Java 八种排序算法比较实践
2016-05-31 10:54
881 查看
写这篇文章是因为面试时经常会问这个问题,但是工作中也没用到过,所以一直是一知半解。但是我是属于比较较真的人,这次下定决心要把它们搞明白。知识在于积累,多点知识对自己总是有好处的。
我比较好奇的是,这几种方法到底哪个最快?我以前只知道冒泡排序,但这种方式可能是最慢的了。在网上搜了搜找到了这么一张图,看似蛮有道理的,如下:
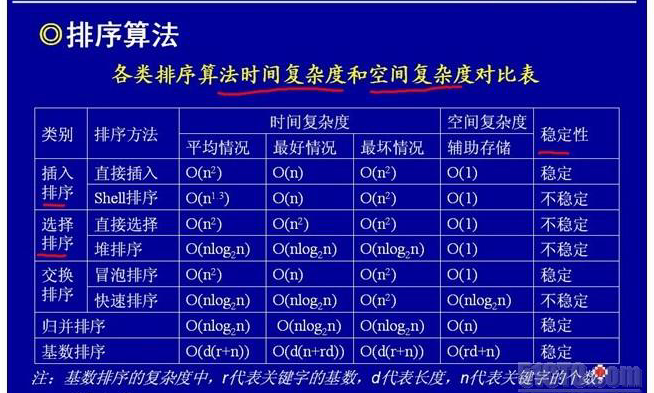
从这个图可以看出貌似 堆排序和归并排序 最快 因为无论好坏情况都是O(n*log2n),但我在实践中则不然。
随机不重复的整数
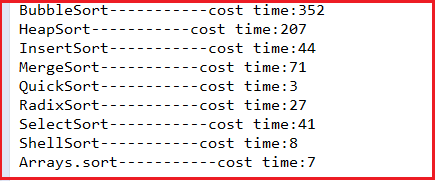
我们选择10000个随机不重复整数,可以看出快速排序
是最快的,并且是经过多次实验,名副其实,呵呵,它甚至比系统自带的Arrays.sot()都快,所以还是实践出真知。测试结果如下图:
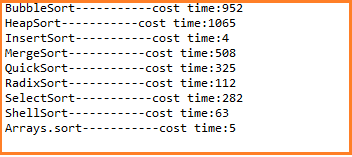
有序不重复整数
相反我们可以选择一万个有序不重复整数测试,插入排序 是最快的,而快速排序就不是最快的了,因为在有序中快速排序效果是很差的但不是最差的。测试结果如下图:
系统排序Arrays.sort()
Java Arrays中提供了对所有类型的排序。其中主要分为Primitive(8种基本类型)和Object两大类。
基本类型:采用调优的快速排序;
对象类型:采用改进的归并排序。
Java对Primitive(int,float等原型数据)数组采用快速排序,对Object对象数组采用归并排序。对这一区别,sun在<<The Java Tutorial>>中做出的解释如下:
The sort operation uses a slightly optimized merge sort algorithm that is fast and stable:
* Fast: It is guaranteed to run in n log(n) time and runs substantially faster on nearly sorted lists. Empirical tests showed it to be as fast as a highly optimized quicksort. A quicksort is generally considered to be faster than a merge sort but isn't stable
and doesn't guarantee n log(n) performance.
* Stable: It doesn't reorder equal elements. This is important if you sort the same list repeatedly on different attributes. If a user of a mail program sorts the inbox by mailing date and then sorts it by sender, the user naturally expects that the now-contiguous
list of messages from a given sender will (still) be sorted by mailing date. This is guaranteed only if the second sort was stable.
也就是说,优化的归并排序既快速(nlog(n))又稳定。
对于对象的排序,稳定性很重要。比如成绩单,一开始可能是按人员的学号顺序排好了的,现在让我们用成绩排,那么你应该保证,本来张三在李四前面,即使他们成绩相同,张三不能跑到李四的后面去。
而快速排序是不稳定的,而且最坏情况下的时间复杂度是O(n^2)。
另外,对象数组中保存的只是对象的引用,这样多次移位并不会造成额外的开销,但是,对象数组对比较次数一般比较敏感,有可能对象的比较比单纯数的比较开销大很多。归并排序在这方面比快速排序做得更好,这也是选择它作为对象排序的一个重要原因之一。
源码中的快速排序,主要做了以下几个方面的优化:
1)当待排序的数组中的元素个数较少时,源码中的阀值为7,采用的是插入排序。尽管插入排序的时间复杂度为0(n^2),但是当数组元素较少时,插入排序优于快速排序,因为这时快速排序的递归操作影响性能。
2)较好的选择了划分元(基准元素)。能够将数组分成大致两个相等的部分,避免出现最坏的情况。例如当数组有序的的情况下,选择第一个元素作为划分元,将使得算法的时间复杂度达到O(n^2).
源码中选择划分元的方法:
当数组大小为 size=7 时 ,取数组中间元素作为划分元。int n=m>>1;(此方法值得借鉴)
当数组大小 7<size<=40时,取首、中、末三个元素中间大小的元素作为划分元。
当数组大小 size>40 时 ,从待排数组中较均匀的选择9个元素,选出一个伪中数做为划分元。
各种排序算法并且有对应的舞蹈,太有创意了,哈哈。
舞蹈之快速排序:http://v.youku.com/v_show/id_XMzMyODk4NTQ4.html?from=s1.8-1-1.2
舞蹈之冒泡排序:http://v.youku.com/v_show/id_XMzMyOTAyMzQ0.html?from=s1.8-1-1.2
舞蹈之归并排序:http://v.youku.com/v_show/id_XMzMyODk5Njg4.html?from=s1.8-1-1.2
舞蹈之希尔排序:http://v.youku.com/v_show/id_XMzMyODk5MzI4.html?from=s1.8-1-1.2
舞蹈之选择排序:http://v.youku.com/v_show/id_XMzMyODk5MDI0.html?from=s1.8-1-1.2
舞蹈之插入排序:http://v.youku.com/v_show/id_XMzMyODk3NjI4.html?from=s1.8-1-1.2
下面主要是参考别人的一些文章讲讲快速排序,其它的大家可以自行搜索。快速排序由于排序效率在同为O(N*logN)的几种排序方法中效率较高,因此经常被采用,再加上快速排序思想----分治法也确实实用,因此很多软件公司的笔试面试,包括像腾讯,微软等知名IT公司都喜欢考这个,还有大大小的程序方面的考试如软考,考研中也常常出现快速排序的身影。
快速排序是C.R.A.Hoare于1962年提出的一种划分交换排序。它采用了一种分治的策略,通常称其为分治法(Divide-and-ConquerMethod)。
该方法的基本思想是:
1.先从数列中取出一个数作为基准数。
2.分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边。
3.再对左右区间重复第二步,直到各区间只有一个数。
虽然快速排序称为分治法,但分治法这三个字显然无法很好的概括快速排序的全部步骤。因此我的对快速排序作了进一步的说明:挖坑填数+分治法:
先来看实例吧,定义下面再给出(最好能用自己的话来总结定义,这样对实现代码会有帮助)。
以一个数组作为示例,取区间第一个数为基准数
由于已经将a[0]中的数保存到X中,可以理解成在数组a[0]上挖了个坑,可以将其它数据填充到这来。初始时,i = 0; j = 9; X = a[i] = 72
从j开始向前找一个比X小或等于X的数。当j=8,符合条件,将a[8]挖出再填到上一个坑a[0]中。a[0]=a[8]; i++; 这样一个坑a[0]就被搞定了,但又形成了一个新坑a[8],这怎么办了?简单,再找数字来填a[8]这个坑。这次从i开始向后找一个大于X的数,当i=3,符合条件,将a[3]挖出再填到上一个坑中a[8]=a[3]; j--;
数组变为:
再重复上面的步骤,先从后向前找,再从前向后找。 i = 3; j = 7; X=72
从j开始向前找,当j=5,符合条件,将a[5]挖出填到上一个坑中,a[3] = a[5]; i++;
从i开始向后找,当i=5时,由于i==j退出。
此时,i = j = 5,而a[5]刚好又是上次挖的坑,因此将X填入a[5]。
数组变为:
对挖坑填数进行总结可以看出a[5]前面的数字都小于它,a[5]后面的数字都大于它。因此再对a[0…4]和a[6…9]这二个子区间重复上述步骤就可以了。
1.i =L; j = R; 将基准数挖出形成第一个坑a[i]。
2.j--由后向前找比它小的数,找到后挖出此数填前一个坑a[i]中。
3.i++由前向后找比它大的数,找到后也挖出此数填到前一个坑a[j]中。
4.再重复执行2,3二步,直到i==j,将基准数填入a[i]中。
照着这个总结很容易实现挖坑填数的代码:
再写分治法的代码:
这样的代码显然不够简洁,对其组合整理下
快速排序还有很多改进版本,如1.随机选择基准数2.数据较少时用另外的方法排序以减小递归深度。有兴趣的同学可以参考一下:http://blog.csdn.net/insistgogo/article/details/7785038。
还可参考:http://www.jianshu.com/p/5e171281a387
下面是八种排序算法比较实践代码,大家可以下载运行研究一下。
源码地址,点击下载......
我比较好奇的是,这几种方法到底哪个最快?我以前只知道冒泡排序,但这种方式可能是最慢的了。在网上搜了搜找到了这么一张图,看似蛮有道理的,如下:
从这个图可以看出貌似 堆排序和归并排序 最快 因为无论好坏情况都是O(n*log2n),但我在实践中则不然。
随机不重复的整数
我们选择10000个随机不重复整数,可以看出快速排序
是最快的,并且是经过多次实验,名副其实,呵呵,它甚至比系统自带的Arrays.sot()都快,所以还是实践出真知。测试结果如下图:
有序不重复整数
相反我们可以选择一万个有序不重复整数测试,插入排序 是最快的,而快速排序就不是最快的了,因为在有序中快速排序效果是很差的但不是最差的。测试结果如下图:
系统排序Arrays.sort()
Java Arrays中提供了对所有类型的排序。其中主要分为Primitive(8种基本类型)和Object两大类。
基本类型:采用调优的快速排序;
对象类型:采用改进的归并排序。
Java对Primitive(int,float等原型数据)数组采用快速排序,对Object对象数组采用归并排序。对这一区别,sun在<<The Java Tutorial>>中做出的解释如下:
The sort operation uses a slightly optimized merge sort algorithm that is fast and stable:
* Fast: It is guaranteed to run in n log(n) time and runs substantially faster on nearly sorted lists. Empirical tests showed it to be as fast as a highly optimized quicksort. A quicksort is generally considered to be faster than a merge sort but isn't stable
and doesn't guarantee n log(n) performance.
* Stable: It doesn't reorder equal elements. This is important if you sort the same list repeatedly on different attributes. If a user of a mail program sorts the inbox by mailing date and then sorts it by sender, the user naturally expects that the now-contiguous
list of messages from a given sender will (still) be sorted by mailing date. This is guaranteed only if the second sort was stable.
也就是说,优化的归并排序既快速(nlog(n))又稳定。
对于对象的排序,稳定性很重要。比如成绩单,一开始可能是按人员的学号顺序排好了的,现在让我们用成绩排,那么你应该保证,本来张三在李四前面,即使他们成绩相同,张三不能跑到李四的后面去。
而快速排序是不稳定的,而且最坏情况下的时间复杂度是O(n^2)。
另外,对象数组中保存的只是对象的引用,这样多次移位并不会造成额外的开销,但是,对象数组对比较次数一般比较敏感,有可能对象的比较比单纯数的比较开销大很多。归并排序在这方面比快速排序做得更好,这也是选择它作为对象排序的一个重要原因之一。
源码中的快速排序,主要做了以下几个方面的优化:
1)当待排序的数组中的元素个数较少时,源码中的阀值为7,采用的是插入排序。尽管插入排序的时间复杂度为0(n^2),但是当数组元素较少时,插入排序优于快速排序,因为这时快速排序的递归操作影响性能。
2)较好的选择了划分元(基准元素)。能够将数组分成大致两个相等的部分,避免出现最坏的情况。例如当数组有序的的情况下,选择第一个元素作为划分元,将使得算法的时间复杂度达到O(n^2).
源码中选择划分元的方法:
当数组大小为 size=7 时 ,取数组中间元素作为划分元。int n=m>>1;(此方法值得借鉴)
当数组大小 7<size<=40时,取首、中、末三个元素中间大小的元素作为划分元。
当数组大小 size>40 时 ,从待排数组中较均匀的选择9个元素,选出一个伪中数做为划分元。
各种排序算法并且有对应的舞蹈,太有创意了,哈哈。
舞蹈之快速排序:http://v.youku.com/v_show/id_XMzMyODk4NTQ4.html?from=s1.8-1-1.2
舞蹈之冒泡排序:http://v.youku.com/v_show/id_XMzMyOTAyMzQ0.html?from=s1.8-1-1.2
舞蹈之归并排序:http://v.youku.com/v_show/id_XMzMyODk5Njg4.html?from=s1.8-1-1.2
舞蹈之希尔排序:http://v.youku.com/v_show/id_XMzMyODk5MzI4.html?from=s1.8-1-1.2
舞蹈之选择排序:http://v.youku.com/v_show/id_XMzMyODk5MDI0.html?from=s1.8-1-1.2
舞蹈之插入排序:http://v.youku.com/v_show/id_XMzMyODk3NjI4.html?from=s1.8-1-1.2
冒泡排序算法:
public BubbleSort(Integer ar[]){
Integer a[]=ar.clone();
long currentTime=System.currentTimeMillis();
int temp=0;
for(int i=0;i<a.length-1;i++){
for(int j=0;j<a.length-1-i;j++){
if(a[j]>a[j+1]){
temp=a[j];
a[j]=a[j+1];
a[j+1]=temp;
}
}
}
long nowTime=System.currentTimeMillis();
System.out.println("BubbleSort-----------cost time:"+(nowTime-currentTime));
// System.out.println(Arrays.toString( a));
}
}快速排序算法:
public class QuickSort {
public QuickSort(Integer ar[]){
Integer a[]=ar.clone();
long currentTime=System.currentTimeMillis();
quick(a);
long nowTime=System.currentTimeMillis();
System.out.println("QuickSort-----------cost time:"+(nowTime-currentTime));
// System.out.println(Arrays.toString( a));
}
public int getMiddle(Integer[] list, int low, int high) {
int tmp = list[low]; //数组的第一个作为中轴
while (low < high) {
while (low < high && list[high] >= tmp) {
high--;
}
list[low] = list[high]; //比中轴小的记录移到低端
while (low < high && list[low] <= tmp) {
low++;
}
list[high] = list[low]; //比中轴大的记录移到高端
}
list[low] = tmp; //中轴记录到尾
return low; //返回中轴的位置
}
public void _quickSort(Integer[] list, int low, int high) {
if (low < high) {
int middle = getMiddle(list, low, high); //将list数组进行一分为二
_quickSort(list, low, middle - 1); //对低字表进行递归排序
_quickSort(list, middle + 1, high); //对高字表进行递归排序
}
}
public void quick(Integer[] a2) {
if (a2.length > 0) { //查看数组是否为空
_quickSort(a2, 0, a2.length - 1);
}
}
}堆排序算法:
public class HeapSort {
public HeapSort(Integer ar[]){
Integer a[]=ar.clone();
long currentTime=System.currentTimeMillis();
heapSort(a);
long nowTime=System.currentTimeMillis();
System.out.println("HeapSort-----------cost time:"+(nowTime-currentTime));
// System.out.println(Arrays.toString( a));
}
public void heapSort(Integer[] a){
int arrayLength=a.length;
//循环建堆
for(int i=0;i<arrayLength-1;i++){
//建堆
buildMaxHeap(a,arrayLength-1-i);
//交换堆顶和最后一个元素
swap(a,0,arrayLength-1-i);
}
}
private void swap(Integer[] data, int i, int j) {
// TODO Auto-generated method stub
int tmp=data[i];
data[i]=data[j];
data[j]=tmp;
}
//对data数组从0到lastIndex建大顶堆
private void buildMaxHeap(Integer[] data, int lastIndex) {
// TODO Auto-generated method stub
//从lastIndex处节点(最后一个节点)的父节点开始
for(int i=(lastIndex-1)/2;i>=0;i--){
//k保存正在判断的节点
int k=i;
//如果当前k节点的子节点存在
while(k*2+1<=lastIndex){
//k节点的左子节点的索引
int biggerIndex=2*k+1;
//如果biggerIndex小于lastIndex,即biggerIndex+1代表的k节点的右子节点存在
if(biggerIndex<lastIndex){
//若果右子节点的值较大
if(data[biggerIndex]<data[biggerIndex+1]){
//biggerIndex总是记录较大子节点的索引
biggerIndex++;
}
}
//如果k节点的值小于其较大的子节点的值
if(data[k]<data[biggerIndex]){
//交换他们
swap(data,k,biggerIndex);
//将biggerIndex赋予k,开始while循环的下一次循环,重新保证k节点的值大于其左右子节点的值
k=biggerIndex;
}else{
break;
}
}
}
}
}插入排序算法:
public class InsertSort {
public InsertSort(Integer ar[]){
Integer a[]=ar.clone();
long currentTime=System.currentTimeMillis();
int temp=0;
for(int i=1;i<a.length;i++){
int j=i-1;
temp=a[i];
for(;j>=0&&temp<a[j];j--){
a[j+1]=a[j]; //将大于temp的值整体后移一个单位
}
a[j+1]=temp;
}
long nowTime=System.currentTimeMillis();
System.out.println("InsertSort-----------cost time:"+(nowTime-currentTime));
// System.out.println(Arrays.toString( a));
}
}合并排序算法:
public class MergeSort {
public MergeSort(Integer ar[]){
Integer a[]=ar.clone();
long currentTime=System.currentTimeMillis();
sort(a,0,a.length-1);
long nowTime=System.currentTimeMillis();
System.out.println("MergeSort-----------cost time:"+(nowTime-currentTime));
// System.out.println(Arrays.toString( a));
}
public void sort(Integer[] data, int left, int right) {
// TODO Auto-generated method stub
if(left<right){
//找出中间索引
int center=(left+right)/2;
//对左边数组进行递归
sort(data,left,center);
//对右边数组进行递归
sort(data,center+1,right);
//合并
merge(data,left,center,right);
}
}
public void merge(Integer[] data, int left, int center, int right) {
// TODO Auto-generated method stub
int [] tmpArr=new int[data.length];
int mid=center+1;
//third记录中间数组的索引
int third=left;
int tmp=left;
while(left<=center&&mid<=right){
//从两个数组中取出最小的放入中间数组
if(data[left]<=data[mid]){
tmpArr[third++]=data[left++];
}else{
tmpArr[third++]=data[mid++];
}
}
//剩余部分依次放入中间数组
while(mid<=right){
tmpArr[third++]=data[mid++];
}
while(left<=center){
tmpArr[third++]=data[left++];
}
//将中间数组中的内容复制回原数组
while(tmp<=right){
data[tmp]=tmpArr[tmp++];
}
}
}基排序算法:
public RadixSort(Integer ar[]){
Integer a[]=ar.clone();
long currentTime=System.currentTimeMillis();
sort(a);
long nowTime=System.currentTimeMillis();
System.out.println("RadixSort-----------cost time:"+(nowTime-currentTime));
// System.out.println(Arrays.toString( a));
}
public void sort(Integer[] array){
//首先确定排序的趟数;
int max=array[0];
for(int i=1;i<array.length;i++){
if(array[i]>max){
max=array[i];
}
}
int time=0;
//判断位数;
while(max>0){
max/=10;
time++;
}
//建立10个队列;
List<List> queue=new ArrayList<List>();
for(int i=0;i<10;i++){
ArrayList<Integer> queue1=new ArrayList<Integer>();
queue.add(queue1);
}
//进行time次分配和收集;
for(int i=0;i<time;i++){
//分配数组元素;
for(int j=0;j<array.length;j++){
//得到数字的第time+1位数;
int x=array[j]%(int)Math.pow(10, i+1)/(int)Math.pow(10, i);
ArrayList<Integer> queue2=(ArrayList<Integer>) queue.get(x);
queue2.add(array[j]);
queue.set(x, queue2);
}
int count=0;//元素计数器;
//收集队列元素;
for(int k=0;k<10;k++){
while(queue.get(k).size()>0){
ArrayList<Integer> queue3=(ArrayList<Integer>) queue.get(k);
array[count]=queue3.get(0);
queue3.remove(0);
count++;
}
}
}
}
}选择排序算法:
public class SelectSort {
public SelectSort(Integer ar[]){
Integer a[]=ar.clone();
long currentTime=System.currentTimeMillis();
int position=0;
for(int i=0;i<a.length;i++){
int j=i+1;
position=i;
int temp=a[i];
for(;j<a.length;j++){
if(a[j]<temp){
temp=a[j];
position=j;
}
}
a[position]=a[i];
a[i]=temp;
}
long nowTime=System.currentTimeMillis();
System.out.println("SelectSort-----------cost time:"+(nowTime-currentTime));
// System.out.println(Arrays.toString( a));
}
}希尔排序算法:
public class ShellSort {
public ShellSort(Integer ar[]){
Integer a[]=ar.clone();
long currentTime=System.currentTimeMillis();
double d1=a.length;
int temp=0;
while(true){
d1= Math.ceil(d1/2);
int d=(int) d1;
for(int x=0;x<d;x++){
for(int i=x+d;i<a.length;i+=d){
int j=i-d;
temp=a[i];
for(;j>=0&&temp<a[j];j-=d){
a[j+d]=a[j];
}
a[j+d]=temp;
}
}
if(d==1)
break;
}
long nowTime=System.currentTimeMillis();
System.out.println("ShellSort-----------cost time:"+(nowTime-currentTime));
// System.out.println(Arrays.toString( a));
}
}下面主要是参考别人的一些文章讲讲快速排序,其它的大家可以自行搜索。快速排序由于排序效率在同为O(N*logN)的几种排序方法中效率较高,因此经常被采用,再加上快速排序思想----分治法也确实实用,因此很多软件公司的笔试面试,包括像腾讯,微软等知名IT公司都喜欢考这个,还有大大小的程序方面的考试如软考,考研中也常常出现快速排序的身影。
快速排序是C.R.A.Hoare于1962年提出的一种划分交换排序。它采用了一种分治的策略,通常称其为分治法(Divide-and-ConquerMethod)。
该方法的基本思想是:
1.先从数列中取出一个数作为基准数。
2.分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边。
3.再对左右区间重复第二步,直到各区间只有一个数。
虽然快速排序称为分治法,但分治法这三个字显然无法很好的概括快速排序的全部步骤。因此我的对快速排序作了进一步的说明:挖坑填数+分治法:
先来看实例吧,定义下面再给出(最好能用自己的话来总结定义,这样对实现代码会有帮助)。
以一个数组作为示例,取区间第一个数为基准数
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 72 | 6 | 57 | 88 | 60 | 42 | 83 | 73 | 48 | 85 |
从j开始向前找一个比X小或等于X的数。当j=8,符合条件,将a[8]挖出再填到上一个坑a[0]中。a[0]=a[8]; i++; 这样一个坑a[0]就被搞定了,但又形成了一个新坑a[8],这怎么办了?简单,再找数字来填a[8]这个坑。这次从i开始向后找一个大于X的数,当i=3,符合条件,将a[3]挖出再填到上一个坑中a[8]=a[3]; j--;
数组变为:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 48 | 6 | 57 | 88 | 60 | 42 | 83 | 73 | 88 | 85 |
从j开始向前找,当j=5,符合条件,将a[5]挖出填到上一个坑中,a[3] = a[5]; i++;
从i开始向后找,当i=5时,由于i==j退出。
此时,i = j = 5,而a[5]刚好又是上次挖的坑,因此将X填入a[5]。
数组变为:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 48 | 6 | 57 | 42 | 60 | 72 | 83 | 73 | 88 | 85 |
1.i =L; j = R; 将基准数挖出形成第一个坑a[i]。
2.j--由后向前找比它小的数,找到后挖出此数填前一个坑a[i]中。
3.i++由前向后找比它大的数,找到后也挖出此数填到前一个坑a[j]中。
4.再重复执行2,3二步,直到i==j,将基准数填入a[i]中。
照着这个总结很容易实现挖坑填数的代码:
int AdjustArray(int s[], int l, int r) //返回调整后基准数的位置
{
int i = l, j = r;
int x = s[l]; //s[l]即s[i]就是第一个坑
while (i < j)
{
// 从右向左找小于x的数来填s[i]
while(i < j && s[j] >= x)
j--;
if(i < j)
{
s[i] = s[j]; //将s[j]填到s[i]中,s[j]就形成了一个新的坑
i++;
}
// 从左向右找大于或等于x的数来填s[j]
while(i < j && s[i] < x)
i++;
if(i < j)
{
s[j] = s[i]; //将s[i]填到s[j]中,s[i]就形成了一个新的坑
j--;
}
}
//退出时,i等于j。将x填到这个坑中。
s[i] = x;
return i;
}再写分治法的代码:
void quick_sort1(int s[], int l, int r)
{
if (l < r)
{
int i = AdjustArray(s, l, r);//先成挖坑填数法调整s[]
quick_sort1(s, l, i - 1); // 递归调用
quick_sort1(s, i + 1, r);
}
}这样的代码显然不够简洁,对其组合整理下
//快速排序
void quick_sort(int s[], int l, int r)
{
if (l < r)
{
//Swap(s[l], s[(l + r) / 2]); //将中间的这个数和第一个数交换 参见注1
int i = l, j = r, x = s[l];
while (i < j)
{
while(i < j && s[j] >= x) // 从右向左找第一个小于x的数
j--;
if(i < j)
s[i++] = s[j];
while(i < j && s[i] < x) // 从左向右找第一个大于等于x的数
i++;
if(i < j)
s[j--] = s[i];
}
s[i] = x;
quick_sort(s, l, i - 1); // 递归调用
quick_sort(s, i + 1, r);
}
}快速排序还有很多改进版本,如1.随机选择基准数2.数据较少时用另外的方法排序以减小递归深度。有兴趣的同学可以参考一下:http://blog.csdn.net/insistgogo/article/details/7785038。
还可参考:http://www.jianshu.com/p/5e171281a387
源码地址,点击下载......

相关文章推荐
- 使用C++实现JNI接口需要注意的事项
- Android IPC进程间通讯机制
- Android Manifest 用法
- [转载]Activity中ConfigChanges属性的用法
- Android之获取手机上的图片和视频缩略图thumbnails
- Android之使用Http协议实现文件上传功能
- Android学习笔记(二九):嵌入浏览器
- android string.xml文件中的整型和string型代替
- i-jetty环境搭配与编译
- android之定时器AlarmManager
- android wifi 无线调试
- Android Native 绘图方法
- Android java 与 javascript互访(相互调用)的方法例子
- android 代码实现控件之间的间距
- android FragmentPagerAdapter的“标准”配置
- Android"解决"onTouch和onClick的冲突问题
- android:installLocation简析
- android searchView的关闭事件
- SourceProvider.getJniDirectories