH);
dev->db_stride = 1 << NVME_CAP_STRIDE(cap);
dev->dbs = dev->bar + 4096;
/*
* Temporary fix for the Apple controller found in the MacBook8,1 and
* some MacBook7,1 to avoid controller resets and data loss.
*/
if (pdev->vendor == PCI_VENDOR_ID_APPLE && pdev->device == 0x2001) {
dev->q_depth = 2;
dev_warn(dev->dev, "detected Apple NVMe controller, set "
"queue depth=%u to work around controller resets\n",
dev->q_depth);
}
if (readl(dev->bar + NVME_REG_VS) >= NVME_VS(1, 2))
dev->cmb = nvme_map_cmb(dev);
pci_enable_pcie_error_reporting(pdev);
pci_save_state(pdev);
return 0;
disable:
pci_disable_device(pdev);
return result;
}nvme_pci_enable流程分析:
调用pci_enable_device_mem来使能nvme设备的内存空间,也就是之前映射的bar0空间。
之后就可以通过readl(dev->bar + NVME_REG_CSTS)来直接操作nvme设备上的控制寄存器了,也就是nvme协议中的如下这个表。
pci有两种中断模式,一种是INT,另一种是MSI。假如不支持INT模式的话,就使能MSI模式。在这里使用的是INT模式,irq号为11。但是这里还是为admin queue的msi中断号dev->entry[0].vector附了值,看来后面是可能会用到msi的。
# cat /proc/interrupts CPU0 0: 86 IO-APIC 2-edge timer 1: 9 IO-APIC 1-edge i8042 4: 250 IO-APIC 4-edge serial 9: 0 IO-APIC 9-fasteoi acpi 10: 100 IO-APIC 10-fasteoi virtio1 11: 13 IO-APIC 11-fasteoi virtio0, nvme0q0, nvme0q1 12: 125 IO-APIC 12-edge i8042 14: 0 IO-APIC 14-edge ata_piix 15: 5 IO-APIC 15-edge ata_piix
从CAP寄存器中获得一些配置参数,并把dev->dbs设置成dev->bar+4096。4096的由来是上面表里doorbell寄存器的起始地址是0x1000。
假如nvme协议的版本大于等于1.2的话,需要调用nvme_map_cmb映射controller memory buffer。但是现在2.5版的qemu实现的nvme是1.1版的,所以这些不被支持。但是作为1.2版本的一个新加功能,我在这里还是分析一下。CMB的主要作用是把SQ/CQ存储的位置从host memory搬到device memory来提升性能,改善延时。其实这个函数里做的事情和之前做的pci映射工作没有太大区别,但是有一点需要注意,这里映射用的是ioremap_wc而不是ioremap。
static void __iomem *nvme_map_cmb(struct nvme_dev *dev)
{
u64 szu, size, offset;
u32 cmbloc;
resource_size_t bar_size;
struct pci_dev *pdev = to_pci_dev(dev->dev);
void __iomem *cmb;
dma_addr_t dma_addr;
if (!use_cmb_sqes)
return NULL;
dev->cmbsz = readl(dev->bar + NVME_REG_CMBSZ);
if (!(NVME_CMB_SZ(dev->cmbsz)))
return NULL;
cmbloc = readl(dev->bar + NVME_REG_CMBLOC);
szu = (u64)1 << (12 + 4 * NVME_CMB_SZU(dev->cmbsz));
size = szu * NVME_CMB_SZ(dev->cmbsz);
offset = szu * NVME_CMB_OFST(cmbloc);
bar_size = pci_resource_len(pdev, NVME_CMB_BIR(cmbloc));
if (offset > bar_size)
return NULL;
/*
* Controllers may support a CMB size larger than their BAR,
* for example, due to being behind a bridge. Reduce the CMB to
* the reported size of the BAR
*/
if (size > bar_size - offset)
size = bar_size - offset;
dma_addr = pci_resource_start(pdev, NVME_CMB_BIR(cmbloc)) + offset;
cmb = ioremap_wc(dma_addr, size);
if (!cmb)
return NULL;
dev->cmb_dma_addr = dma_addr;
dev->cmb_size = size;
return cmb;
}我们先来看看ioremap,其实它就等价于ioremap_nocache。因为我们重映射很多情况下映射的是寄存器之类的东西,要是使用的cache的话,会产生不可预测的问题,所以默认情况下cache是不能使用的。而ioremap_wc使用了一种叫write combining的cache机制。据我所知,这是arm中没有的功能,而在x86里有实现。首先要明确的是,设置成WC之后,就和L1,L2,L3的cache没有任何关系了。在x86里,有另外一块存储区域叫WC buffer(通常是一个buffer是64字节大小,不同平台有不同数量个buffer)。设置成WC的内存,对其进行读操作时,直接从内存里读取,绕过cache。但是当对其进行写操作的时候,区别就来了。新的数据不会被直接写进内存,而是缓存在WC buffer里,等到WC buffer满了或者执行了某些指令后,WC buffer里的数据会一下子被写进内存里去。不管怎么说,这还是一种cache机制,在这里能使用的主要原因是因为SQ/CQ的内容对写进去的顺序是没有要求的,直到最后的doorbell寄存器被修改,或者设备发出一个中断后,才有可能有人去读取,所以可以用到这种优化。
/*
* The default ioremap() behavior is non-cached:
*/
static inline void __iomem *ioremap(resource_size_t offset, unsigned long size)
{
return ioremap_nocache(offset, size);
}回到nvme_reset_work分析nvme_configure_admin_queue。
static int nvme_configure_admin_queue(struct nvme_dev *dev)
{
int result;
u32 aqa;
u64 cap = lo_hi_readq(dev->bar + NVME_REG_CAP);
struct nvme_queue *nvmeq;
dev->subsystem = readl(dev->bar + NVME_REG_VS) >= NVME_VS(1, 1) ?
NVME_CAP_NSSRC(cap) : 0;
if (dev->subsystem &&
(readl(dev->bar + NVME_REG_CSTS) & NVME_CSTS_NSSRO))
writel(NVME_CSTS_NSSRO, dev->bar + NVME_REG_CSTS);
result = nvme_disable_ctrl(&dev->ctrl, cap);
if (result < 0)
return result;
nvmeq = dev->queues[0];
if (!nvmeq) {
nvmeq = nvme_alloc_queue(dev, 0, NVME_AQ_DEPTH);
if (!nvmeq)
return -ENOMEM;
}
aqa = nvmeq->q_depth - 1;
aqa |= aqa << 16;
writel(aqa, dev->bar + NVME_REG_AQA);
lo_hi_writeq(nvmeq->sq_dma_addr, dev->bar + NVME_REG_ASQ);
lo_hi_writeq(nvmeq->cq_dma_addr, dev->bar + NVME_REG_ACQ);
result = nvme_enable_ctrl(&dev->ctrl, cap);
if (result)
goto free_nvmeq;
nvmeq->cq_vector = 0;
result = queue_request_irq(dev, nvmeq, nvmeq->irqname);
if (result) {
nvmeq->cq_vector = -1;
goto free_nvmeq;
}
return result;
free_nvmeq:
nvme_free_queues(dev, 0);
return result;
}nvme_configure_admin_queue流程分析:
从CAP寄存器中获悉对Subsystem Reset的支持
调用nvme_disable_ctrl
调用nvme_alloc_queue
调用nvme_enable_ctrl
调用queue_request_irq
int nvme_disable_ctrl(struct nvme_ctrl *ctrl, u64 cap)
{
int ret;
ctrl->ctrl_config &= ~NVME_CC_SHN_MASK;
ctrl->ctrl_config &= ~NVME_CC_ENABLE;
ret = ctrl->ops->reg_write32(ctrl, NVME_REG_CC, ctrl->ctrl_config);
if (ret)
return ret;
return nvme_wait_ready(ctrl, cap, false);
}这里的ctrl->ops就是之前nvme_init_ctrl时传进去的nvme_pci_ctrl_ops,reg_write32通过NVME_REG_CC寄存器disable设备。
static int nvme_pci_reg_read32(struct nvme_ctrl *ctrl, u32 off, u32 *val)
{
*val = readl(to_nvme_dev(ctrl)->bar + off);
return 0;
}
static int nvme_pci_reg_write32(struct nvme_ctrl *ctrl, u32 off, u32 val)
{
writel(val, to_nvme_dev(ctrl)->bar + off);
return 0;
}
static const struct nvme_ctrl_ops nvme_pci_ctrl_ops = {
.reg_read32 = nvme_pci_reg_read32,
.reg_write32 = nvme_pci_reg_write32,
.reg_read64 = nvme_pci_reg_read64,
.io_incapable = nvme_pci_io_incapable,
.reset_ctrl = nvme_pci_reset_ctrl,
.free_ctrl = nvme_pci_free_ctrl,
};然后通过读取状态寄存器NVME_REG_CSTS来等待设备真正停止。超时上限是根据CAP寄存器的Timeout域来计算出来的,每个单位代表500ms。
static int nvme_wait_ready(struct nvme_ctrl *ctrl, u64 cap, bool enabled)
{
unsigned long timeout =
((NVME_CAP_TIMEOUT(cap) + 1) * HZ / 2) + jiffies;
u32 csts, bit = enabled ? NVME_CSTS_RDY : 0;
int ret;
while ((ret = ctrl->ops->reg_read32(ctrl, NVME_REG_CSTS, &csts)) == 0) {
if ((csts & NVME_CSTS_RDY) == bit)
break;
msleep(100);
if (fatal_signal_pending(current))
return -EINTR;
if (time_after(jiffies, timeout)) {
dev_err(ctrl->dev,
"Device not ready; aborting %s\n", enabled ?
"initialisation" : "reset");
return -ENODEV;
}
}
return ret;
}回到nvme_configure_admin_queue分析nvme_alloc_queue。
static struct nvme_queue *nvme_alloc_queue(struct nvme_dev *dev, int qid,
int depth)
{
struct nvme_queue *nvmeq = kzalloc(sizeof(*nvmeq), GFP_KERNEL);
if (!nvmeq)
return NULL;
nvmeq->cqes = dma_zalloc_coherent(dev->dev, CQ_SIZE(depth),
&nvmeq->cq_dma_addr, GFP_KERNEL);
if (!nvmeq->cqes)
goto free_nvmeq;
if (nvme_alloc_sq_cmds(dev, nvmeq, qid, depth))
goto free_cqdma;
nvmeq->q_dmadev = dev->dev;
nvmeq->dev = dev;
snprintf(nvmeq->irqname, sizeof(nvmeq->irqname), "nvme%dq%d",
dev->ctrl.instance, qid);
spin_lock_init(&nvmeq->q_lock);
nvmeq->cq_head = 0;
nvmeq->cq_phase = 1;
nvmeq->q_db = &dev->dbs[qid * 2 * dev->db_stride];
nvmeq->q_depth = depth;
nvmeq->qid = qid;
nvmeq->cq_vector = -1;
dev->queues[qid] = nvmeq;
/* make sure queue descriptor is set before queue count, for kthread */
mb();
dev->queue_count++;
return nvmeq;
free_cqdma:
dma_free_coherent(dev->dev, CQ_SIZE(depth), (void *)nvmeq->cqes,
nvmeq->cq_dma_addr);
free_nvmeq:
kfree(nvmeq);
return NULL;
}nvme_alloc_queue流程分析:
调用dma_zalloc_coherent为completion queue分配内存以供DMA使用。nvmeq->cqes为申请到的内存的虚拟地址,供内核使用。而nvmeq->cq_dma_addr就是这块内存的物理地址,供DMA控制器使用。
nvmeq->irqname是用来注册中断的时候的名字,从nvme%dq%d可以看到,就是最后生成的nvme0q0和nvme0q1,一个是给admin queue的,一个是给io queue的。
调用nvme_alloc_sq_cmd来处理submission queue,假如nvme版本是1.2或者以上的,并且cmb支持submission queue,那就使用cmb。要不然就和completion queue一样使用dma_alloc_coherent来分配内存。
static int nvme_alloc_sq_cmds(struct nvme_dev *dev, struct nvme_queue *nvmeq,
int qid, int depth)
{
if (qid && dev->cmb && use_cmb_sqes && NVME_CMB_SQS(dev->cmbsz)) {
unsigned offset = (qid - 1) * roundup(SQ_SIZE(depth),
dev->ctrl.page_size);
nvmeq->sq_dma_addr = dev->cmb_dma_addr + offset;
nvmeq->sq_cmds_io = dev->cmb + offset;
} else {
nvmeq->sq_cmds = dma_alloc_coherent(dev->dev, SQ_SIZE(depth),
&nvmeq->sq_dma_addr, GFP_KERNEL);
if (!nvmeq->sq_cmds)
return -ENOMEM;
}
return 0;
}再次回到nvme_configure_admin_queue,看看nvme_enable_ctrl。这个函数并没有太多特别的,可以简单理解为前面分析过的nvme_disable_ctrl的逆向操作。
int nvme_enable_ctrl(struct nvme_ctrl *ctrl, u64 cap)
{
/*
* Default to a 4K page size, with the intention to update this
* path in the future to accomodate architectures with differing
* kernel and IO page sizes.
*/
unsigned dev_page_min = NVME_CAP_MPSMIN(cap) + 12, page_shift = 12;
int ret;
if (page_shift < dev_page_min) {
dev_err(ctrl->dev,
"Minimum device page size %u too large for host (%u)\n",
1 << dev_page_min, 1 << page_shift);
return -ENODEV;
}
ctrl->page_size = 1 << page_shift;
ctrl->ctrl_config = NVME_CC_CSS_NVM;
ctrl->ctrl_config |= (page_shift - 12) << NVME_CC_MPS_SHIFT;
ctrl->ctrl_config |= NVME_CC_ARB_RR | NVME_CC_SHN_NONE;
ctrl->ctrl_config |= NVME_CC_IOSQES | NVME_CC_IOCQES;
ctrl->ctrl_config |= NVME_CC_ENABLE;
ret = ctrl->ops->reg_write32(ctrl, NVME_REG_CC, ctrl->ctrl_config);
if (ret)
return ret;
return nvme_wait_ready(ctrl, cap, true);
}回到nvme_configure_admin_queue,看最后一个函数queue_request_irq。这个函数主要的工作是设置中断处理函数,默认情况下不使用线程化的中断处理,而是使用中断上下文的中断处理。
static int queue_request_irq(struct nvme_dev *dev, struct nvme_queue *nvmeq,
const char *name)
{
if (use_threaded_interrupts)
return request_threaded_irq(dev->entry[nvmeq->cq_vector].vector,
nvme_irq_check, nvme_irq, IRQF_SHARED,
name, nvmeq);
return request_irq(dev->entry[nvmeq->cq_vector].vector, nvme_irq,
IRQF_SHARED, name, nvmeq);
}一路返回到nvme_reset_work,分析nvme_init_queue。根据传到nvme_init_queue的参数可知,这里初始化的是queue 0,也就是admin queue。
static void nvme_init_queue(struct nvme_queue *nvmeq, u16 qid)
{
struct nvme_dev *dev = nvmeq->dev;
spin_lock_irq(&nvmeq->q_lock);
nvmeq->sq_tail = 0;
nvmeq->cq_head = 0;
nvmeq->cq_phase = 1;
nvmeq->q_db = &dev->dbs[qid * 2 * dev->db_stride];
memset((void *)nvmeq->cqes, 0, CQ_SIZE(nvmeq->q_depth));
dev->online_queues++;
spin_unlock_irq(&nvmeq->q_lock);
}这个函数做的事情不多,主要是对nvme_queue的成员变量进行一些初始化。q_db指向这个queue对应的doorbell寄存器的地址。
回到nvme_reset_work,分析nvme_alloc_admin_tags。
static int nvme_alloc_admin_tags(struct nvme_dev *dev)
{
if (!dev->ctrl.admin_q) {
dev->admin_tagset.ops = &nvme_mq_admin_ops;
dev->admin_tagset.nr_hw_queues = 1;
/*
* Subtract one to leave an empty queue entry for 'Full Queue'
* condition. See NVM-Express 1.2 specification, section 4.1.2.
*/
dev->admin_tagset.queue_depth = NVME_AQ_BLKMQ_DEPTH - 1;
dev->admin_tagset.timeout = ADMIN_TIMEOUT;
dev->admin_tagset.numa_node = dev_to_node(dev->dev);
dev->admin_tagset.cmd_size = nvme_cmd_size(dev);
dev->admin_tagset.driver_data = dev;
if (blk_mq_alloc_tag_set(&dev->admin_tagset))
return -ENOMEM;
dev->ctrl.admin_q = blk_mq_init_queue(&dev->admin_tagset);
if (IS_ERR(dev->ctrl.admin_q)) {
blk_mq_free_tag_set(&dev->admin_tagset);
return -ENOMEM;
}
if (!blk_get_queue(dev->ctrl.admin_q)) {
nvme_dev_remove_admin(dev);
dev->ctrl.admin_q = NULL;
return -ENODEV;
}
} else
blk_mq_start_stopped_hw_queues(dev->ctrl.admin_q, true);
return 0;
}nvme_alloc_admin_tags流程分析:
blk_mq_alloc_tag_set申请tag set并和request_queue关联起来,并且会对queue_depth(254)个request(index 0-253)做初始化。初始化函数就是nvme_mq_admin_ops传进去的nvme_admin_init_request。
static struct blk_mq_ops nvme_mq_admin_ops = {
.queue_rq = nvme_queue_rq,
.complete = nvme_complete_rq,
.map_queue = blk_mq_map_queue,
.init_hctx = nvme_admin_init_hctx,
.exit_hctx = nvme_admin_exit_hctx,
.init_request = nvme_admin_init_request,
.timeout = nvme_timeout,
};
static int nvme_admin_init_request(void *data, struct request *req,
unsigned int hctx_idx, unsigned int rq_idx,
unsigned int numa_node)
{
struct nvme_dev *dev = data;
struct nvme_iod *iod = blk_mq_rq_to_pdu(req);
struct nvme_queue *nvmeq = dev->queues[0];
BUG_ON(!nvmeq);
iod->nvmeq = nvmeq;
return 0;
}blk_mq_init_queue初始化request_queue并赋值给dev->ctrl.admin_q,会调用nvme_admin_init_hctx,并会调用nvme_admin_init_request初始化index 254的request,这点很奇怪。
static int nvme_admin_init_hctx(struct blk_mq_hw_ctx *hctx, void *data,
unsigned int hctx_idx)
{
struct nvme_dev *dev = data;
struct nvme_queue *nvmeq = dev->queues[0];
WARN_ON(hctx_idx != 0);
WARN_ON(dev->admin_tagset.tags[0] != hctx->tags);
WARN_ON(nvmeq->tags);
hctx->driver_data = nvmeq;
nvmeq->tags = &dev->admin_tagset.tags[0];
return 0;
}回到nvme_reset_work,分析nvme_init_identify。
int nvme_init_identify(struct nvme_ctrl *ctrl)
{
struct nvme_id_ctrl *id;
u64 cap;
int ret, page_shift;
ret = ctrl->ops->reg_read32(ctrl, NVME_REG_VS, &ctrl->vs);
if (ret) {
dev_err(ctrl->dev, "Reading VS failed (%d)\n", ret);
return ret;
}
ret = ctrl->ops->reg_read64(ctrl, NVME_REG_CAP, &cap);
if (ret) {
dev_err(ctrl->dev, "Reading CAP failed (%d)\n", ret);
return ret;
}
page_shift = NVME_CAP_MPSMIN(cap) + 12;
if (ctrl->vs >= NVME_VS(1, 1))
ctrl->subsystem = NVME_CAP_NSSRC(cap);
ret = nvme_identify_ctrl(ctrl, &id);
if (ret) {
dev_err(ctrl->dev, "Identify Controller failed (%d)\n", ret);
return -EIO;
}
ctrl->oncs = le16_to_cpup(&id->oncs);
atomic_set(&ctrl->abort_limit, id->acl + 1);
ctrl->vwc = id->vwc;
memcpy(ctrl->serial, id->sn, sizeof(id->sn));
memcpy(ctrl->model, id->mn, sizeof(id->mn));
memcpy(ctrl->firmware_rev, id->fr, sizeof(id->fr));
if (id->mdts)
ctrl->max_hw_sectors = 1 << (id->mdts + page_shift - 9);
else
ctrl->max_hw_sectors = UINT_MAX;
if ((ctrl->quirks & NVME_QUIRK_STRIPE_SIZE) && id->vs[3]) {
unsigned int max_hw_sectors;
ctrl->stripe_size = 1 << (id->vs[3] + page_shift);
max_hw_sectors = ctrl->stripe_size >> (page_shift - 9);
if (ctrl->max_hw_sectors) {
ctrl->max_hw_sectors = min(max_hw_sectors,
ctrl->max_hw_sectors);
} else {
ctrl->max_hw_sectors = max_hw_sectors;
}
}
nvme_set_queue_limits(ctrl, ctrl->admin_q);
kfree(id);
return 0;
}nvme_init_identify流程分析:
调用nvme_identify_ctrl
调用nvme_set_queue_limits
先来分析nvme_identify_ctrl
int nvme_identify_ctrl(struct nvme_ctrl *dev, struct nvme_id_ctrl **id)
{
struct nvme_command c = { };
int error;
/* gcc-4.4.4 (at least) has issues with initializers and anon unions */
c.identify.opcode = nvme_admin_identify;
c.identify.cns = cpu_to_le32(1);
*id = kmalloc(sizeof(struct nvme_id_ctrl), GFP_KERNEL);
if (!*id)
return -ENOMEM;
error = nvme_submit_sync_cmd(dev->admin_q, &c, *id,
sizeof(struct nvme_id_ctrl));
if (error)
kfree(*id);
return error;
}nvme_identify_ctrl流程分析:
创建一个opcode为nvme_admin_identify(0x6)的command。在这里我们会看到cpu_to_le32这样的函数,这些函数的主要用途是因为在nvme协议里规定的一些消息格式都是按照小端存储的,但是我们的主机可能是小端的x86,也可能是大端的arm或者其他类型,用了这样的函数就可以做到主机格式和小端之间的转换,让代码更好得跨平台。
通过nvme_submit_sync_cmd把命令发送给nvme设备
int __nvme_submit_sync_cmd(struct request_queue *q, struct nvme_command *cmd,
void *buffer, unsigned bufflen, u32 *result, unsigned timeout)
{
struct request *req;
int ret;
req = nvme_alloc_request(q, cmd, 0);
if (IS_ERR(req))
return PTR_ERR(req);
req->timeout = timeout ? timeout : ADMIN_TIMEOUT;
if (buffer && bufflen) {
ret = blk_rq_map_kern(q, req, buffer, bufflen, GFP_KERNEL);
if (ret)
goto out;
}
blk_execute_rq(req->q, NULL, req, 0);
if (result)
*result = (u32)(uintptr_t)req->special;
ret = req->errors;
out:
blk_mq_free_request(req);
return ret;
}__nvme_submit_sync_cmd流程分析:
调用nvme_alloc_request
调用blk_rq_map_kern
调用blk_execute_rq,其中会调用函数指针queue_rq指向的函数nvme_queue_rq。
先看下nvme_alloc_request,blk_mq_alloc_request从request_queue中申请一个request,然后初始化这个request的一些属性。这些属性都很重要,很多会直接影响到后续代码的执行流程。
struct request *nvme_alloc_request(struct request_queue *q,
struct nvme_command *cmd, unsigned int flags)
{
bool write = cmd->common.opcode & 1;
struct request *req;
req = blk_mq_alloc_request(q, write, flags);
if (IS_ERR(req))
return req;
req->cmd_type = REQ_TYPE_DRV_PRIV;
req->cmd_flags |= REQ_FAILFAST_DRIVER;
req->__data_len = 0;
req->__sector = (sector_t) -1;
req->bio = req->biotail = NULL;
req->cmd = (unsigned char *)cmd;
req->cmd_len = sizeof(struct nvme_command);
req->special = (void *)0;
return req;
}假如传进__nvme_submit_sync_cmd的buffer和bufflen参数都不为空的话,blk_rq_map_kern会被执行。在之前的nvme_alloc_request里,req->__data_len被设置成0。但是只要blk_rq_map_kern执行过之后,req->__data_len就会变成非零值,也就是映射的区域的大小。实测下来应该是以页(4096B)为单位的大小。
再分析下nvme_queue_rq。这个函数十分重要,实现了最终的命令的发送。
static int nvme_queue_rq(struct blk_mq_hw_ctx *hctx,
const struct blk_mq_queue_data *bd)
{
struct nvme_ns *ns = hctx->queue->queuedata;
struct nvme_queue *nvmeq = hctx->driver_data;
struct nvme_dev *dev = nvmeq->dev;
struct request *req = bd->rq;
struct nvme_command cmnd;
int ret = BLK_MQ_RQ_QUEUE_OK;
/*
* If formated with metadata, require the block layer provide a buffer
* unless this namespace is formated such that the metadata can be
* stripped/generated by the controller with PRACT=1.
*/
if (ns && ns->ms && !blk_integrity_rq(req)) {
if (!(ns->pi_type && ns->ms == 8) &&
req->cmd_type != REQ_TYPE_DRV_PRIV) {
blk_mq_end_request(req, -EFAULT);
return BLK_MQ_RQ_QUEUE_OK;
}
}
ret = nvme_init_iod(req, dev);
if (ret)
return ret;
if (req->cmd_flags & REQ_DISCARD) {
ret = nvme_setup_discard(nvmeq, ns, req, &cmnd);
} else {
if (req->cmd_type == REQ_TYPE_DRV_PRIV)
memcpy(&cmnd, req->cmd, sizeof(cmnd));
else if (req->cmd_flags & REQ_FLUSH)
nvme_setup_flush(ns, &cmnd);
else
nvme_setup_rw(ns, req, &cmnd);
if (req->nr_phys_segments)
ret = nvme_map_data(dev, req, &cmnd);
}
if (ret)
goto out;
cmnd.common.command_id = req->tag;
blk_mq_start_request(req);
spin_lock_irq(&nvmeq->q_lock);
if (unlikely(nvmeq->cq_vector < 0)) {
if (ns && !test_bit(NVME_NS_DEAD, &ns->flags))
ret = BLK_MQ_RQ_QUEUE_BUSY;
else
ret = BLK_MQ_RQ_QUEUE_ERROR;
spin_unlock_irq(&nvmeq->q_lock);
goto out;
}
__nvme_submit_cmd(nvmeq, &cmnd);
nvme_process_cq(nvmeq);
spin_unlock_irq(&nvmeq->q_lock);
return BLK_MQ_RQ_QUEUE_OK;
out:
nvme_free_iod(dev, req);
return ret;
}nvme_queue_rq流程分析:
调用nvme_init_iod
调用nvme_map_data
调用blk_mq_start_request
调用__nvme_submit_cmd
调用nvme_process_cq
static int nvme_init_iod(struct request *rq, struct nvme_dev *dev)
{
struct nvme_iod *iod = blk_mq_rq_to_pdu(rq);
int nseg = rq->nr_phys_segments;
unsigned size;
if (rq->cmd_flags & REQ_DISCARD)
size = sizeof(struct nvme_dsm_range);
else
size = blk_rq_bytes(rq);
if (nseg > NVME_INT_PAGES || size > NVME_INT_BYTES(dev)) {
iod->sg = kmalloc(nvme_iod_alloc_size(dev, size, nseg), GFP_ATOMIC);
if (!iod->sg)
return BLK_MQ_RQ_QUEUE_BUSY;
} else {
iod->sg = iod->inline_sg;
}
iod->aborted = 0;
iod->npages = -1;
iod->nents = 0;
iod->length = size;
return 0;
}看一下nvme_init_iod,第一句blk_mq_rq_to_pdu就非常让人不解。
/*
* Driver command data is immediately after the request. So subtract request
* size to get back to the original request, add request size to get the PDU.
*/
static inline struct request *blk_mq_rq_from_pdu(void *pdu)
{
return pdu - sizeof(struct request);
}
static inline void *blk_mq_rq_to_pdu(struct request *rq)
{
return rq + 1;
}读一下注释,再结合nvme_alloc_admin_tags里的dev->admin_tagset.cmd_size = nvme_cmd_size(dev);可知,分配空间的时候,每个request都是配备有额外的空间的,大小就是通过cmd_size来指定的。所以在request之后紧跟着的就是额外的空间。这里可以看到,额外的空间还不只是nvme_iod的大小。
| 区域1 | 区域2 | 区域3 |
|---|---|---|
| sizeof(struct nvme_iod) | sizeof(struct scatterlist) * nseg | sizeof(__le64 * ) * nvme_npages(size, dev) |
static int nvme_npages(unsigned size, struct nvme_dev *dev)
{
unsigned nprps = DIV_ROUND_UP(size + dev->ctrl.page_size,
dev->ctrl.page_size);
return DIV_ROUND_UP(8 * nprps, PAGE_SIZE - 8);
}
static unsigned int nvme_iod_alloc_size(struct nvme_dev *dev,
unsigned int size, unsigned int nseg)
{
return sizeof(__le64 *) * nvme_npages(size, dev) +
sizeof(struct scatterlist) * nseg;
}
static unsigned int nvme_cmd_size(struct nvme_dev *dev)
{
return sizeof(struct nvme_iod) +
nvme_iod_alloc_size(dev, NVME_INT_BYTES(dev), NVME_INT_PAGES);
}由于前面设置了req->cmd_flags为REQ_TYPE_DRV_PRIV,所以command直接通过memcpy来拷贝。然后根据:
/* * Max size of iod being embedded in the request payload */ #define NVME_INT_PAGES 2 #define NVME_INT_BYTES(dev) (NVME_INT_PAGES * (dev)->ctrl.page_size)
假如这个request需要传输的数据的段数目大于2,或者总长度大于2个nvme page的话,就为iod->sg另行分配空间,要不然就直接指向struct nvme_iod(区域1)的尾部,也就是struct scatterlist * nseg(区域2)的前端。
回到nvme_queue_rq,假如req->nr_phys_segments不为0,nvme_map_data会被调用。
static int nvme_map_data(struct nvme_dev *dev, struct request *req,
struct nvme_command *cmnd)
{
struct nvme_iod *iod = blk_mq_rq_to_pdu(req);
struct request_queue *q = req->q;
enum dma_data_direction dma_dir = rq_data_dir(req) ?
DMA_TO_DEVICE : DMA_FROM_DEVICE;
int ret = BLK_MQ_RQ_QUEUE_ERROR;
sg_init_table(iod->sg, req->nr_phys_segments);
iod->nents = blk_rq_map_sg(q, req, iod->sg);
if (!iod->nents)
goto out;
ret = BLK_MQ_RQ_QUEUE_BUSY;
if (!dma_map_sg(dev->dev, iod->sg, iod->nents, dma_dir))
goto out;
if (!nvme_setup_prps(dev, req, blk_rq_bytes(req)))
goto out_unmap;
ret = BLK_MQ_RQ_QUEUE_ERROR;
if (blk_integrity_rq(req)) {
if (blk_rq_count_integrity_sg(q, req->bio) != 1)
goto out_unmap;
sg_init_table(&iod->meta_sg, 1);
if (blk_rq_map_integrity_sg(q, req->bio, &iod->meta_sg) != 1)
goto out_unmap;
if (rq_data_dir(req))
nvme_dif_remap(req, nvme_dif_prep);
if (!dma_map_sg(dev->dev, &iod->meta_sg, 1, dma_dir))
goto out_unmap;
}
/* 把配置好的prp entry写入两个prp寄存器,详解请看nvme_setup_prps */
cmnd->rw.prp1 = cpu_to_le64(sg_dma_address(iod->sg));
cmnd->rw.prp2 = cpu_to_le64(iod->first_dma);
if (blk_integrity_rq(req))
cmnd->rw.metadata = cpu_to_le64(sg_dma_address(&iod->meta_sg));
return BLK_MQ_RQ_QUEUE_OK;
out_unmap:
dma_unmap_sg(dev->dev, iod->sg, iod->nents, dma_dir);
out:
return ret;
}nvme_map_data流程分析:
调用sg_init_table,初始化的就是区域2中存放的scatterlist。
调用blk_rq_map_sg
调用dma_map_sg
调用nvme_setup_prps,一个没有一行注释的长函数~其实这个函数分成3个部分,对应设置prp的三种不同情况。第一种情况是一个prp entry就能描述所有的传输,第二种情况是需要两个prp entry才能描述所有的传输,第三种情况是需要prp list才能描述所有的传输。我会在代码中加入注释来说明。
static bool nvme_setup_prps(struct nvme_dev *dev, struct request *req,
int total_len)
{
struct nvme_iod *iod = blk_mq_rq_to_pdu(req);
struct dma_pool *pool;
int length = total_len; /* length就是全部prp需要传输的字节长度 */
struct scatterlist *sg = iod->sg;
int dma_len = sg_dma_len(sg); /* 第一个sg描述的数据长度 */
u64 dma_addr = sg_dma_address(sg); /* 第一个sg描述的数据物理地址 */
u32 page_size = dev->ctrl.page_size; /* nvme的页尺寸 */
int offset = dma_addr & (page_size - 1); /* 第一个sg描述的数据物理地址在nvme页当中的偏移 */
__le64 *prp_list;
__le64 **list = iod_list(req);
dma_addr_t prp_dma;
int nprps, i;
/* 一个prp entry就能描述所有的传输 */
length -= (page_size - offset);
if (length <= 0)
return true;
dma_len -= (page_size - offset);
if (dma_len) {
dma_addr += (page_size - offset);
} else {
/* dma_len为0,也就是第一个sg描述的数据全部在一个nvme页中,
可以用一个prp来表示,所以跳到下一个sg进行处理。
sg = sg_next(sg);
dma_addr = sg_dma_address(sg);
dma_len = sg_dma_len(sg);
}
/* 两个prp entry才能描述所有的传输 */
if (length <= page_size) {
iod->first_dma = dma_addr;
return true;
}
/* 这里开始就是prp list的处理了,一个prp entry 8个字节,所以根据需要使用的prp entry的个数来决定使用哪个dma pool更好 */
nprps = DIV_ROUND_UP(length, page_size);
if (nprps <= (256 / 8)) {
pool = dev->prp_small_pool;
iod->npages = 0;
} else {
pool = dev->prp_page_pool;
iod->npages = 1;
}
prp_list = dma_pool_alloc(pool, GFP_ATOMIC, &prp_dma);
if (!prp_list) {
iod->first_dma = dma_addr;
iod->npages = -1;
return false;
}
list[0] = prp_list;
iod->first_dma = prp_dma;
i = 0;
for (;;) {
/* 一个dma memory用完了,需要从pool里再申请一个来存放其他的prp entry */
if (i == page_size >> 3) {
__le64 *old_prp_list = prp_list;
prp_list = dma_pool_alloc(pool, GFP_ATOMIC, &prp_dma);
if (!prp_list)
return false;
list[iod->npages++] = prp_list;
prp_list[0] = old_prp_list[i - 1];
old_prp_list[i - 1] = cpu_to_le64(prp_dma);
i = 1;
}
/* 存放prp list中的entry */
prp_list[i++] = cpu_to_le64(dma_addr);
dma_len -= page_size;
dma_addr += page_size;
length -= page_size;
if (length <= 0)
break;
if (dma_len > 0)
continue;
BUG_ON(dma_len < 0);
sg = sg_next(sg);
dma_addr = sg_dma_address(sg);
dma_len = sg_dma_len(sg);
}
return true;
}回到nvme_queue_rq,调用__nvme_submit_cmd。这个函数很简单,单很重要,就是把命令复制到submission queue中,然后把最后一个命令的索引写入doorbell的寄存器通知设备去处理。
static void __nvme_submit_cmd(struct nvme_queue *nvmeq,
struct nvme_command *cmd)
{
u16 tail = nvmeq->sq_tail;
if (nvmeq->sq_cmds_io)
memcpy_toio(&nvmeq->sq_cmds_io[tail], cmd, sizeof(*cmd));
else
memcpy(&nvmeq->sq_cmds[tail], cmd, sizeof(*cmd));
if (++tail == nvmeq->q_depth)
tail = 0;
writel(tail, nvmeq->q_db);
nvmeq->sq_tail = tail;
}来看nvme_queue_rq里最后一个调用的函数__nvme_process_cq,从名字上就很容易知道是用来处理completion queue的。
static void __nvme_process_cq(struct nvme_queue *nvmeq, unsigned int *tag)
{
u16 head, phase;
head = nvmeq->cq_head;
phase = nvmeq->cq_phase;
for (;;) {
struct nvme_completion cqe = nvmeq->cqes[head];
u16 status = le16_to_cpu(cqe.status);
struct request *req;
if ((status & 1) != phase)
break;
nvmeq->sq_head = le16_to_cpu(cqe.sq_head);
if (++head == nvmeq->q_depth) {
head = 0;
phase = !phase;
}
if (tag && *tag == cqe.command_id)
*tag = -1;
if (unlikely(cqe.command_id >= nvmeq->q_depth)) {
dev_warn(nvmeq->q_dmadev,
"invalid id %d completed on queue %d\n",
cqe.command_id, le16_to_cpu(cqe.sq_id));
continue;
}
/*
* AEN requests are special as they don't time out and can
* survive any kind of queue freeze and often don't respond to
* aborts. We don't even bother to allocate a struct request
* for them but rather special case them here.
*/
if (unlikely(nvmeq->qid == 0 &&
cqe.command_id >= NVME_AQ_BLKMQ_DEPTH)) {
nvme_complete_async_event(nvmeq->dev, &cqe);
continue;
}
req = blk_mq_tag_to_rq(*nvmeq->tags, cqe.command_id);
if (req->cmd_type == REQ_TYPE_DRV_PRIV) {
u32 result = le32_to_cpu(cqe.result);
req->special = (void *)(uintptr_t)result;
}
blk_mq_complete_request(req, status >> 1);
}
/* If the controller ignores the cq head doorbell and continuously
* writes to the queue, it is theoretically possible to wrap around
* the queue twice and mistakenly return IRQ_NONE. Linux only
* requires that 0.1% of your interrupts are handled, so this isn't
* a big problem.
*/
if (head == nvmeq->cq_head && phase == nvmeq->cq_phase)
return;
if (likely(nvmeq->cq_vector >= 0))
writel(head, nvmeq->q_db + nvmeq->dev->db_stride);
nvmeq->cq_head = head;
nvmeq->cq_phase = phase;
nvmeq->cqe_seen = 1;
}先看一下nvme协议里规定的completion entry的格式,每个16字节。
我们知道,不管是admin queue还是io queue,都有若干个submission queue和一个completion queue。而不管是submission queue还是completion queue,都是通过head和tail变量来管理的。主机端负责更新submission queue的tail来表示新任务的添加。设备端从submission queue里拿出任务处理,并修改head值。但是这个head怎么通知给主机那?答案就在completion entry的SQ Head Pointer中。对于completion queue,是反过来的,设备负责往里面添加元素,然后修改tail值。这个tail值是怎么传递给主机的那?这里就用到了另外一个机制,就是在Status Field中的PP标志位。
P标志位全称是Phase Tag,在completion queue刚建立的时候,全部初始化成0。当设备第一遍往completion queue里添加元素的时候,就把对应的entry的Phase Tag设置成1。这样,主机端通过Phase Tag的值就能够知道有多少个新的元素被添加到了completion queue中。当设备添加元素到了队列的底部,就要重新回到索引0处,这也就是completion queue的第二遍更新,这次设备又会把Phase Tag全部设置成0。就这样,一遍1一遍0再一遍1再一遍0…最后,主机处理好completion之后,更新completion queue的head值,并通过doorbell告诉设备。
__nvme_process_cq的主要机制分析了,但是为什么要在nvme_queue_rq的最后调用__nvme_process_cq,有点疑惑。因为即使不显示调用__nvme_process_cq,设备在处理完submission之后,也会发送中断(INT/MSI)给主机,在主机的中断处理函数中,也会进行__nvme_process_cq的调用。
static irqreturn_t nvme_irq(int irq, void *data)
{
irqreturn_t result;
struct nvme_queue *nvmeq = data;
spin_lock(&nvmeq->q_lock);
nvme_process_cq(nvmeq);
result = nvmeq->cqe_seen ? IRQ_HANDLED : IRQ_NONE;
nvmeq->cqe_seen = 0;
spin_unlock(&nvmeq->q_lock);
return result;
}在__nvme_process_cq中,对于处理好了的request,会调用blk_mq_complete_request。这会触发我们之前注册的nvme_complete_rq被调用。
static void nvme_complete_rq(struct request *req)
{
struct nvme_iod *iod = blk_mq_rq_to_pdu(req);
struct nvme_dev *dev = iod->nvmeq->dev;
int error = 0;
nvme_unmap_data(dev, req);
if (unlikely(req->errors)) {
if (nvme_req_needs_retry(req, req->errors)) {
nvme_requeue_req(req);
return;
}
if (req->cmd_type == REQ_TYPE_DRV_PRIV)
error = req->errors;
else
error = nvme_error_status(req->errors);
}
if (unlikely(iod->aborted)) {
dev_warn(dev->dev,
"completing aborted command with status: %04x\n",
req->errors);
}
blk_mq_end_request(req, error);
}分析了那么一大串,nvme_identify_ctrl终于讲完了。往上到nvme_init_identify,也已经基本没什么事情要做了。再往上回到nvme_reset_work,看看nvme_init_identify之后的nvme_setup_io_queues做了些什么。
static int nvme_setup_io_queues(struct nvme_dev *dev)
{
struct nvme_queue *adminq = dev->queues[0];
struct pci_dev *pdev = to_pci_dev(dev->dev);
int result, i, vecs, nr_io_queues, size;
nr_io_queues = num_possible_cpus();
result = nvme_set_queue_count(&dev->ctrl, &nr_io_queues);
if (result < 0)
return result;
/*
* Degraded controllers might return an error when setting the queue
* count. We still want to be able to bring them online and offer
* access to the admin queue, as that might be only way to fix them up.
*/
if (result > 0) {
dev_err(dev->dev, "Could not set queue count (%d)\n", result);
nr_io_queues = 0;
result = 0;
}
if (dev->cmb && NVME_CMB_SQS(dev->cmbsz)) {
result = nvme_cmb_qdepth(dev, nr_io_queues,
sizeof(struct nvme_command));
if (result > 0)
dev->q_depth = result;
else
nvme_release_cmb(dev);
}
size = db_bar_size(dev, nr_io_queues);
if (size > 8192) {
iounmap(dev->bar);
do {
dev->bar = ioremap(pci_resource_start(pdev, 0), size);
if (dev->bar)
break;
if (!--nr_io_queues)
return -ENOMEM;
size = db_bar_size(dev, nr_io_queues);
} while (1);
dev->dbs = dev->bar + 4096;
adminq->q_db = dev->dbs;
}
/* Deregister the admin queue's interrupt */
free_irq(dev->entry[0].vector, adminq);
/*
* If we enable msix early due to not intx, disable it again before
* setting up the full range we need.
*/
if (!pdev->irq)
pci_disable_msix(pdev);
for (i = 0; i < nr_io_queues; i++)
dev->entry[i].entry = i;
vecs = pci_enable_msix_range(pdev, dev->entry, 1, nr_io_queues);
if (vecs < 0) {
vecs = pci_enable_msi_range(pdev, 1, min(nr_io_queues, 32));
if (vecs < 0) {
vecs = 1;
} else {
for (i = 0; i < vecs; i++)
dev->entry[i].vector = i + pdev->irq;
}
}
/*
* Should investigate if there's a performance win from allocating
* more queues than interrupt vectors; it might allow the submission
* path to scale better, even if the receive path is limited by the
* number of interrupts.
*/
nr_io_queues = vecs;
dev->max_qid = nr_io_queues;
result = queue_request_irq(dev, adminq, adminq->irqname);
if (result) {
adminq->cq_vector = -1;
goto free_queues;
}
/* Free previously allocated queues that are no longer usable */
nvme_free_queues(dev, nr_io_queues + 1);
return nvme_create_io_queues(dev);
free_queues:
nvme_free_queues(dev, 1);
return result;
}nvme_setup_io_queues流程分析:
调用nvme_set_queue_count
调用nvme_create_io_queues
nvme_set_queue_count发送了一个set features的命令,feature id为0x7,设置io queue的数量。
int nvme_set_queue_count(struct nvme_ctrl *ctrl, int *count)
{
u32 q_count = (*count - 1) | ((*count - 1) << 16);
u32 result;
int status, nr_io_queues;
status = nvme_set_features(ctrl, NVME_FEAT_NUM_QUEUES, q_count, 0,
&result);
if (status)
return status;
nr_io_queues = min(result & 0xffff, result >> 16) + 1;
*count = min(*count, nr_io_queues);
return 0;
}queue的大小存放在set features命令的dword 11中。
int nvme_set_features(struct nvme_ctrl *dev, unsigned fid, unsigned dword11,
dma_addr_t dma_addr, u32 *result)
{
struct nvme_command c;
memset(&c, 0, sizeof(c));
c.features.opcode = nvme_admin_set_features;
c.features.prp1 = cpu_to_le64(dma_addr);
c.features.fid = cpu_to_le32(fid);
c.features.dword11 = cpu_to_le32(dword11);
return __nvme_submit_sync_cmd(dev->admin_q, &c, NULL, 0, result, 0);
}回到nvme_setup_io_queues,分析nvme_create_io_queues。
static int nvme_create_io_queues(struct nvme_dev *dev)
{
unsigned i;
int ret = 0;
for (i = dev->queue_count; i <= dev->max_qid; i++) {
if (!nvme_alloc_queue(dev, i, dev->q_depth)) {
ret = -ENOMEM;
break;
}
}
for (i = dev->online_queues; i <= dev->queue_count - 1; i++) {
ret = nvme_create_queue(dev->queues[i], i);
if (ret) {
nvme_free_queues(dev, i);
break;
}
}
/*
* Ignore failing Create SQ/CQ commands, we can continue with less
* than the desired aount of queues, and even a controller without
* I/O queues an still be used to issue admin commands. This might
* be useful to upgrade a buggy firmware for example.
*/
return ret >= 0 ? 0 : ret;
}nvme_alloc_queue在之前分析过就不再累赘了,主要看下nvme_create_queue。
static int nvme_create_queue(struct nvme_queue *nvmeq, int qid)
{
struct nvme_dev *dev = nvmeq->dev;
int result;
nvmeq->cq_vector = qid - 1;
result = adapter_alloc_cq(dev, qid, nvmeq);
if (result < 0)
return result;
result = adapter_alloc_sq(dev, qid, nvmeq);
if (result < 0)
goto release_cq;
result = queue_request_irq(dev, nvmeq, nvmeq->irqname);
if (result < 0)
goto release_sq;
nvme_init_queue(nvmeq, qid);
return result;
release_sq:
adapter_delete_sq(dev, qid);
release_cq:
adapter_delete_cq(dev, qid);
return result;
}adapter_alloc_cq发送opcode为0x5的create io completion queue命令。
static int adapter_alloc_cq(struct nvme_dev *dev, u16 qid,
struct nvme_queue *nvmeq)
{
struct nvme_command c;
int flags = NVME_QUEUE_PHYS_CONTIG | NVME_CQ_IRQ_ENABLED;
/*
* Note: we (ab)use the fact the the prp fields survive if no data
* is attached to the request.
*/
memset(&c, 0, sizeof(c));
c.create_cq.opcode = nvme_admin_create_cq;
c.create_cq.prp1 = cpu_to_le64(nvmeq->cq_dma_addr);
c.create_cq.cqid = cpu_to_le16(qid);
c.create_cq.qsize = cpu_to_le16(nvmeq->q_depth - 1);
c.create_cq.cq_flags = cpu_to_le16(flags);
c.create_cq.irq_vector = cpu_to_le16(nvmeq->cq_vector);
return nvme_submit_sync_cmd(dev->ctrl.admin_q, &c, NULL, 0);
}adapter_alloc_sq发送opcode为0x1的create io submission queue命令。
static int adapter_alloc_sq(struct nvme_dev *dev, u16 qid,
struct nvme_queue *nvmeq)
{
struct nvme_command c;
int flags = NVME_QUEUE_PHYS_CONTIG | NVME_SQ_PRIO_MEDIUM;
/*
* Note: we (ab)use the fact the the prp fields survive if no data
* is attached to the request.
*/
memset(&c, 0, sizeof(c));
c.create_sq.opcode = nvme_admin_create_sq;
c.create_sq.prp1 = cpu_to_le64(nvmeq->sq_dma_addr);
c.create_sq.sqid = cpu_to_le16(qid);
c.create_sq.qsize = cpu_to_le16(nvmeq->q_depth - 1);
c.create_sq.sq_flags = cpu_to_le16(flags);
c.create_sq.cqid = cpu_to_le16(qid);
return nvme_submit_sync_cmd(dev->ctrl.admin_q, &c, NULL, 0);
}最后注册中断,就是之前我们列出来过的nvme0q1。
再次回到nvme_reset_work,分析nvme_dev_list_add。这个函数主要做的是启动了一个内核线程nvme_kthread,这个函数我们后面再分析。
static int nvme_dev_list_add(struct nvme_dev *dev)
{
bool start_thread = false;
spin_lock(&dev_list_lock);
if (list_empty(&dev_list) && IS_ERR_OR_NULL(nvme_thread)) {
start_thread = true;
nvme_thread = NULL;
}
list_add(&dev->node, &dev_list);
spin_unlock(&dev_list_lock);
if (start_thread) {
nvme_thread = kthread_run(nvme_kthread, NULL, "nvme");
wake_up_all(&nvme_kthread_wait);
} else
wait_event_killable(nvme_kthread_wait, nvme_thread);
if (IS_ERR_OR_NULL(nvme_thread))
return nvme_thread ? PTR_ERR(nvme_thread) : -EINTR;
return 0;
}继续回到nvme_reset_work,分析nvme_start_queues。
void nvme_start_queues(struct nvme_ctrl *ctrl)
{
struct nvme_ns *ns;
mutex_lock(&ctrl->namespaces_mutex);
list_for_each_entry(ns, &ctrl->namespaces, list) {
queue_flag_clear_unlocked(QUEUE_FLAG_STOPPED, ns->queue);
blk_mq_start_stopped_hw_queues(ns->queue, true);
blk_mq_kick_requeue_list(ns->queue);
}
mutex_unlock(&ctrl->namespaces_mutex);
}继续回到nvme_reset_work,分析最后一个函数nvme_dev_add。blk_mq_alloc_tag_set在之前调用过一次,是为admin queue分配tag set。这次则是为了io queue分配tag set。
static int nvme_dev_add(struct nvme_dev *dev)
{
if (!dev->ctrl.tagset) {
dev->tagset.ops = &nvme_mq_ops;
dev->tagset.nr_hw_queues = dev->online_queues - 1;
dev->tagset.timeout = NVME_IO_TIMEOUT;
dev->tagset.numa_node = dev_to_node(dev->dev);
dev->tagset.queue_depth =
min_t(int, dev->q_depth, BLK_MQ_MAX_DEPTH) - 1;
dev->tagset.cmd_size = nvme_cmd_size(dev);
dev->tagset.flags = BLK_MQ_F_SHOULD_MERGE;
dev->tagset.driver_data = dev;
if (blk_mq_alloc_tag_set(&dev->tagset))
return 0;
dev->ctrl.tagset = &dev->tagset;
}
nvme_queue_scan(dev);
return 0;
}最后,调用nvme_queue_scan调度了另一个work,也就是函数nvme_dev_scan。
static void nvme_queue_scan(struct nvme_dev *dev)
{
/*
* Do not queue new scan work when a controller is reset during
* removal.
*/
if (test_bit(NVME_CTRL_REMOVING, &dev->flags))
return;
queue_work(nvme_workq, &dev->scan_work);
}至此,nvme_reset_work完全结束。让我们进入到下一个work里,去征服另一个山头吧!
nvme_dev_scan — 又一个冗长的work
static void nvme_dev_scan(struct work_struct *work)
{
struct nvme_dev *dev = container_of(work, struct nvme_dev, scan_work);
if (!dev->tagset.tags)
return;
nvme_scan_namespaces(&dev->ctrl);
nvme_set_irq_hints(dev);
}调用nvme_scan_namespaces。
void nvme_scan_namespaces(struct nvme_ctrl *ctrl)
{
struct nvme_id_ctrl *id;
unsigned nn;
if (nvme_identify_ctrl(ctrl, &id))
return;
mutex_lock(&ctrl->namespaces_mutex);
nn = le32_to_cpu(id->nn);
if (ctrl->vs >= NVME_VS(1, 1) &&
!(ctrl->quirks & NVME_QUIRK_IDENTIFY_CNS)) {
if (!nvme_scan_ns_list(ctrl, nn))
goto done;
}
__nvme_scan_namespaces(ctrl, le32_to_cpup(&id->nn));
done:
list_sort(NULL, &ctrl->namespaces, ns_cmp);
mutex_unlock(&ctrl->namespaces_mutex);
kfree(id);
}先调用nvme_identify_ctrl给设备发一个identify命令,然后把取得的namespace number传给__nvme_scan_namespaces。
static void __nvme_scan_namespaces(struct nvme_ctrl *ctrl, unsigned nn)
{
struct nvme_ns *ns, *next;
unsigned i;
lockdep_assert_held(&ctrl->namespaces_mutex);
for (i = 1; i <= nn; i++)
nvme_validate_ns(ctrl, i);
list_for_each_entry_safe(ns, next, &ctrl->namespaces, list) {
if (ns->ns_id > nn)
nvme_ns_remove(ns);
}
}为每个namespace调用一次nvme_validate_ns。nvme协议规定,namespace号0表示不使用namespace功能,0xFFFFFFFF表示匹配任何namespace号。所以正常的namespace号是从1开始的。
static void nvme_validate_ns(struct nvme_ctrl *ctrl, unsigned nsid)
{
struct nvme_ns *ns;
ns = nvme_find_ns(ctrl, nsid);
if (ns) {
if (revalidate_disk(ns->disk))
nvme_ns_remove(ns);
} else
nvme_alloc_ns(ctrl, nsid);
}先查找某个namespace是否已经存在,初始化的时候,namespace都还没有创建,所以返回的肯定是空。
static struct nvme_ns *nvme_find_ns(struct nvme_ctrl *ctrl, unsigned nsid)
{
struct nvme_ns *ns;
lockdep_assert_held(&ctrl->namespaces_mutex);
list_for_each_entry(ns, &ctrl->namespaces, list) {
if (ns->ns_id == nsid)
return ns;
if (ns->ns_id > nsid)
break;
}
return NULL;
}既然找不到相应的namespace,那就要创建它。
static void nvme_alloc_ns(struct nvme_ctrl *ctrl, unsigned nsid)
{
struct nvme_ns *ns;
struct gendisk *disk;
int node = dev_to_node(ctrl->dev);
lockdep_assert_held(&ctrl->namespaces_mutex);
/* 为nvme_ns结构体分配空间 */
ns = kzalloc_node(sizeof(*ns), GFP_KERNEL, node);
if (!ns)
return;
/* 为ns分配索引号,ida机制之前有讲过 */
ns->instance = ida_simple_get(&ctrl->ns_ida, 1, 0, GFP_KERNEL);
if (ns->instance < 0)
goto out_free_ns;
/* 创建一个request queue */
ns->queue = blk_mq_init_queue(ctrl->tagset);
if (IS_ERR(ns->queue))
goto out_release_instance;
queue_flag_set_unlocked(QUEUE_FLAG_NONROT, ns->queue);
ns->queue->queuedata = ns;
ns->ctrl = ctrl;
/* 创建一个gendisk */
disk = alloc_disk_node(0, node);
if (!disk)
goto out_free_queue;
kref_init(&ns->kref);
ns->ns_id = nsid;
ns->disk = disk;
ns->lba_shift = 9; /* set to a default value for 512 until disk is validated */
blk_queue_logical_block_size(ns->queue, 1 << ns->lba_shift);
nvme_set_queue_limits(ctrl, ns->queue);
/* 为gendisk做初始化 */
disk->major = nvme_major;
disk->first_minor = 0;
disk->fops = &nvme_fops;
disk->private_data = ns;
disk->queue = ns->queue;
disk->driverfs_dev = ctrl->device;
disk->flags = GENHD_FL_EXT_DEVT;
/* /dev下的nvme0n1 */
sprintf(disk->disk_name, "nvme%dn%d", ctrl->instance, ns->instance);
if (nvme_revalidate_disk(ns->disk))
goto out_free_disk;
/* 把这个新建的namespace加入到ctrl->namespaces链表里去 */
list_add_tail(&ns->list, &ctrl->namespaces);
kref_get(&ctrl->kref);
if (ns->type == NVME_NS_LIGHTNVM)
return;
/* alloc_disk_node只是创建一个disk,而add_disk才是真正把它加入系统,可以进行操作。
这里创建的就是/dev/nvme0n1,可是为什么主设备号是259那?在add_disk里面调用了一个函数blk_alloc_devt,
在这个函数里,会有一段逻辑来判断是用我们自己设置的主设备号来注册设备,还是用BLOCK_EXT_MAJOR来注册。
但是究竟为什么要这样做,我还没有搞明白,希望有谁知道的不吝赐教。 */
add_disk(ns->disk);
if (sysfs_create_group(&disk_to_dev(ns->disk)->kobj,
&nvme_ns_attr_group))
pr_warn("%s: failed to create sysfs group for identification\n",
ns->disk->disk_name);
return;
out_free_disk:
kfree(disk);
out_free_queue:
blk_cleanup_queue(ns->queue);
out_release_instance:
ida_simple_remove(&ctrl->ns_ida, ns->instance);
out_free_ns:
kfree(ns);
}nvme_alloc_ns中有个重要函数nvme_revalidate_disk需要跟进去。
static int nvme_revalidate_disk(struct gendisk *disk)
{
struct nvme_ns *ns = disk->private_data;
struct nvme_id_ns *id;
u8 lbaf, pi_type;
u16 old_ms;
unsigned short bs;
if (test_bit(NVME_NS_DEAD, &ns->flags)) {
set_capacity(disk, 0);
return -ENODEV;
}
if (nvme_identify_ns(ns->ctrl, ns->ns_id, &id)) {
dev_warn(ns->ctrl->dev, "%s: Identify failure nvme%dn%d\n",
__func__, ns->ctrl->instance, ns->ns_id);
return -ENODEV;
}
if (id->ncap == 0) {
kfree(id);
return -ENODEV;
}
if (nvme_nvm_ns_supported(ns, id) && ns->type != NVME_NS_LIGHTNVM) {
if (nvme_nvm_register(ns->queue, disk->disk_name)) {
dev_warn(ns->ctrl->dev,
"%s: LightNVM init failure\n", __func__);
kfree(id);
return -ENODEV;
}
ns->type = NVME_NS_LIGHTNVM;
}
if (ns->ctrl->vs >= NVME_VS(1, 1))
memcpy(ns->eui, id->eui64, sizeof(ns->eui));
if (ns->ctrl->vs >= NVME_VS(1, 2))
memcpy(ns->uuid, id->nguid, sizeof(ns->uuid));
old_ms = ns->ms;
lbaf = id->flbas & NVME_NS_FLBAS_LBA_MASK;
ns->lba_shift = id->lbaf[lbaf].ds;
ns->ms = le16_to_cpu(id->lbaf[lbaf].ms);
ns->ext = ns->ms && (id->flbas & NVME_NS_FLBAS_META_EXT);
/*
* If identify namespace failed, use default 512 byte block size so
* block layer can use before failing read/write for 0 capacity.
*/
if (ns->lba_shift == 0)
ns->lba_shift = 9;
bs = 1 << ns->lba_shift;
/* XXX: PI implementation requires metadata equal t10 pi tuple size */
pi_type = ns->ms == sizeof(struct t10_pi_tuple) ?
id->dps & NVME_NS_DPS_PI_MASK : 0;
blk_mq_freeze_queue(disk->queue);
if (blk_get_integrity(disk) && (ns->pi_type != pi_type ||
ns->ms != old_ms ||
bs != queue_logical_block_size(disk->queue) ||
(ns->ms && ns->ext)))
blk_integrity_unregister(disk);
ns->pi_type = pi_type;
blk_queue_logical_block_size(ns->queue, bs);
if (ns->ms && !blk_get_integrity(disk) && !ns->ext)
nvme_init_integrity(ns);
if (ns->ms && !(ns->ms == 8 && ns->pi_type) && !blk_get_integrity(disk))
set_capacity(disk, 0);
else
/* id->nsze是Namespace Size,即这个namespace所包含的所有LBA的总数,调试发现是2097152。
而ns->lba_shift为9,表示一个扇区512个字节。
所以2097152*512=1GB,也就是我们刚开始使用qemu-img命令生成的磁盘镜像的大小。 */
set_capacity(disk, le64_to_cpup(&id->nsze) << (ns->lba_shift - 9));
if (ns->ctrl->oncs & NVME_CTRL_ONCS_DSM)
nvme_config_discard(ns);
blk_mq_unfreeze_queue(disk->queue);
kfree(id);
return 0;
}回到nvme_alloc_ns,执行完add_disk之后,注册在disk->fops中的nvme_open和nvme_revalidate_disk会被调用。
static const struct block_device_operations nvme_fops = {
.owner = THIS_MODULE,
.ioctl = nvme_ioctl,
.compat_ioctl = nvme_compat_ioctl,
.open = nvme_open,
.release = nvme_release,
.getgeo = nvme_getgeo,
.revalidate_disk= nvme_revalidate_disk,
.pr_ops = &nvme_pr_ops,
};static int nvme_open(struct block_device *bdev, fmode_t mode)
{
return nvme_get_ns_from_disk(bdev->bd_disk) ? 0 : -ENXIO;
}
static struct nvme_ns *nvme_get_ns_from_disk(struct gendisk *disk)
{
struct nvme_ns *ns;
spin_lock(&dev_list_lock);
ns = disk->private_data;
if (ns && !kref_get_unless_zero(&ns->kref))
ns = NULL;
spin_unlock(&dev_list_lock);
return ns;
}回到nvme_dev_scan,调用nvme_set_irq_hints。主要做一些中断亲和性的优化工作。
static void nvme_set_irq_hints(struct nvme_dev *dev)
{
struct nvme_queue *nvmeq;
int i;
for (i = 0; i < dev->online_queues; i++) {
nvmeq = dev->queues[i];
if (!nvmeq->tags || !(*nvmeq->tags))
continue;
irq_set_affinity_hint(dev->entry[nvmeq->cq_vector].vector,
blk_mq_tags_cpumask(*nvmeq->tags));
}
}至此,nvme_dev_scan也结束了,整个nvme驱动的初始化也基本完成了。初始化完成之后,留给我们的就是/dev下的nvme0和nvme0n1两个供应用层操作的接口,以及一个默默无闻在那里1秒轮询一次的内核线程nvme_kthread。这个线程做的事情很有限,检测是否需要重启,是否有没有处理的completion消息。但是我没有明白,像处理CQ这种事情不都是有中断驱动的吗,为何还需要去轮询?
static int nvme_kthread(void *data)
{
struct nvme_dev *dev, *next;
while (!kthread_should_stop()) {
set_current_state(TASK_INTERRUPTIBLE);
spin_lock(&dev_list_lock);
list_for_each_entry_safe(dev, next, &dev_list, node) {
int i;
u32 csts = readl(dev->bar + NVME_REG_CSTS);
/*
* Skip controllers currently under reset.
*/
if (work_pending(&dev->reset_work) || work_busy(&dev->reset_work))
continue;
if ((dev->subsystem && (csts & NVME_CSTS_NSSRO)) ||
csts & NVME_CSTS_CFS) {
if (queue_work(nvme_workq, &dev->reset_work)) {
dev_warn(dev->dev,
"Failed status: %x, reset controller\n",
readl(dev->bar + NVME_REG_CSTS));
}
continue;
}
for (i = 0; i < dev->queue_count; i++) {
struct nvme_queue *nvmeq = dev->queues[i];
if (!nvmeq)
continue;
spin_lock_irq(&nvmeq->q_lock);
nvme_process_cq(nvmeq);
while (i == 0 && dev->ctrl.event_limit > 0)
nvme_submit_async_event(dev);
spin_unlock_irq(&nvmeq->q_lock);
}
}
spin_unlock(&dev_list_lock);
schedule_timeout(round_jiffies_relative(HZ));
}
return 0;
}由于篇幅有限,有关初始化后的读写打算放在另一篇文章里写。
当然,由于对nvme的学习还处在入门阶段,代码分析总会出现不够详细甚至是错误的地方,希望大家对于错误的地方积极指出,我好确认后改掉,谢谢。

相关文章推荐
- Linux GCC常用命令
- centos7.0下lnmp环境搭建
- linux 基础学习图解
- 在CentOs6.5安装jdk
- 浅析 Linux 文件权限
- linux常用命令之压缩打包
- linux常用命令之压缩打包
- centos7.0下lamp环境搭建
- ESXi5.5下的Centos7虚机配置静态IP
- linux vim
- 搭建linux 环境
- Linux Shell 功能指令收集
- linux中手动安装的软件的快捷方式的创建
- ARM linux kernel启动流程
- Linux配置vim ctags g++ IDE GDB
- CentOS7手动释放内存
- centos7中的f t p安装设置
- Linux中tty、pty、pts的概念区别 转载
- Linux驱动学习相关记录笔记
- Linux进程间通信--共享内存