分布式日志收集系统Flume
2016-05-31 15:48
429 查看
Flume简介
Flume是一个分布式的、高可用的海量日志采集系统。它支持对日志数据的发送方、接收方进行定义,可将多种来源的日志数据写到指定的接收方,如:文本、HDFS、Hbase等。我认为Flume最让我称赞的就是,可以在不干涉已有系统运行的情况下,无侵入地对采集到该系统的日志信息。
Flume的数据流由event(事件)贯穿始终,event是Flume的基本数据单位,它携带日志数据(字节数组形式)和头信息,这些event由Agent外部的Source生成。 当Source捕获到事先设定的事件(这里的事件,是指广义上的事件), 就会生成event并推送到单个或多个Channel中。你可以把Channel看作是一个缓冲区,它保存event直到Sink对其处理完毕。Sink负责处理event,它对日志进行持久化或把event 转给另一个Source。
Flume以agent为最小的独立运行单位,每台机器运行一个agent,一个agent由Source、Sink和Channel三大组件构成,如下图:
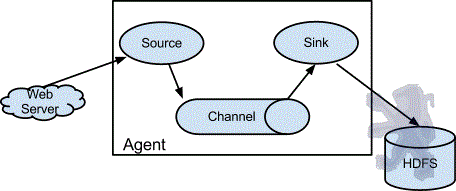
Client生产数据,运行在一个独立的线程,比如我们的应用系统。
Source从Client收集数据,传递给Channel。
Sink从Channel收集数据,运行在一个独立线程。
Channel连接 sources 和 sinks ,这个有点像一个队列。
Events可以是日志记录、 avro 对象等。
一个agent中包含多个sources和sinks:
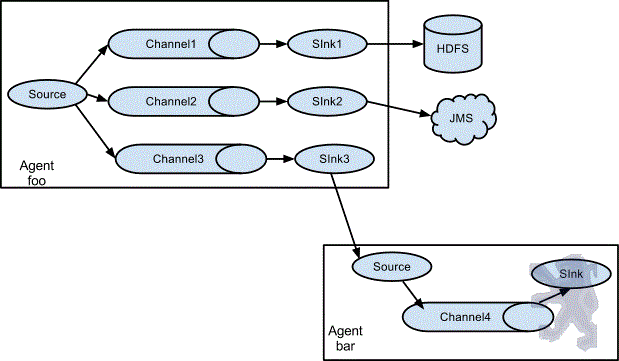
应用场景及用法
sources.type = netcatFlume可以监听到某台计算机(Client)接收到其它计算机发来的netcat、telnet消息, 然后将这些消息传送到指定的地方,如hdfs、HBase、Kafka等。详细用法,参考http://corejava2008.iteye.com/blog/2218123
sources.type = exec
Flume可以监听到某台计算机(Client)某个指令的执行,然后把指令执行产生的输出信息发送到指定的地方,如hdfs、HBase、Kafka。如设定:
sources.command = tail -F /app/xxx.log
那么每当有10条新的日志产生后,Flume就把这10条新日志传送到指定的地方,如hdfs、HBase、Kafka等。
sources.type = spooldir
Flume可以监听到某台计算机(Client)上某个目录文件的变化,当有新的日志文件产生时,Flume就把这个日志文件的内容传送到指定的地方,如hdfs、HBase、Kafka等。
sources.type = http
详细用法,参考http://my.oschina.net/pengqiang/blog/537380?p={{page}}
sources.type = syslogtcp
Flume可以监听到某台计算机(Client)TCP的端口,把从端口接收到的消息传送到指定的地方,如hdfs、HBase、Kafka等。详细用法,参考http://www.jb51.net/article/53542.htm

相关文章推荐
- 使用自定义View绘制右侧导航栏
- jQuery MiniUI - 快速开发WebUI
- JavaScript 解析 Django Python 生成的 datetime 数据 时区问题解决
- Middle-题目25:24. Swap Nodes in Pairs
- UE4 蓝图里添加Cpp文件,不在VS解决方案里显示的问题
- Middle-题目24:46. Permutations
- Android:TextView的垂直滚动效果,和上下滚动效果
- Android:TextView的垂直滚动效果,和上下滚动效果
- C# 常用分页
- web前端工程师需要掌握哪些知识
- minidlna配置
- 微信线下门店二维码扫码支付和退款
- A+B Problem (0)
- 第一篇博文
- OpenCV图像元素遍历四种方法的源码及性能对比
- Camshift算法
- Hibernate中的Entity类之间的ManyToMany关联
- JavaScript学习--Item26 异步的脚本加载
- Android-Image-Loader 图片异步加载类库的使用超(详细配置)
- spring mvc mybatis 搭建 配置文件信息