storm 学习教程
2016-05-30 16:31
501 查看
翻译太累了,再也不想去翻译了,真的太累了:
在这个教程中, 你将学到如何创建一个Storm topologies以及怎样把它部署到storm集群上。本教程中,Java将作为主要使用的语言,但在一小部分示例中将会使用Python来阐述storm处理多语言的能力。
本教程使用的例子来自于 storm-starter 项目. 我们建议你拷贝该项目并跟随这个例子来进行学习。 请阅读 Setting
up a development environment 和 Creating a new Storm project 创建好相应的基础环境。
Storm集群在表面上与Hadoop集群相似。在Hadoop上运行"MapReduce jobs",而在Storm上运行的是"topologies"。
"Jobs" and "topologies" 它们本身非常的不同 -- 一个关键的不同的是MapReduce job最终会完成并结束,而topology的消息处理将无限期进行下去(除非你kill它)。
在storm集群中,有两类节点。Master节点运行守护进程称为"Nimbus",它有点像 Hadoop 的 "JobTracker"。Nimbus负责集群的代码分发,任务分配,故障监控。
每个工作节点运行的守护进程称为"Supervisor"。Supervisor 负责监听分配到它自己机器的作业,根据需要启动和停止相应的工作进程,当然这些工作进程也是Nimbus分派给它的。每个工作进程执行topology的一个子集;一个运行的topology是由分布在多个机器的多个工作进程组成的。
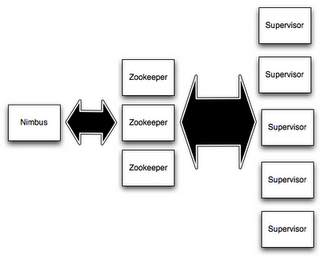
Nimbus 与 Supervisors 所有的协调工作是由 Zookeeper 集群完成的.
此外,Nimbus 守护进程 和
Supervisor 守护进程 是无状态的,快速失败的机制。 所有的状态保存在Zookeeper上或者本地磁盘中。这就是说,你用kill -9杀掉Nimbus 或者Supervisors,它们重新启动后就像什么都没有发生一样,这样的设计让storm集群拥有令人难以置信的稳定性。
在Storm上进行实时计算,你需要创建名为 "topologies" 的这么个东西。一个topology是一个计算的图,每个在topology中的节点(以下部分也称作“组件”)包含了处理逻辑,以及多个节点间数据传送的联系和方式。运行一个topology很直接简单的。第一,你把你的java
code和它所有的依赖打成一个单独的jar包。然后,你用如下的命令去运行就可以了。
这个例子中运行的类是
这个类的主要功能是定义topology,并被提交到Nimbus中。命令
因为topology的定义方式就是Thrift的结构,Nimbus也是一个Thrift服务,所以你可以用任何语言去创建topologies并提交。以上的例子是最简单的方式去使用基于JVM的语言(比如java)创建的topology。请阅读 Running
topologies on a production cluster 来获得更多的信息关于topology的启动和停止。
Storm里的核心抽象就是 "流"。流 是一个无界的 元组序列。Storm提供原始地、分布式地、可靠地方式 把一个流转变成一个新的流。举例来说,
你可以把一个 tweet 流 转换成一个 趋势主题 的流。
Storm中提供 流转换 的最主要的原生方式是 "spouts" and "bolts"。Spouts 和 bolts 有相应的接口,你需要用你的应用的特定逻辑实现接口即可。
Spout是 流 的源头。举例来说,一个spout也许会从 Kestrel 队列中读取数据并以流的方式发射出来,亦或者一个spout也许会连接Twitter的API,
并发出一个关于tweets的流。
一个bolt可以消费任意数量的输入流,并做一些处理,也可以由此发出一个新的流。复杂流的转换,像从一个tweet流中计算出一个关于趋势话题的流,它要求多个步骤,因此也需要多个bolt。Bolts 能做任何事情,运行方法,过滤元组,做流的聚合,流的连接,写入数据库等。
Spouts 和 bolts 组成的网络 打包到 "topology" 中,它是顶级的抽象,是你需要提交到storm集群执行的东西。一个topology是一个由spout和bolt组成的 做流转换 的图,其中图中的每个节点都可以是一个spout或者一个bolt。图中的边表明了bolt订阅了哪些流,亦或是当一个spout或者bolt发射元组到流中,它发出的元组数据到订阅这个流的所有bolt中去。
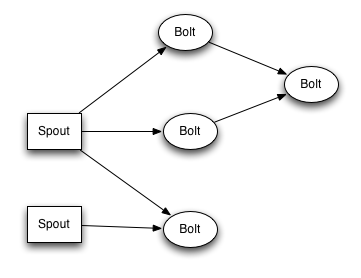
topology中节点之间的联系表明了元组数据是怎样去传送的。举例来说,Spout A 和 Bolt B 相连(A 到 B),Spout A 和 Bolt C 相连(A 到 C),Bolt B 和 Bolt C相连(B 到 C)。每当Spout A发出元组数据时,它会同时发给Bolt B 和 Bolt C。再者,所有Bolt B的输出元组,也会发给Bolt C。
在topology中的每个节点都是并行运行的。因此在你的topology中,你可以为每个节点指定并行运行的数量,然后storm集群将会产生相应数量的线程来执行。
一个topology无限运行,直到你杀掉它才会停止。Storm将自动地重新分配失败过的任务。此外,Storm保证不会有数据丢失,即便是机器挂掉,消息被丢弃。
Storm用元组作为它的数据模型。一个元组是一个命名的,有值的,一般由过个字段组成的序列,序列中的每个字段可以是任何类型的对象。在沙箱之外,Storm提供所有的原始类型,字符串,byte数组作为元组的字段值。如果想用一个其他类型的对象,你需要实现a
serializer 接口。
每个topology节点必须声明输出元组的字段。举例来说,这个bolt声明它将输出带有"double" and "triple"两个字段的元组:
让我们去看一个简单的 topology,去探索更多的概念,去看一下它的代码到底长什么样。让我们看一下
这个topology包含了一个spout和两个bolt,这个spout发出words,然后每个bolt都在自己的读入字符串上加上"!!!"。
这些节点被安排成一条线:spout发给第一个bolt,第一个bolt发给第二个bolt。如果spout发出的元组数据是["bob"] 和 ["john"],通过第二个
bolt后,将发出["bob!!!!!!"] 和 ["john!!!!!!"]。
代码中用
一个用户指定的id,包含处理逻辑的对象,你希望该节点并行计算的数量。在这个例子中,这个 spout 的id是 "words" ,两个bolt的id分别为 "exclaim1" 和 "exclaim2"。
包含处理逻辑的spout对象实现了 IRichSpout 接口,bolt对象实现了 IRichBolt 接口。
最后一个参数,是你希望该节点并行计算的数量是多少,这是可选的。它表明了会有多少线程会通过storm集群来执行这个组件(spout或bolt)。
如果你忽略它,Storm集群会分配单线程给该节点。
"exclaim1" 声明了它希望通过shuffle分组的方式读取 spout "words"中的所有元组。同理,Bolt "exclaim2"
声明了它希望通过shuffle分组的方式读取 bolt "exclaim1" 所发出的元组数据。
"shuffle 分组" 指元组数据 将会 随机分布地 从输入任务 到bolt任务中。在多个组件(spout或bolt)之间,这里有很多数据分组的方式。
这在接下来的章节中会说明。
如果你希望bolt "exclaim2" 从 spout "words" 和 bolt "exclaim1"
读取所有的元组数据,你需要像下面这样定义:
如你所见,输入的定义可以是链式的,bolt可以指定多个源。
让我们深入了解一下spout和bolt在topology中的实现。Spout负责发送新的数据到topology中。
发送了一个随机的单词,单词来自列表["nathan", "mike", "jackson", "golda", "bertels"]。在 TestWordSpout 中的
如你所见,这个实现非常简单明了。
-- 可以在
或者
在另一个线程,异步地发送。 这里的
"!!!" 。如果你实现的bolt订阅了多个输入源,你可以用 Tuple 中的
在
即输入的元组作为第一个参数 发出 ,然后在最后一行中发出确认消息。这是Storm保证可靠性的API的一部分,它保证数据不会丢失,这在之后的教程会说明。
当一个Bolt将要停止、关闭时,它需要关闭当前打开的资源,此时
需要注意的是,这并不保证这个方法在storm集群中一定会被调用:举例来说,如果机器上的任务爆发,这就不会调用这个方法。
mode 上运行你的topology(模拟storm集群的仿真模式), 你能够启动和停止很多topology且不会遭受任何资源泄露的问题。
的带一个字段的元组。
Configuration.
通常像
让我们来看一下如何在本地模式上运行
Storm有两种操作模式:本地模式和分布式模式。在本地模式中,Storm通过线程模拟工作节点并在一个进程中完成执行。本地模式在用于开发和测试topology时是很有用处的。当你在本地模式中运行 storm-starter 项目中的 topology 时,你就能看到每个组件发送了什么信息。你可以获取更多关于在本地模式上运行topology的信息,请参见 Local
mode。
在分布式模式中,Storm操作的是机器集群。当你提交一个topology给master,你也需要提交运行这个topology所必须的代码。Master将会关注于分发你的代码并分配worker去运行你的topology。如果worker挂掉,master将会重新分配这些代码、topology到其他地方。你可以获取更多关于在分布式模式上运行topology的信息,请参见 Running
topologies on a production cluster。
这是在本地模式上运行
首先,代码中定义了单进程的伪集群,通过创建
topology的名字,topology的配置,topology本身。
topology的名称是为了标识topology,以便你之后可以停掉它。一个topology将无限期运行,直到你停掉它。
topology的配置可以从多个方面调整topology运行时的形态。这里给出了两个最为常见的配置:
TOPOLOGY_WORKERS (用
表明你希望在storm集群中分配多少进程来执行你的topology。每个在topology中的组件(spout 或 bolt)将会被分配多个线程去执行。线程数的设置是通过组件的
每个worker进程包含了处理一些组件的一些线程,例如,你横跨集群指定了300个线程处理所有的组件,且指定了50个worker进程。也就是说,每个工作进程将执行6个线程, 其中的每一个可能又属于不同的组件。调整topology的性能需要通过调整每个组件的并行线程数 和 工作进程中运行的线程数量。
TOPOLOGY_DEBUG (用
这里有很多其他的topology的配置,更多细节请参见 the Javadoc for Config.
学习如何建立自己的开发环境,以便你能用本地模式运行你的topology(比如在eclipse里),请参见 Creating
a new Storm project.
流的分组方式告诉一个topology,两个组件是通过怎样的方式传递元组数据。记住,spout 和 bolt 是并行执行在集群上的多个任务中的。如果你想知道一个topology是如何在任务层执行的,它也许就是这样的:
从上图可知,bolt A 有4个task,bolt B有3个task。当bolt A的1个task 发出一个元组给 bolt B,那么bolt A的这个task应该发给bolt B的哪个task呢?
流的分组方式通过告诉storm在两个任务集(上图的 bolt A 的任务集 合 bolt B的任务集)发送元组信息的方式 回答了这个问题。
在我们深入研究不同的流的分组策略前,我们先看一下另一个来自 storm-starter 项目的例子。 WordCountTopology 从spout读取一句话,并分流给
收到一个单词,它将更新map的状态并发出最新的单词统计。
这里有几种不同的流的分组方式。
最简单的分组方式称作 "shuffle grouping" ,这种方式是将元组数据发送给随机的任务。shuffle grouping
用于
的部分。它很有效地把元组数组 均匀分给所有的
的任务。
一个更有趣的分组方式叫做 "fields grouping"。在本例中,字段分组用于
和
WordCount 的功能至关重要,它保证了相同的单词只会去相同的任务中。否则,会有多个任务接收到相同的单词,它们各自发出的单词统计也是不正确的,因为它们获得的都是不全的信息。 fields grouping 让你可以通过字段来进行数据流的分组,这样就导致了相同的字段值会进入到相同的任务中去。
grouping的方式,本例针对 "word" 字段进行分组, 使相同的单词进入了相同的任务,bolt 就可以给出正确的结果了。
Fields groupings 是 流的连接 和 聚合 的基础实现,它也有其他很多的例子。
在底层, fields groupings 使用 mod hashing 算法来实现的。
这里还有一些其他的分组方式,更多信息请参见 Concepts.
Bolts 可以用任何语言定义。用其他语言写的 Bolts ,是以子进程的方式运行,storm与子进程通信的方式是 通过输入输出 JSON 数据来实现的。通信协议只需要1个100行的适配器代码的库, Storm附带了 Ruby, Python, and Fancy 的适配器的库。
这是
这是
更多关于用其他语言编写 spout 和 bolt 的信息,创建topology的信息 (以及完全避免 JVM 的方式), 请参见 Using
non-JVM languages with Storm.
本教程前面部分,我们跳过了一些方面如元组是怎么发出的,这些方面涉及了Storm的可靠性的API:Storm是如何保证每条来自于spout的消息会被完全完整地被处理。 参见 Guaranteeing
message processing 信息看它是如何工作的,以及作为用户的你,如何使用storm的可靠性能的这一优点。
Storm 保证每条信息至少被处理一次. 一个大众化的问题被提出: "你怎么在storm顶层上进行计数操作?计数值会不会超量?" Storm 有一个特性称作事务型topologies,在绝大部分的计算场景中,它的实现可以让消息只传递一次。获取更多事务型的topologies的信息: here.
本教程介绍了storm顶层的核心流的处理过程。storm原生部分 是有很多的事情可以去做的,其中最有意思的应用就是storm的分布式RPC,它具有很强的并行计算的性能。获取更多的关于分布式RPC的信息: here.
这个教程给出了一个关于storm开发,测试,部署的概览,剩余的文档将深入storm的每个方面。
在这个教程中, 你将学到如何创建一个Storm topologies以及怎样把它部署到storm集群上。本教程中,Java将作为主要使用的语言,但在一小部分示例中将会使用Python来阐述storm处理多语言的能力。
预备工作
本教程使用的例子来自于 storm-starter 项目. 我们建议你拷贝该项目并跟随这个例子来进行学习。 请阅读 Settingup a development environment 和 Creating a new Storm project 创建好相应的基础环境。
Storm集群的组件
Storm集群在表面上与Hadoop集群相似。在Hadoop上运行"MapReduce jobs",而在Storm上运行的是"topologies"。"Jobs" and "topologies" 它们本身非常的不同 -- 一个关键的不同的是MapReduce job最终会完成并结束,而topology的消息处理将无限期进行下去(除非你kill它)。
在storm集群中,有两类节点。Master节点运行守护进程称为"Nimbus",它有点像 Hadoop 的 "JobTracker"。Nimbus负责集群的代码分发,任务分配,故障监控。
每个工作节点运行的守护进程称为"Supervisor"。Supervisor 负责监听分配到它自己机器的作业,根据需要启动和停止相应的工作进程,当然这些工作进程也是Nimbus分派给它的。每个工作进程执行topology的一个子集;一个运行的topology是由分布在多个机器的多个工作进程组成的。
Nimbus 与 Supervisors 所有的协调工作是由 Zookeeper 集群完成的.
此外,Nimbus 守护进程 和
Supervisor 守护进程 是无状态的,快速失败的机制。 所有的状态保存在Zookeeper上或者本地磁盘中。这就是说,你用kill -9杀掉Nimbus 或者Supervisors,它们重新启动后就像什么都没有发生一样,这样的设计让storm集群拥有令人难以置信的稳定性。
Topologies
在Storm上进行实时计算,你需要创建名为 "topologies" 的这么个东西。一个topology是一个计算的图,每个在topology中的节点(以下部分也称作“组件”)包含了处理逻辑,以及多个节点间数据传送的联系和方式。运行一个topology很直接简单的。第一,你把你的javacode和它所有的依赖打成一个单独的jar包。然后,你用如下的命令去运行就可以了。
storm jar all-my-code.jar org.apache.storm.MyTopology arg1 arg2
这个例子中运行的类是
org.apache.storm.MyTopology且带着两个参数
arg1和
arg2.
这个类的主要功能是定义topology,并被提交到Nimbus中。命令
storm jar就是用来加载这个topology jar的。
因为topology的定义方式就是Thrift的结构,Nimbus也是一个Thrift服务,所以你可以用任何语言去创建topologies并提交。以上的例子是最简单的方式去使用基于JVM的语言(比如java)创建的topology。请阅读 Running
topologies on a production cluster 来获得更多的信息关于topology的启动和停止。
流
Storm里的核心抽象就是 "流"。流 是一个无界的 元组序列。Storm提供原始地、分布式地、可靠地方式 把一个流转变成一个新的流。举例来说,你可以把一个 tweet 流 转换成一个 趋势主题 的流。
Storm中提供 流转换 的最主要的原生方式是 "spouts" and "bolts"。Spouts 和 bolts 有相应的接口,你需要用你的应用的特定逻辑实现接口即可。
Spout是 流 的源头。举例来说,一个spout也许会从 Kestrel 队列中读取数据并以流的方式发射出来,亦或者一个spout也许会连接Twitter的API,
并发出一个关于tweets的流。
一个bolt可以消费任意数量的输入流,并做一些处理,也可以由此发出一个新的流。复杂流的转换,像从一个tweet流中计算出一个关于趋势话题的流,它要求多个步骤,因此也需要多个bolt。Bolts 能做任何事情,运行方法,过滤元组,做流的聚合,流的连接,写入数据库等。
Spouts 和 bolts 组成的网络 打包到 "topology" 中,它是顶级的抽象,是你需要提交到storm集群执行的东西。一个topology是一个由spout和bolt组成的 做流转换 的图,其中图中的每个节点都可以是一个spout或者一个bolt。图中的边表明了bolt订阅了哪些流,亦或是当一个spout或者bolt发射元组到流中,它发出的元组数据到订阅这个流的所有bolt中去。
topology中节点之间的联系表明了元组数据是怎样去传送的。举例来说,Spout A 和 Bolt B 相连(A 到 B),Spout A 和 Bolt C 相连(A 到 C),Bolt B 和 Bolt C相连(B 到 C)。每当Spout A发出元组数据时,它会同时发给Bolt B 和 Bolt C。再者,所有Bolt B的输出元组,也会发给Bolt C。
在topology中的每个节点都是并行运行的。因此在你的topology中,你可以为每个节点指定并行运行的数量,然后storm集群将会产生相应数量的线程来执行。
一个topology无限运行,直到你杀掉它才会停止。Storm将自动地重新分配失败过的任务。此外,Storm保证不会有数据丢失,即便是机器挂掉,消息被丢弃。
数据模型
Storm用元组作为它的数据模型。一个元组是一个命名的,有值的,一般由过个字段组成的序列,序列中的每个字段可以是任何类型的对象。在沙箱之外,Storm提供所有的原始类型,字符串,byte数组作为元组的字段值。如果想用一个其他类型的对象,你需要实现aserializer 接口。
每个topology节点必须声明输出元组的字段。举例来说,这个bolt声明它将输出带有"double" and "triple"两个字段的元组:
public class DoubleAndTripleBolt extends BaseRichBolt {
private OutputCollectorBase _collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollectorBase collector) {
_collector = collector;
}
@Override
public void execute(Tuple input) {
int val = input.getInteger(0);
_collector.emit(input, new Values(val*2, val*3));
_collector.ack(input);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("double", "triple"));
}
}declareOutputFields方法声明了该bolt的输出的字段
["double", "triple"].这个bolt的剩余部分将在接下来进行说明。
一个简单topology
让我们去看一个简单的 topology,去探索更多的概念,去看一下它的代码到底长什么样。让我们看一下 ExclamationTopology的定义,来自storm-starter的项目:
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("words", new TestWordSpout(), 10);
builder.setBolt("exclaim1", new ExclamationBolt(), 3)
.shuffleGrouping("words");
builder.setBolt("exclaim2", new ExclamationBolt(), 2)
.shuffleGrouping("exclaim1");这个topology包含了一个spout和两个bolt,这个spout发出words,然后每个bolt都在自己的读入字符串上加上"!!!"。
这些节点被安排成一条线:spout发给第一个bolt,第一个bolt发给第二个bolt。如果spout发出的元组数据是["bob"] 和 ["john"],通过第二个
bolt后,将发出["bob!!!!!!"] 和 ["john!!!!!!"]。
代码中用
setSpout和
setBolt方法定义了节点。这些方法的输入是
一个用户指定的id,包含处理逻辑的对象,你希望该节点并行计算的数量。在这个例子中,这个 spout 的id是 "words" ,两个bolt的id分别为 "exclaim1" 和 "exclaim2"。
包含处理逻辑的spout对象实现了 IRichSpout 接口,bolt对象实现了 IRichBolt 接口。
最后一个参数,是你希望该节点并行计算的数量是多少,这是可选的。它表明了会有多少线程会通过storm集群来执行这个组件(spout或bolt)。
如果你忽略它,Storm集群会分配单线程给该节点。
setBolt返回一个 InputDeclarer 对象,它用来定义bolt的输入。在这里,bolt
"exclaim1" 声明了它希望通过shuffle分组的方式读取 spout "words"中的所有元组。同理,Bolt "exclaim2"
声明了它希望通过shuffle分组的方式读取 bolt "exclaim1" 所发出的元组数据。
"shuffle 分组" 指元组数据 将会 随机分布地 从输入任务 到bolt任务中。在多个组件(spout或bolt)之间,这里有很多数据分组的方式。
这在接下来的章节中会说明。
如果你希望bolt "exclaim2" 从 spout "words" 和 bolt "exclaim1"
读取所有的元组数据,你需要像下面这样定义:
builder.setBolt("exclaim2", new ExclamationBolt(), 5)
.shuffleGrouping("words")
.shuffleGrouping("exclaim1");如你所见,输入的定义可以是链式的,bolt可以指定多个源。
让我们深入了解一下spout和bolt在topology中的实现。Spout负责发送新的数据到topology中。
TestWordSpout在topology中每隔 100ms
发送了一个随机的单词,单词来自列表["nathan", "mike", "jackson", "golda", "bertels"]。在 TestWordSpout 中的
nextTuple()的实现细节如下:
public void nextTuple() {
Utils.sleep(100);
final String[] words = new String[] {"nathan", "mike", "jackson", "golda", "bertels"};
final Random rand = new Random();
final String word = words[rand.nextInt(words.length)];
_collector.emit(new Values(word));
}如你所见,这个实现非常简单明了。
ExclamationBolt给输入的字符串追加上 "!!!" 。 让我们看一下
ExclamationBolt的完整实现吧:
public static class ExclamationBolt implements IRichBolt {
OutputCollector _collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
_collector = collector;
}
@Override
public void execute(Tuple tuple) {
_collector.emit(tuple, new Values(tuple.getString(0) + "!!!"));
_collector.ack(tuple);
}
@Override
public void cleanup() {
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}prepare方法提供了一个
OutputCollector对象,它用来发出元组数据给下游节点。元组数据可以在任意时间从bolt发出
-- 可以在
prepare,
execute,
或者
cleanup方法,或者
在另一个线程,异步地发送。 这里的
prepare实现很简单,初始化并保存了
OutputCollector的引用,该引用将在接下来的
execute方法中使用。
execute方法从该bolt的输入中接收一个元组数据,
ExclamationBolt对象提取元组中的第一个字段,并追加字符串
"!!!" 。如果你实现的bolt订阅了多个输入源,你可以用 Tuple 中的
Tuple#getSourceComponent方法来获取你当前读取的这个元组数据来自于哪个源。
在
execute方法中,还有一点东西需要说明。
即输入的元组作为第一个参数 发出 ,然后在最后一行中发出确认消息。这是Storm保证可靠性的API的一部分,它保证数据不会丢失,这在之后的教程会说明。
当一个Bolt将要停止、关闭时,它需要关闭当前打开的资源,此时
cleanup方法可以被调用。
需要注意的是,这并不保证这个方法在storm集群中一定会被调用:举例来说,如果机器上的任务爆发,这就不会调用这个方法。
cleanup方法打算用于,当你在 local
mode 上运行你的topology(模拟storm集群的仿真模式), 你能够启动和停止很多topology且不会遭受任何资源泄露的问题。
declareOutputFields方法声明
ExclamationBolt发出一个名称为 "word"
的带一个字段的元组。
getComponentConfiguration方法允许你从很多方面配置这个组件怎样去运行。更多高级的话题,深入的解释,请参见
Configuration.
通常像
cleanup和
getComponentConfiguration方法,在bolt中并不是必须去实现的。你可以用一个更为简洁的方式,通过使用一个提供默认实现的基本类去定义bolt,这也许更为合适一些。
ExclamationBolt可以通过继承
BaseRichBolt,这会更简单一点,就像这样:
public static class ExclamationBolt extends BaseRichBolt {
OutputCollector _collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
_collector = collector;
}
@Override
public void execute(Tuple tuple) {
_collector.emit(tuple, new Values(tuple.getString(0) + "!!!"));
_collector.ack(tuple);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
在local mode上运行ExclamationTopology
让我们来看一下如何在本地模式上运行 ExclamationTopology,看到它工作起来。
Storm有两种操作模式:本地模式和分布式模式。在本地模式中,Storm通过线程模拟工作节点并在一个进程中完成执行。本地模式在用于开发和测试topology时是很有用处的。当你在本地模式中运行 storm-starter 项目中的 topology 时,你就能看到每个组件发送了什么信息。你可以获取更多关于在本地模式上运行topology的信息,请参见 Local
mode。
在分布式模式中,Storm操作的是机器集群。当你提交一个topology给master,你也需要提交运行这个topology所必须的代码。Master将会关注于分发你的代码并分配worker去运行你的topology。如果worker挂掉,master将会重新分配这些代码、topology到其他地方。你可以获取更多关于在分布式模式上运行topology的信息,请参见 Running
topologies on a production cluster。
这是在本地模式上运行
ExclamationTopology的代码:
Config conf = new Config();
conf.setDebug(true);
conf.setNumWorkers(2);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("test", conf, builder.createTopology());
Utils.sleep(10000);
cluster.killTopology("test");
cluster.shutdown();首先,代码中定义了单进程的伪集群,通过创建
LocalCluster对象实现。提交topology到虚拟集群,和提交topology到真正的分布式集群是相同的。提交topology使用
LocalCluster的
submitTopology方法。它需要的参数为
topology的名字,topology的配置,topology本身。
topology的名称是为了标识topology,以便你之后可以停掉它。一个topology将无限期运行,直到你停掉它。
topology的配置可以从多个方面调整topology运行时的形态。这里给出了两个最为常见的配置:
TOPOLOGY_WORKERS (用
setNumWorkers方法来设置)
表明你希望在storm集群中分配多少进程来执行你的topology。每个在topology中的组件(spout 或 bolt)将会被分配多个线程去执行。线程数的设置是通过组件的
setBolt和
setSpout方法。这些线程存在于worker进程中。
每个worker进程包含了处理一些组件的一些线程,例如,你横跨集群指定了300个线程处理所有的组件,且指定了50个worker进程。也就是说,每个工作进程将执行6个线程, 其中的每一个可能又属于不同的组件。调整topology的性能需要通过调整每个组件的并行线程数 和 工作进程中运行的线程数量。
TOPOLOGY_DEBUG (用
setDebug方法来设置), 当设为true的时候,它将告诉Storm打印组件发出的每条信息。这在本地模式测试topology的时候很有用处。但是当你的topology在集群中运行的时候,或许你应该关掉它。
这里有很多其他的topology的配置,更多细节请参见 the Javadoc for Config.
学习如何建立自己的开发环境,以便你能用本地模式运行你的topology(比如在eclipse里),请参见 Creating
a new Storm project.
流的分组方式
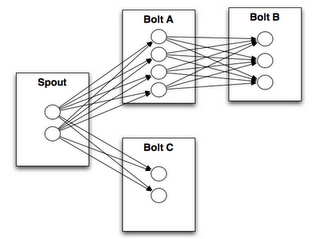
流的分组方式告诉一个topology,两个组件是通过怎样的方式传递元组数据。记住,spout 和 bolt 是并行执行在集群上的多个任务中的。如果你想知道一个topology是如何在任务层执行的,它也许就是这样的:从上图可知,bolt A 有4个task,bolt B有3个task。当bolt A的1个task 发出一个元组给 bolt B,那么bolt A的这个task应该发给bolt B的哪个task呢?
流的分组方式通过告诉storm在两个任务集(上图的 bolt A 的任务集 合 bolt B的任务集)发送元组信息的方式 回答了这个问题。
在我们深入研究不同的流的分组策略前,我们先看一下另一个来自 storm-starter 项目的例子。 WordCountTopology 从spout读取一句话,并分流给
WordCountBolt,并统计句子中每个词儿出现的次数:
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("sentences", new RandomSentenceSpout(), 5);
builder.setBolt("split", new SplitSentence(), 8)
.shuffleGrouping("sentences");
builder.setBolt("count", new WordCount(), 12)
.fieldsGrouping("split", new Fields("word"));SplitSentence发出的元组来自于它接收到的每个句子的每个单词,
WordCount在内存中保留一个map统计单词的次数。每当WordCount
收到一个单词,它将更新map的状态并发出最新的单词统计。
这里有几种不同的流的分组方式。
最简单的分组方式称作 "shuffle grouping" ,这种方式是将元组数据发送给随机的任务。shuffle grouping
用于
WordCountTopology中,
RandomSentenceSpout发送元组数据给
SplitSentencebolt
的部分。它很有效地把元组数组 均匀分给所有的
SplitSentencebolt
的任务。
一个更有趣的分组方式叫做 "fields grouping"。在本例中,字段分组用于
SplitSentencebolt
和
WordCountbolt 之间。它对
WordCount 的功能至关重要,它保证了相同的单词只会去相同的任务中。否则,会有多个任务接收到相同的单词,它们各自发出的单词统计也是不正确的,因为它们获得的都是不全的信息。 fields grouping 让你可以通过字段来进行数据流的分组,这样就导致了相同的字段值会进入到相同的任务中去。
WordCount订阅了
SplitSentence的输出流,并且是通过fields
grouping的方式,本例针对 "word" 字段进行分组, 使相同的单词进入了相同的任务,bolt 就可以给出正确的结果了。
Fields groupings 是 流的连接 和 聚合 的基础实现,它也有其他很多的例子。
在底层, fields groupings 使用 mod hashing 算法来实现的。
这里还有一些其他的分组方式,更多信息请参见 Concepts.
用其他语言定义Bolts
Bolts 可以用任何语言定义。用其他语言写的 Bolts ,是以子进程的方式运行,storm与子进程通信的方式是 通过输入输出 JSON 数据来实现的。通信协议只需要1个100行的适配器代码的库, Storm附带了 Ruby, Python, and Fancy 的适配器的库。这是
SplitSentencebolt 的定义,来自于
WordCountTopology:
public static class SplitSentence extends ShellBolt implements IRichBolt {
public SplitSentence() {
super("python", "splitsentence.py");
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}SplitSentence覆盖
ShellBolt并声明用
python,运行文件为
splitsentence.py.
这是
splitsentence.py的实现:
import storm
class SplitSentenceBolt(storm.BasicBolt):
def process(self, tup):
words = tup.values[0].split(" ")
for word in words:
storm.emit([word])
SplitSentenceBolt().run()更多关于用其他语言编写 spout 和 bolt 的信息,创建topology的信息 (以及完全避免 JVM 的方式), 请参见 Using
non-JVM languages with Storm.
保证消息的处理
本教程前面部分,我们跳过了一些方面如元组是怎么发出的,这些方面涉及了Storm的可靠性的API:Storm是如何保证每条来自于spout的消息会被完全完整地被处理。 参见 Guaranteeingmessage processing 信息看它是如何工作的,以及作为用户的你,如何使用storm的可靠性能的这一优点。
事务型的topologies
Storm 保证每条信息至少被处理一次. 一个大众化的问题被提出: "你怎么在storm顶层上进行计数操作?计数值会不会超量?" Storm 有一个特性称作事务型topologies,在绝大部分的计算场景中,它的实现可以让消息只传递一次。获取更多事务型的topologies的信息: here.
分布式 RPC
本教程介绍了storm顶层的核心流的处理过程。storm原生部分 是有很多的事情可以去做的,其中最有意思的应用就是storm的分布式RPC,它具有很强的并行计算的性能。获取更多的关于分布式RPC的信息: here.
结论
这个教程给出了一个关于storm开发,测试,部署的概览,剩余的文档将深入storm的每个方面。

相关文章推荐
- merge two sorted lists, 合并两个有序序列
- 课堂练习之《哈利波特》
- MySQL错误日志提示innodb_table_stats和innodb_index_stats不存在故障处理
- android路径获取
- 设计模式笔记-Template模式
- Ubuntu 14.04 FTP服务器--vsftpd的安装和配置
- 使用jQuery判断浏览器滚动条位置的方法
- ORA-00845 Raised When Starting Instance (文档 ID465048.1)
- SpringMVC学习系列(1) 之 初识SpringMVC
- android studio SQLite管理备忘
- php+mongodb开发环境搭建(linux+apache+mongodb+php)
- Xcode 快捷键-b
- Android EditText禁止复制粘贴
- redis之(十六)redis的cluster集群环境的搭建,转载
- Maven
- 模拟实现atoi(),字符串循环位移,8bit位指定位的置0或置1
- windows下使用Redis存储
- Android中事件焦点抢占问题
- 最大熵模型介绍及实现
- MPEG2